






摘要
本文工作:
我们研究了判别训练深度卷积网络(ConvNets)的结构,用于视频中的动作识别。难点在于如何从静止帧和帧之间的运动中获取图像外观的互补信息。我们还致力于在数据驱动的学习框架中概括表现最好的手工特征。
本文贡献:
1.我们提出了一种融合时空网络的双流卷积神经网络架构。
2.我们证明了在训练数据有限的情况下,在多帧密集光流上训练的卷积神经网络能够获得非常好的性能。
3.我们证明了将多任务学习应用于两个不同的动作分类数据集,可以用来增加训练数据量并提高两者的性能。
1 介绍
与静止图像分类相比,视频的时间成分为识别提供了额外的(和重要的)线索,因为可以根据运动信息可靠地识别许多动作。此外,视频为单个图像(视频帧)分类提供了自然的数据增强(抖动)。
我们的目标是将深度卷积网络(ConvNets)[19](一种最先进的静态图像表示[15])扩展到视频数据中的动作识别。
问题:这项任务最近在[14]中通过使用堆叠视频帧作为网络的输入来解决,但是结果明显比那些最好的手工制作的浅表示[20,26]差。
解决:我们研究了一种基于两个独立的识别流(空间和时间)的不同架构,然后通过后期融合将它们结合起来。
空间流从静止的视频帧中执行动作识别,而时间流被训练以密集光流的形式从运动中识别动作。
1.1相关工作
传统的手工特征:一大类视频动作识别方法是基于局部时空特征的浅层高维编码。在后来的工作[28]中,表明局部特征的密集采样优于稀疏的兴趣点。在基于轨迹的管道中,运动边界直方图(MBH)达到了最佳性能[8],这是一种基于梯度的特征,分别在光流的水平和垂直分量上计算。
之前用深度神经网络做视频理解的工作:输入:一堆连续的视频帧,因此模型被期望隐式地学习第一层的时空运动相关特征
本文:我们的时间流ConvNet在多帧密集光流上运行,通常通过求解位移场(通常在多个图像尺度上)在能量最小化框架中计算。
2 视频识别的双流架构
空间部分:以单独的帧外观的形式,承载着视频中所描绘的场景和物体的信息。
时间部分,以帧间运动的形式,传达观察者(摄像机)和物体的运动。

3 光流神经网络
3.1 ConvNet输入配置
输入:在几个连续帧之间叠加光流位移场形成的。这样的输入明确地描述了视频帧之间的运动,这使得识别更容易。
时间流的输入是光流,那么就存在以下问题:
1.怎么抽取光流
答:通过某种算法,光流可视化:人的动作朝这个方向走,反应了图像变化的梯度。得到水平位移和垂直方向的位移,把这两个位移相加,得到光流图。

2.怎么预处理光流
答:光流叠加

有两种光流叠加的方法:
1简单直白的光流叠加
每个光流图都去问这个点下一帧往哪里走了
上一张图p1移动到了p2,在p2找它的下一帧对应的位置。
3光流的输入维度
4 多任务学习
空间流卷积神经网络可以在大型静止图像分类数据集(如ImageNet)上进行预训练,而时间流卷积神经网络需要在视频数据上进行训练.
训练是在UCF-101和hdbb -51数据集上进行的,它们分别只有9.5K和3.7K视频。为了减少过度拟合,可以考虑将两个数据集合并为一个。
5 实现细节
ConvNets configuration.:
时间流:所有隐藏权重层都使用整流(ReLU)激活函数;Maxpooling在3×3空间窗口上执行,步幅为2;本地响应归一化使用与[15]相同的设置。
训练:在空间网络训练中,从选定的帧中随机裁剪出224 × 224的子图像;然后它会经历随机水平翻转和RGB抖动。视频是预先重新缩放的,所以帧的最小边等于256。我们注意到,与[15]不同的是,子图像从整个帧采样,而不仅仅是其256 × 256的中心。
测试:给定一个视频,我们采我们从每个帧中获得10个ConvNet输入[15]。然后通过对采样帧和其中的作物的平均分数来获得整个视频的类分数。样固定数量的帧(在我们的实验中是25帧),它们之间的时间间隔相等。
6 评价
数据集:估是在UCF-101[24]和hdbb -51[16]动作识别基准上进行的
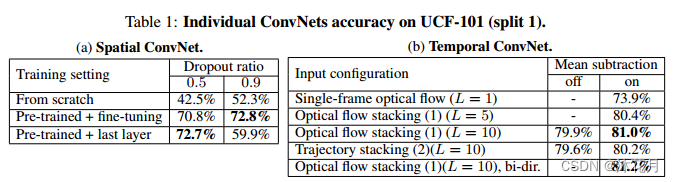
分别做了空间流和时间流的消融实验
空间:有没有用预训练网络,整个网络做微调整个网络微调。
时间:简单的堆叠还是依照轨迹进行堆叠好
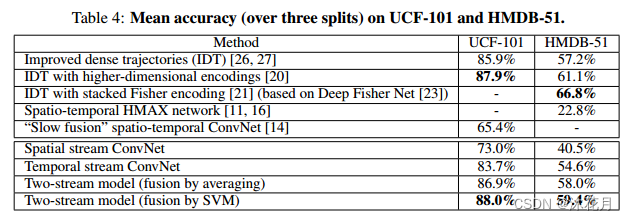
1,2,3:手工特征
4,5:之前用深度学习做分类
6,7,8,9:双流网络
7 结论
提出了一种基于卷积神经网络的具有竞争力的深度视频分类模型,该模型融合了独立的时空识别流















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









