






 文章介绍了ByteSing,一种基于深度学习的中文歌声合成系统,采用Tacotron式声学模型和WaveRNN声码器,通过扩展输入序列和持续时间预测增强模型性能。实验结果表明ByteSing能生成自然且高保真的歌声。
文章介绍了ByteSing,一种基于深度学习的中文歌声合成系统,采用Tacotron式声学模型和WaveRNN声码器,通过扩展输入序列和持续时间预测增强模型性能。实验结果表明ByteSing能生成自然且高保真的歌声。
一,摘要
本文介绍了字节跳动,这是一种基于持续时间分配的类似Tacotron的声学模型和WaveRNN神经声码器的中文歌声合成(SVS)系统。与传统的SVS模型不同,该ByteSing采用类似Tacotron的编码器-解码器结构作为声学模型,其中CBHG模型和循环神经网络(RNN)分别作为编码器和解码器进行探索。同时利用辅助音素持续时间预测模型对输入序列进行扩展,增强模型的可控能力、模型稳定性和速度预测精度。WaveRNN声码器也被采用为神经声码器,以进一步提高合成歌曲的语音质量。客观和主观实验结果表明,本文提出的SVS方法通过提高音高和频谱图预测精度,可以产生相当自然、富有表现力和高保真度的歌曲,并且使用注意力机制的模型可以达到最佳效果。
1.1 引言
歌唱语音合成(SVS)系统可以从给定的乐谱中生成歌曲,其中包含语言信息(歌词)和不同类型的音乐特征,例如音符和速度信息。目前,SVS技术是虚拟化身、语音助手、智能电子设备等各种人机交互应用中不可或缺的基础组件。同时,SVS系统可以与其他生成任务相结合,例如自动生成歌词和旋律。多模态技术的集合,人工智能歌手和人工智能作曲家越来越受欢迎。因此,未来对高保真、高自然度和更精确的SVS算法的期望将会增加。
与仅依赖于语言输入特征的文本到语音(TTS)合成系统类似,SVS系统通常采用与统计参数语音合成(SPSS)系统类似的声学和持续时间模型。一些传统的统计模型,如上下文相关的隐马尔可夫模型[1,2]被用于许多流行的SVS系统,可以同时模拟歌声的几个声学特征。然而,由于这些统计模型的过度平滑效应和有限的建模能力,这些系统预测的音色和和声等音乐特征与从真实歌曲中提取的音乐特征有很大区别。
近年来,深度学习技术在TTS、语音转换和语音增强等各种语音和音频生成任务[3]上取得了巨大的成功。除了TTS系统之外,还提出了基于神经网络的SVS系统的不同模型。采用深度神经网络(DNN)和卷积神经网络(CNN)对乐谱与声学特征之间的映射关系进行建模[4,5,6]。SVS系统还采用了具有长短期记忆(LSTM)细胞的RNN,以捕获长程时间依赖性并产生更高的歌唱质量[7]。
使用基于内容的注意力机制的序列到序列模型,如Tacotrons [8,9]和Deep Voice 3 [10],目前是端到端TTS的主要范式,它们已经证明了可以与人类语音相媲美的自然性。还提出了一些用于端到端SVS的编码器-解码器结构[11,12],并采用了对抗训练来提高预测特征的准确性[12]。尽管端到端模型在TTS和SVS任务上取得了这些成功,但这些方法通常缺乏对齐过程的鲁棒性,导致重复或跳过单词以及不完整的合成。与传统端到端模型中的自动和软注意力对齐不同,使用了一些额外的持续时间预测器来解决错误注意力对齐的问题,从而降低缺失或重复单词的比例[13,14]。类似的持续时间知情注意力网络也应用于SVS和歌唱转换任务[15,16],以确保音素和乐谱序列之间的硬对齐及其相应的声学特征。此外,波形建模算法,如WaveNet [17],WaveRNN [18]和WaveGlow [19]已经实现了高保真音频质量和接近人类的感知,并且还用于SVS系统[20]。
基于基于持续时间信息编码器-解码器架构的声学模型在音频生成任务中取得的成果,我们提出了一种中文SVS系统ByteSing,通过端到端结构和辅助音素持续时间预测模型,从原始乐谱和歌词中合成人声波形。与上述歌唱合成系统[15,16]不同,该SVS系统主要依赖于语言特征和基频(F0)轨迹,而SVS系统则处理语言和音乐特征的嵌入。此外,这些系统仍然依赖于传统的DSP声码器和源滤波器模型,难以从歌声中提取准确的特征,并且存在生成高质量波形的缺点。因此,所提出的ByteSing模型利用自回归解码器将持续时间扩展的输入特征直接转换为频谱图序列,其中包含更详细的以及更丰富的声学信息。音素持续时间信息也被预测为提高模型稳定性和合成歌曲的速度准确性。此外,采用WaveRNN作为声码器直接合成波形,超越了传统声码器的局限性。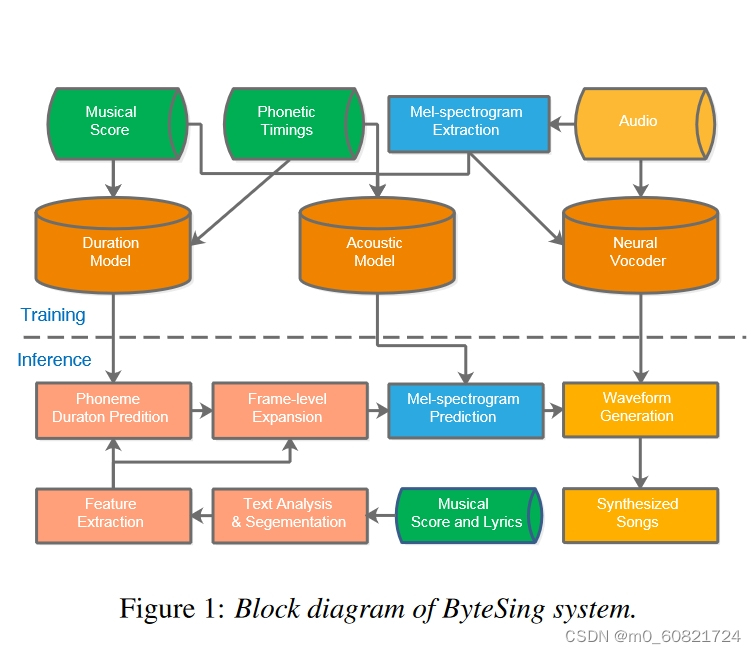
二,训练阶段
1. Duration models
- 持续时间模型使用语言和音乐信息预测每个音素的开始和结束时间,并根据音符持续时间的限制进行后处理步骤。
- 根据相邻音素的间隔信息,将音符级特征转换为帧级特征。
2. Acoustic models
- 建立声学模型,将扩展的帧级输入特征序列映射到提取的声学特征序列中。与其他明确选择 F0s 和频谱包络相关特征作为声学特征的 SVS 系统不同,隐式包含所有声学元素(如音高和格式)的 80 维 mel-频谱图可以直接预测。
- 编码器: Tacotron [8],强大的CBHG模
- 利用基于GMM的注意力机制[22,23]将输入的音乐和语言特征与输出频谱图对齐
- 解码器遵循Tacotron2 [9
3. WaveRNN neural vocoder
- 同时,使用录制的歌曲和从相应的真实波形中提取的mel频谱图构建基于WaveRNN的神经声码器。
- 包含一个样本生成网络和一个条件网络
三,推理阶段
1. 首先对乐谱歌词执行一些标准的文本分析程序,例如多音消歧,以推断歌词的音素序列。
2. 为了便于建模,长段落也被分割成短句。
3. 给定音素序列及其乐谱,音素持续时间由持续时间模型预测。
4. 帧级扩展特征序列被馈送到编码器中。然后解码器在自回归中逐帧生成 mel 频谱图序列方式。
5. 经过训练的神经声码器可以将预测的 mel 频谱图转换为歌唱波形。字节星系统上各部分的详细信息描述如下。
四, 特征表示
- 持续时间模型中的输入特征 XD = [Ph, Tp, Du] 是音素级别的特征,其中 Ph 和 Tp 都是分类特征和独热编码,Du 是当前音素所属音符的理论数值持续时间。Du可以根据速度信息和音符持续时间信息获得。
- 对于声学模型,持续时间扩展特征 XA = [Ph, Pi, Po] 是帧级特征,其中 Pi 也是分类特征,而不是浮点频率值。Po 是一个额外的三维位置嵌入,计算为斜坡,表示每个音素的每个帧的音素的前进和保留百分比,以及每个音素的当前话语位置,它们都规范化为区间 [0,1] 中的浮点数。
五,Duration models
与TTS任务的持续时间仅取决于特定说话者的文本上下文和韵律字符不同,演唱的持续时间也应指自由度低于TTS的音乐持续时间。在SVS的情况下,应更准确地确定每个音素的开始时间和结束时间。因此,利用包含多层LSTM单元的双向RNN作为持续时间模型,从输入音素级XD特征序列预测目标音素的持续时间。然后,通过时间监督反向传播算法对最小均方误差(MMSE)准则下的RNN参数进行微调。
尽管乐谱的开始时序和实际歌曲中真实音频的开始时序之间的时间滞后现象很常见,但字节点数上没有使用时滞模型[1]。相反,为了简化程序和方便音频与背景音乐混合,对预测的音素持续时间执行后处理步骤,以将整个音节持续时间限制为等于相应的音符持续时间。事实上,只保留了每个音节中元音和辅音比例的自由度,这是对自然性和真实性的妥协。虽然乐谱被严格遵循,这与练习情况不一致,但自然度并没有因大致的主观感知而显着下降,合成的歌曲更容易交付到后期制作中,例如自动混音和自动调谐。
总结:本文的Duration models是利用多层LSTM单元的双向RNN作为持续时间模型,从输入音素级XD特征序列预测目标音素的持续时间,然后通过时间监督反向传播算法对最小均方误差(MMSE)准则下的RNN参数进行微调。本文的Duration models在严格遵循乐谱的条件下,歌曲的自然度并没有做出妥协。再者,尽管在实际歌曲中,乐谱的起始时间与真实音频的起始时间之间存在时间差的现象是相当普遍的,但在ByteSing上却没有使用时间差模型。
六,Acoustic models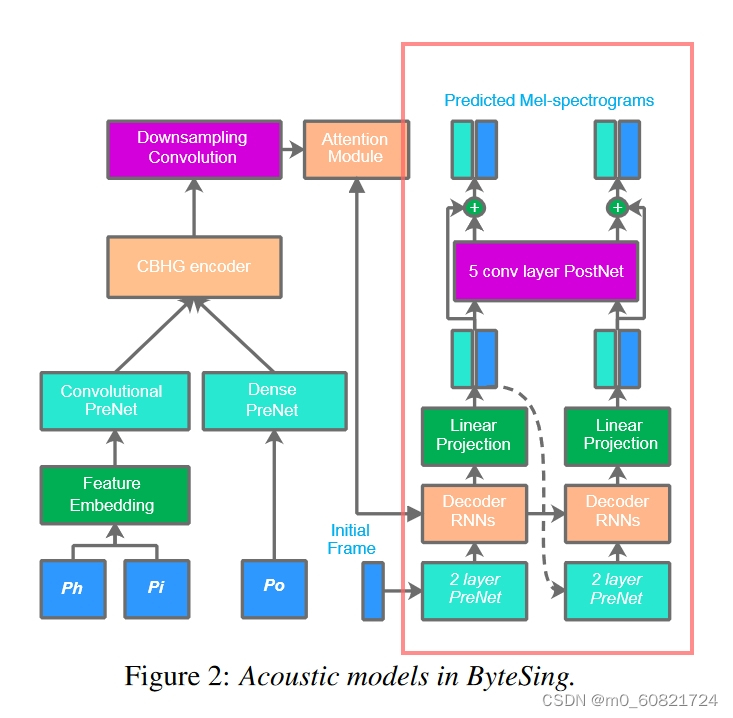
- 声学模型是从Tacotron and Tacotron2.演变来的,在输入Duration models扩张到帧级的XA,然后用卷积PreNet来模拟语言和音乐上下文的长期信息。
- 继承自Tacotron [8],强大的CBHG模块由一组卷积滤波器,高速公路网络和基于双向门控循环单元的RNN组成,也用作从输入序列中提取表示的编码器。
- 然后通过卷积层对编码序列进行下采样,使其与输出声学特征序列的时间分辨率相同。
- 利用基于GMM的注意力机制[22,23]将输入的音乐和语言特征与输出频谱图对齐。
- 由于输入序列通过辅助持续时间模型进行扩展,注意力模块可以实现快速收敛,并且还可以保证合成比对的单调性和局部性。
- 同时,由于注意力策略和编码器-解码器结构,自动学习源与目标之间的对齐,并由动态上下文向量控制,具有传统SPSS和SVS系统中硬对齐的优势。
- ByteSing的解码器遵循Tacotron2 [9]的解码器设计,自回归RNN一次预测编码输入序列中多帧的mel频谱图。
- 来自前一个时间步骤的声学预测首先通过包含2个全连接层的预网。来自解码器网络的输出声学特征序列通过卷积后网络来预测残差。
- 计算后网前后的损耗,以优化整个声学模型。
七,WaveRNN neural vocoder
WaveRNN [18] 是一个生成模型,被提议用于 TTS 合成和其他通用音频生成任务。WaveRNN使用GRU变体而不是依赖于声码器进行自回归语音样本生成,声码器依次预测音频样本的粗细部分。ByteSing中被利用的WaveRNN的架构是如图所示,它包含一个样本生成网络和一个条件网络。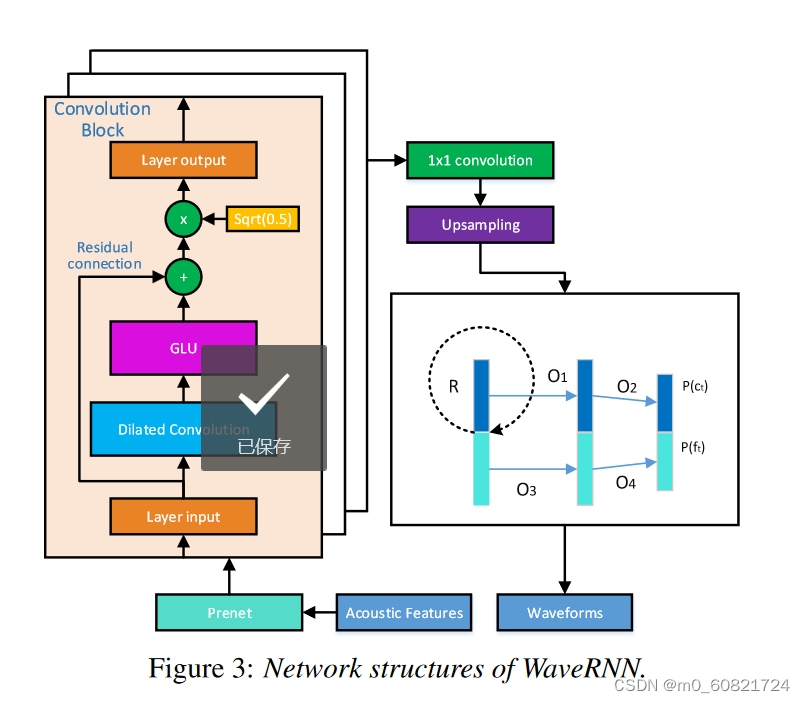
- 对于样本生成部分,基本上遵循原始结构,使用具有双softmax输出层的单层RNN来预测以预测的mel频谱图为条件的音频样本的分类分布。
- 图所示的多层卷积块用于编码帧级mel-频谱图条件序列,这是由Deep Voice 3上的编码器结构驱动的[10]。
- 卷积块由一维卷积层、作为可学习非线性的门控线性单元 (GLU) [24]、与输入的残差连接和 √0.5 的比例因子组成。
- 具有指数增加膨胀因子的堆叠非因果卷积层可以产生足够大的感受野,并且 GLU 可以缓解堆叠卷积块的梯度消失问题,同时保持非线性。
- 通过简单的重复,编码信息被上采样到具有本地音频的相同时间分辨率,然后添加到GRU单元的偏差中。
八,实验部分
九,结论
本文介绍了所提出的字节星系统,该系统采用类似Tacotron的声学模型和神经声码器。频谱图是利用编码器-解码器结构和注意力模块直接预测的。WaveRNN用作声码器,直接合成波形,超越传统声码器的局限性。采用持续时间模型来提高鲁棒性、准确性和可控性。受试者测试表明,字节跳动可以达到人类80%以上的歌唱水平。字节跳动是我们第一次尝试歌唱合成任务。在未来的工作中,将在我们的字节星系统上探索更多的训练和优化策略,例如多歌手预训练和数据增强。还将为SVS在线服务开发一个更加自动化的过程,包括自动标记,音高校正和一些多模态方法。

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









