






目录
一、Meta版本
1. Llama2 申请
1)信息填写:
这一步需要科学上网,最好转到美国,国家也写美国。(试了日本,但到最后一步无法提交。)
2)选择要申请的模型
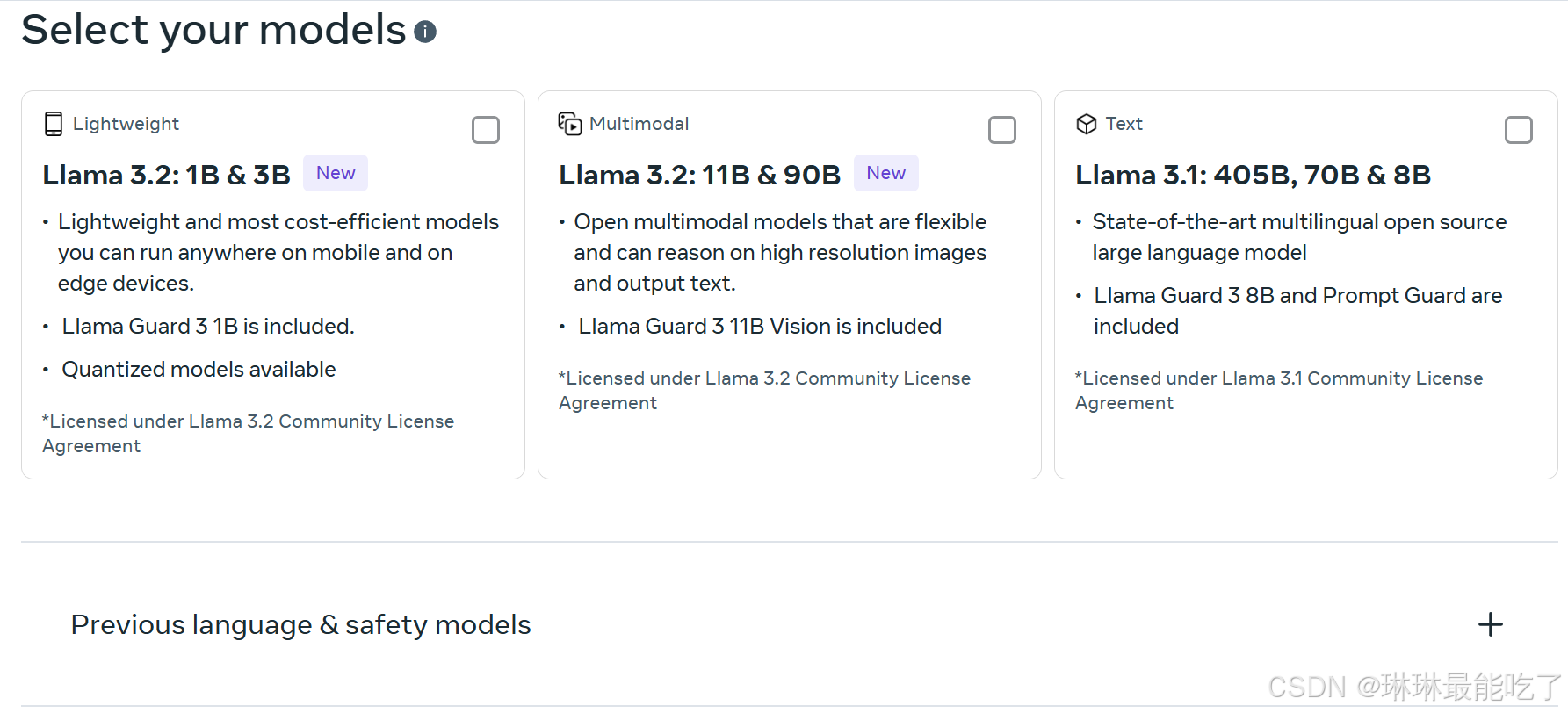
三代之前的模型需要展开“Previous language & safety models”进行选择。
3)方框打对号,点击下一步。

4)文本框滑到最后,方框打对号,点击下一步。等待审核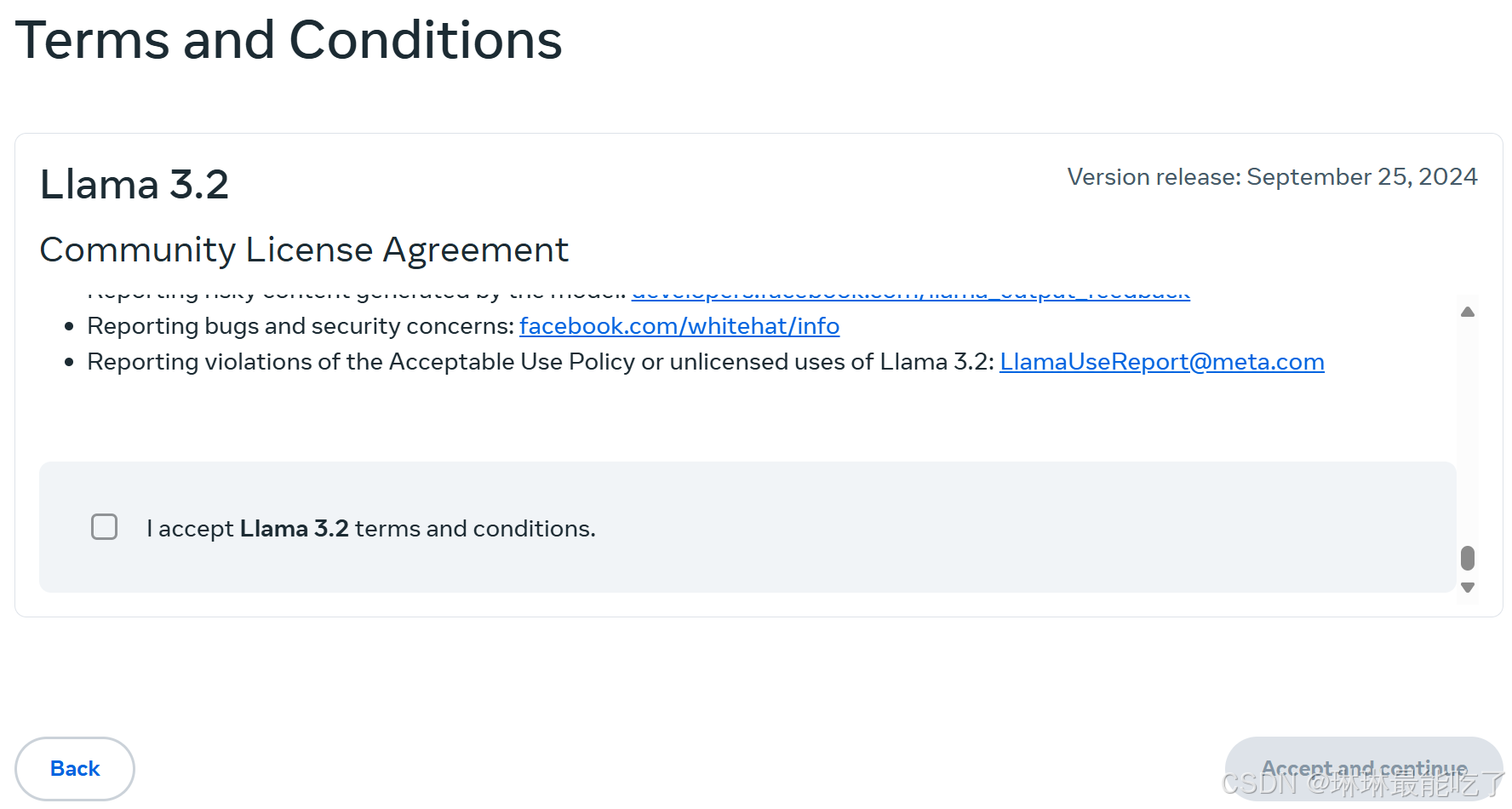
5)审核完毕会将通知邮件发到预留的邮箱,点开链接后会显示申请成功:
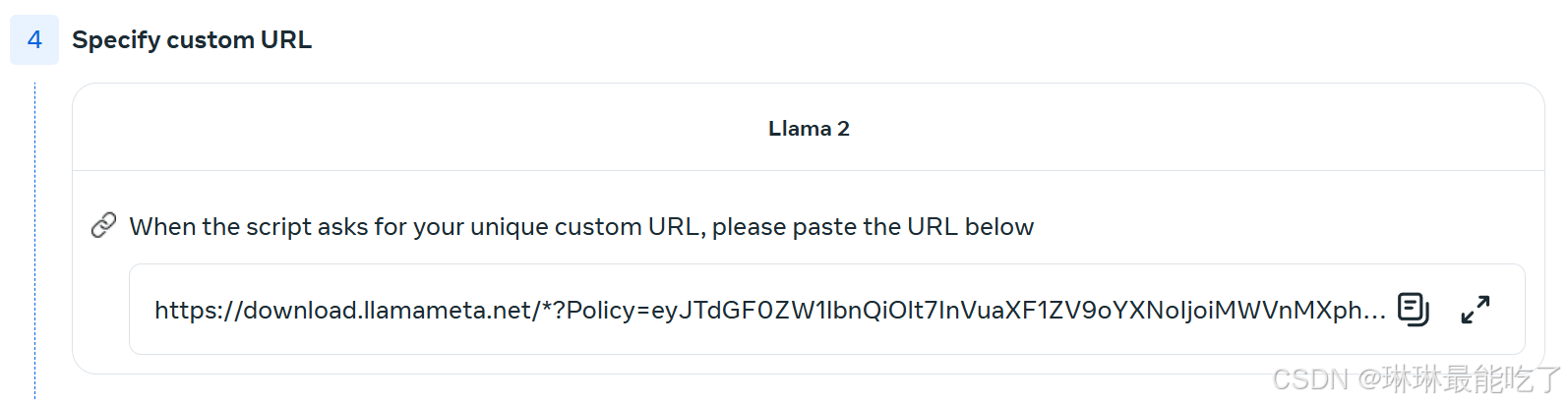
页面的最后会给出url,下载模型时要输入它进行验证。
2. 下载安装Llama
1)准备好环境,在链接中下载压缩包并保存、解压到所需文件夹下。
2)在解压的文件夹下执行命令
pip install -e .
pip install llama-stack$ bash download.sh这时候会让输入url,复制输入即可

接下来选择想下载的模型,输入后回车

接下来就是下载模型并自动打印日志:
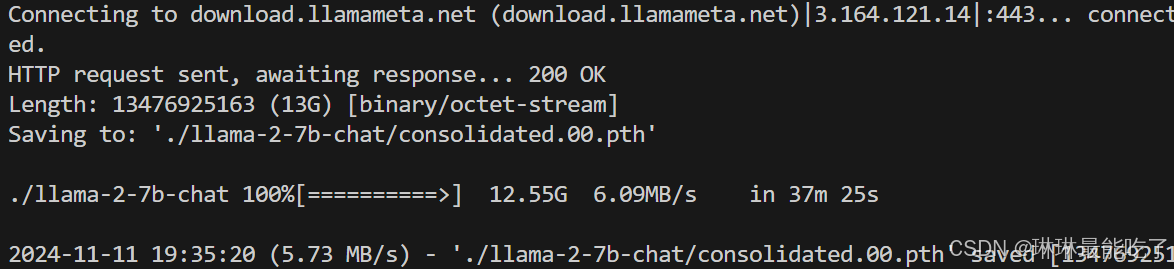
模型的下载过程仍需要科学上网,否则会显示:
Connecting to download.llamameta.net (download.llamameta.net)|54.192.18.67|:443... failed: Connection timed out.如果服务器不方便,可以现在自己电脑上下好,然后传到服务器里。Windows系统可能会报错如下:
![]()
此时需要安装wget工具。
在wget下载链接中根据合适版本下载“EXE”文件,并拖入电脑中的“Git\mingw64\bin”文件夹内,再从bash指令开始运行即可。
所有文件下载完毕后,显示如下:

二、Hugging face 版本
1. 权限申请
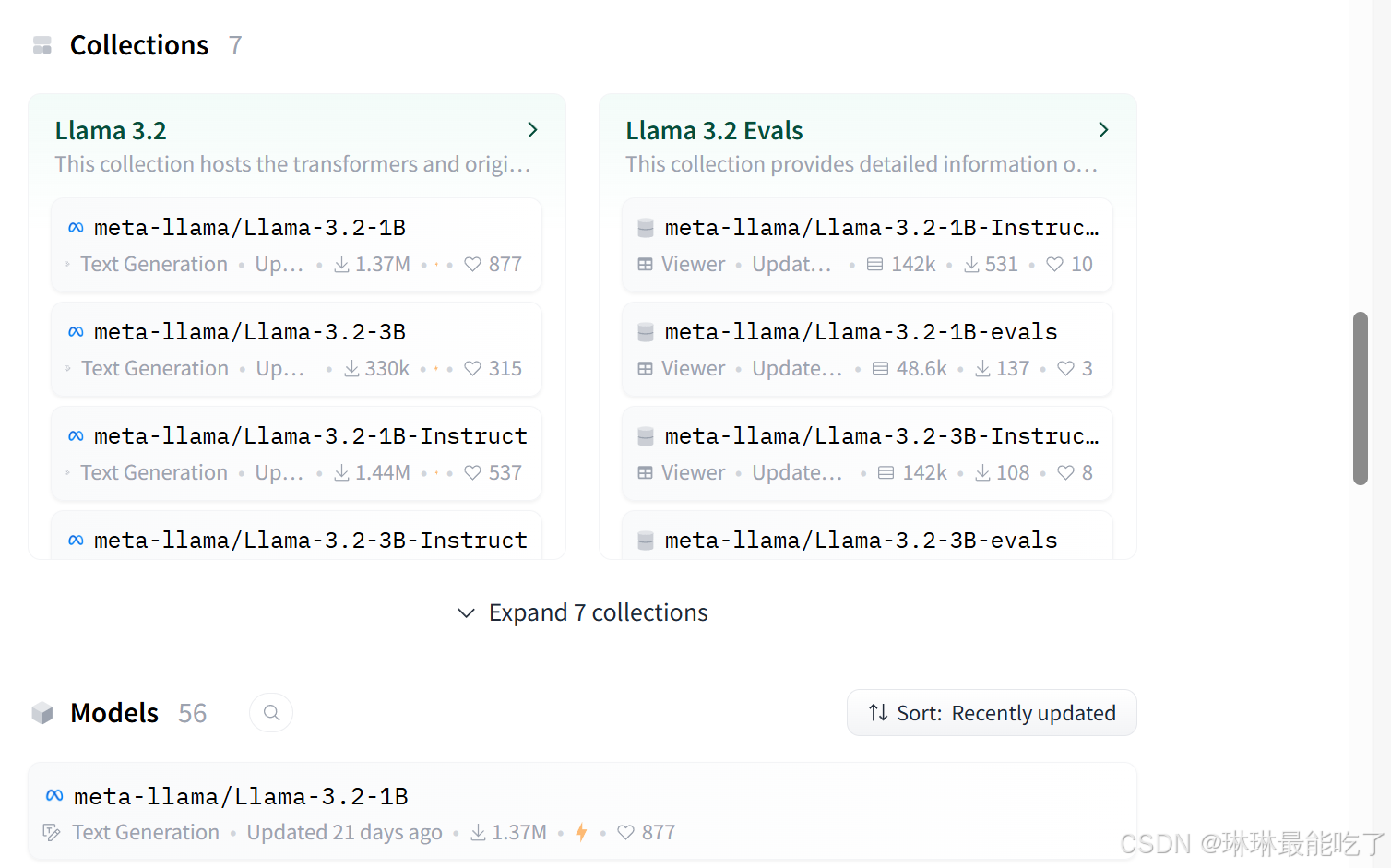
1)模型选择
界面下拉,选择想下载的模型。
2)申请权限
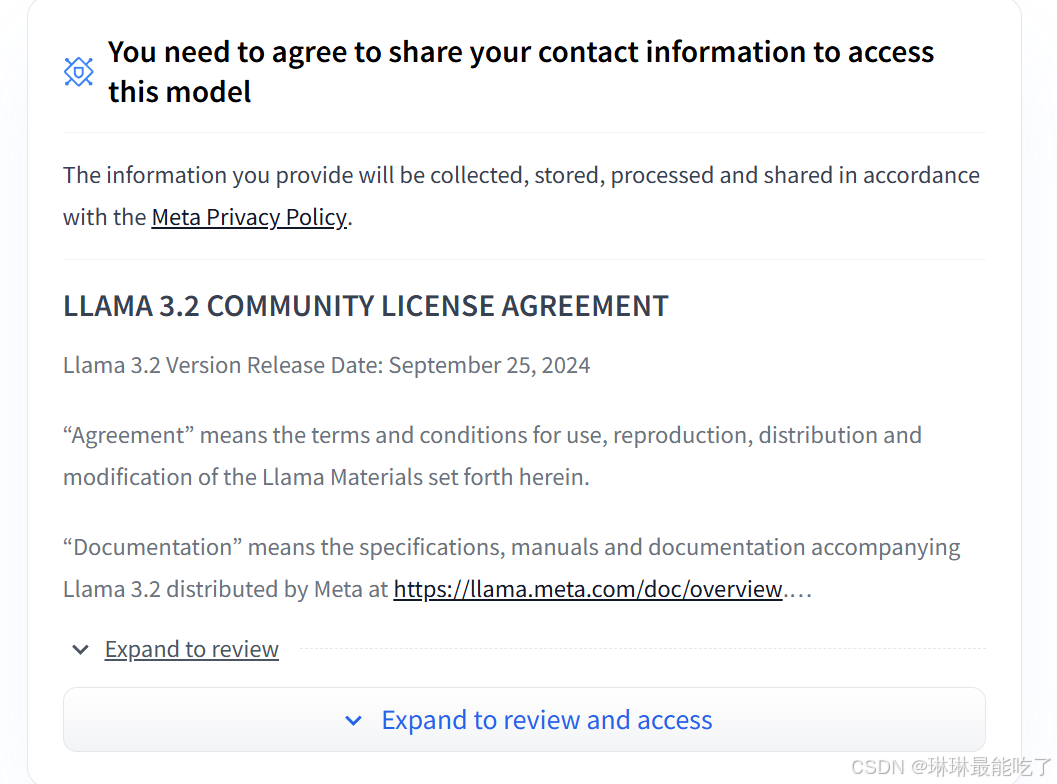
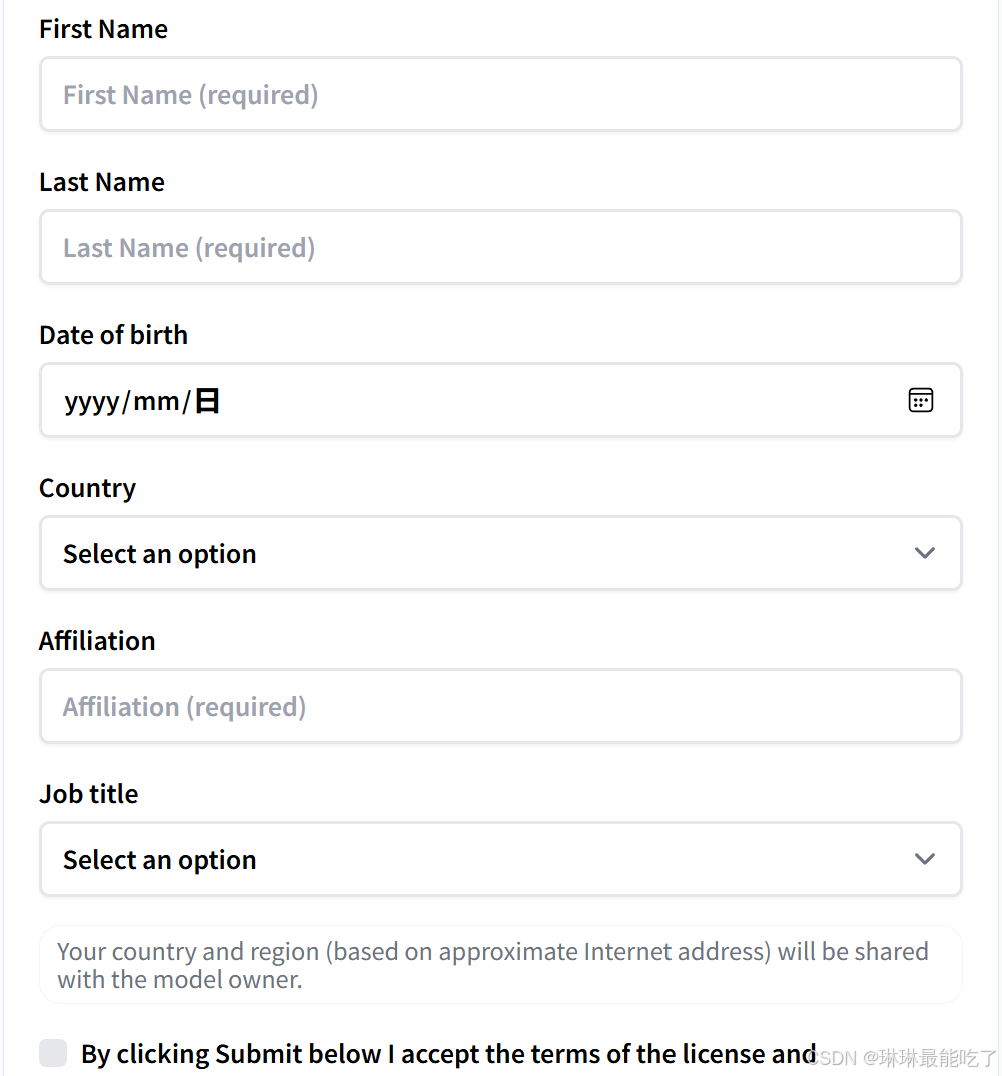
点击“Expand to ...”,填写信息并提交。
这里最好地区也选美国,好像更容易通过。
3)通过后,会收到邮件。点击链接,会跳转到model card界面。
2.模型下载
方法一:如果服务器方便科学上网,可以在终端登录。
1)获取 Access Token.
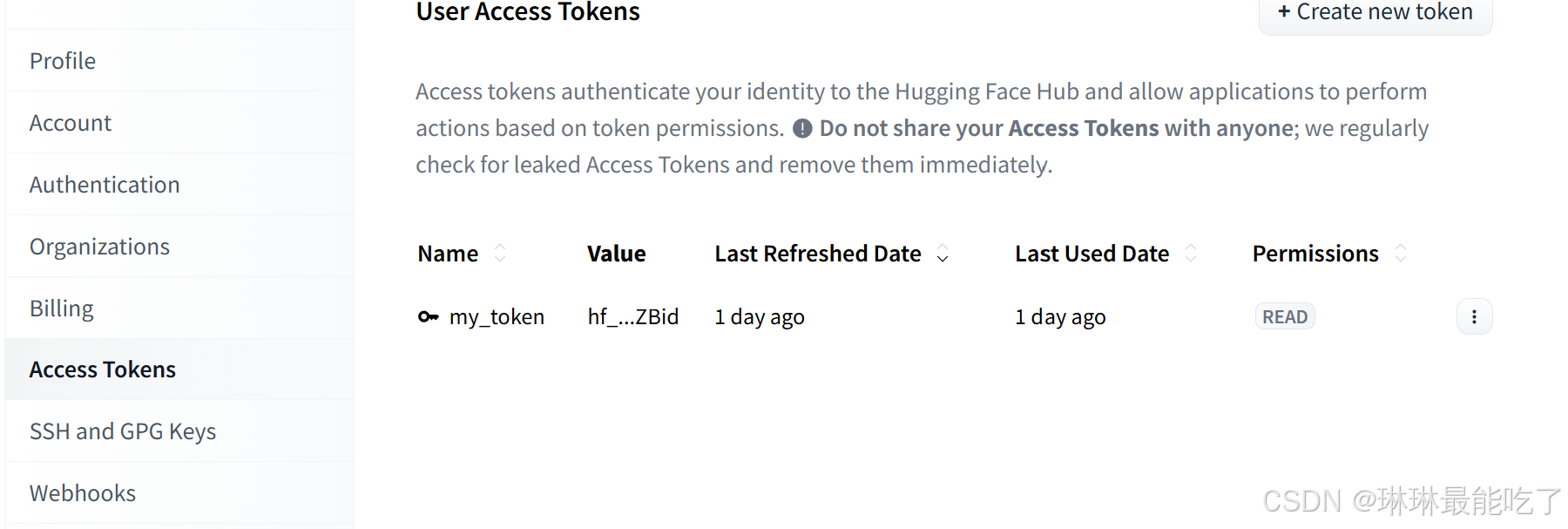
进入hugging face 个人主页,点击settings.
点击“Access Tokens‘,并在右侧界面点击“Create new token”.
2)在服务器的终端中,运行以下命令来登录 Hugging Face 账户
huggingface-cli login输入密钥,即可得到模型的下载权限。
方法二:网页下载到本地,再拖入服务器
在这个界面下载所有文件到本地,即可使用。


















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











