







深度学习:算法到实战笔记02——神经网络基础
绪论剩余内容补充
深度学习应用研究:视觉+语言
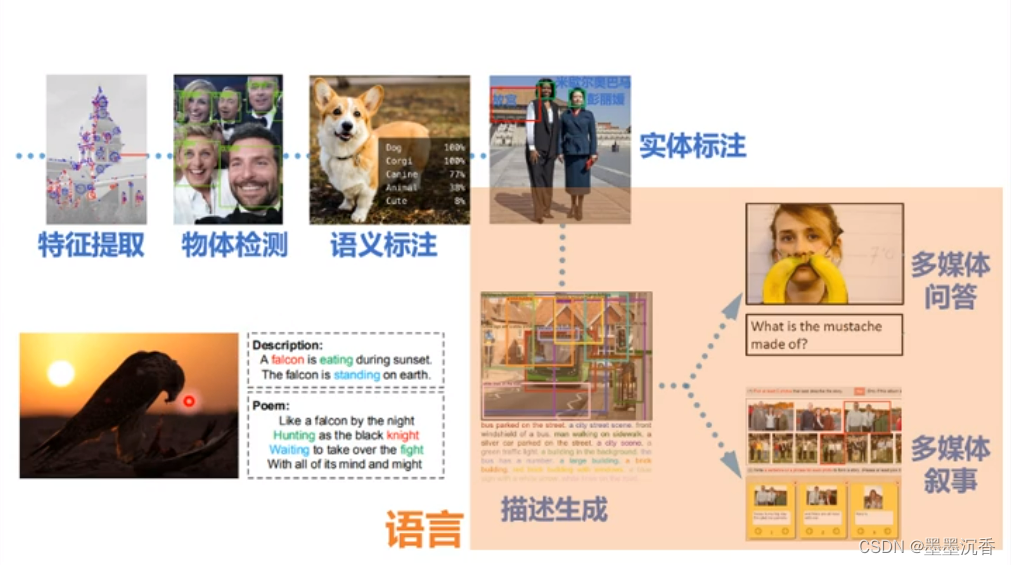
随着深度学习的应用拓展,从深度学习“能”做什么,发展到思考深度学习“不能”做什么。
深度学习的“不能”
(1)算法输出不稳定,容易被“攻击”
(2)模型复杂度高,难以纠错和调试
(3)模型层级复合程度高,参数不透明
(4)端对端训练方式对数据依赖性强,模型增量性差(当样本数据量小的时候,深度学习无法体现强大拟合能力)
(5)专注直观感知类问题,对开放性推理问题无能为力
(6)人类知识无法有效引入进行监督,机器偏见难以避免(从真实社会中抽取的数据必然带有社会固有的不平等、排斥和歧视)
对应解释性的三个层次
找得到、看得懂、留得下
解释性VS泛化性

深度学习拥有很高得准确性但是解释性很低
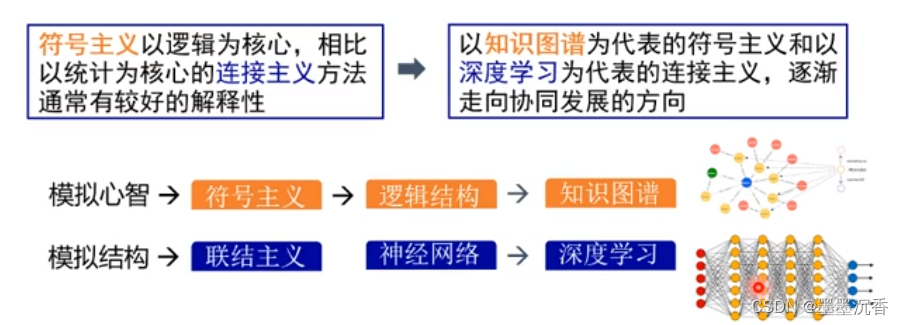
连接主义VS符号主义:从对立到合作
连接主义+符号主义
从专家系统、统计机器学习到概率图模型再到深度学习,模型准确率不断提高,解释性却没有提高
神经网络基础
浅层神经网络
神经网络最早是受生物学启发
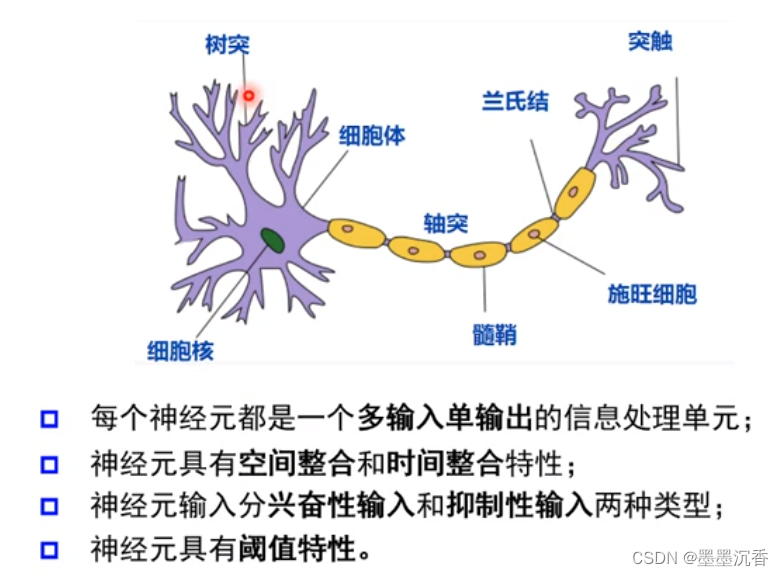
M-P神经元
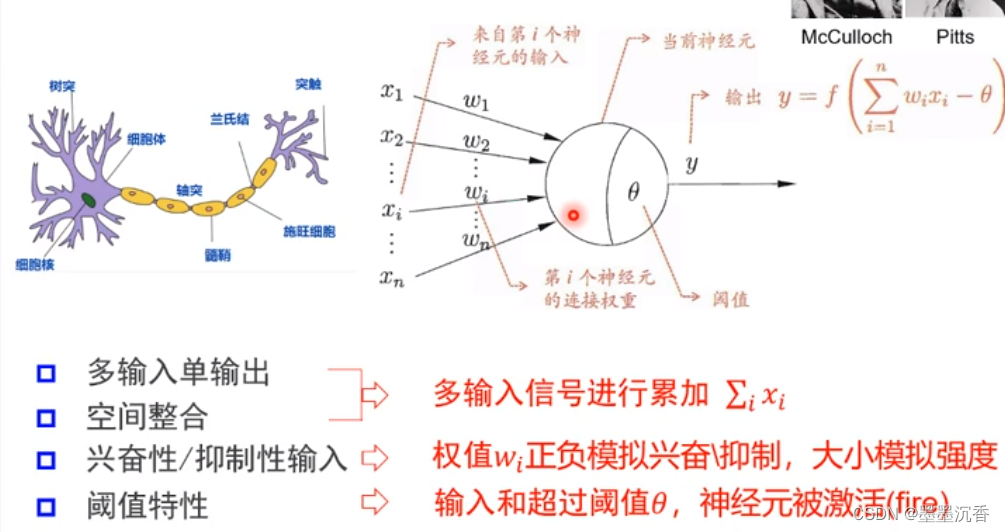
其中令W0=-θ,x0=1可以使除f外部分简化为
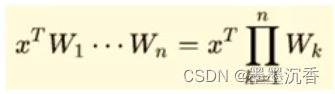
激活函数f
神经元继续传递信息、产生新连接的概率(超过阈值被激活,但不一定传递)
没有激活函数相当于矩阵相乘,只能拟合线性函数
激活函数举例
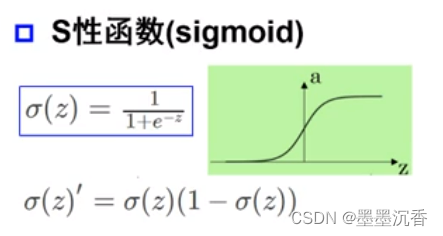
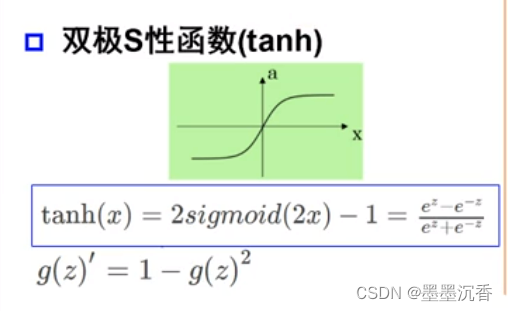
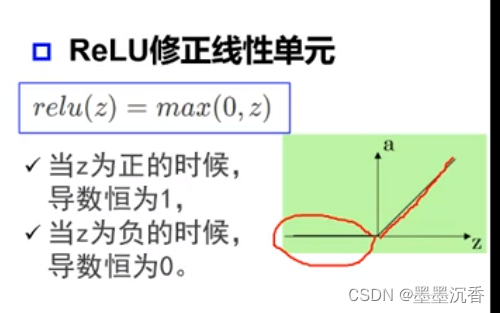

单层感知器
M-P神经元的权重预先设置,无法学习
单层感知器是首个可以学习的人工神经网络
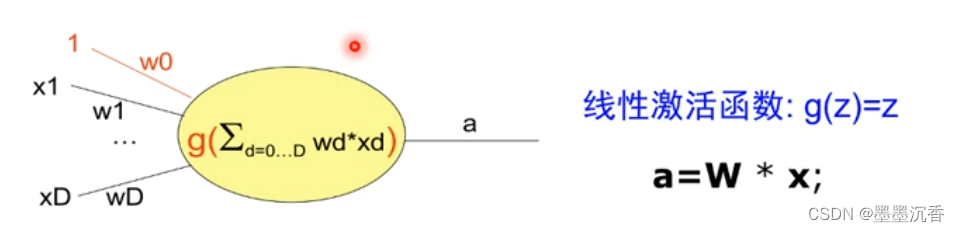
虽然和M-P神经元基本一致,但是感知器中W矩阵可以自动学习。
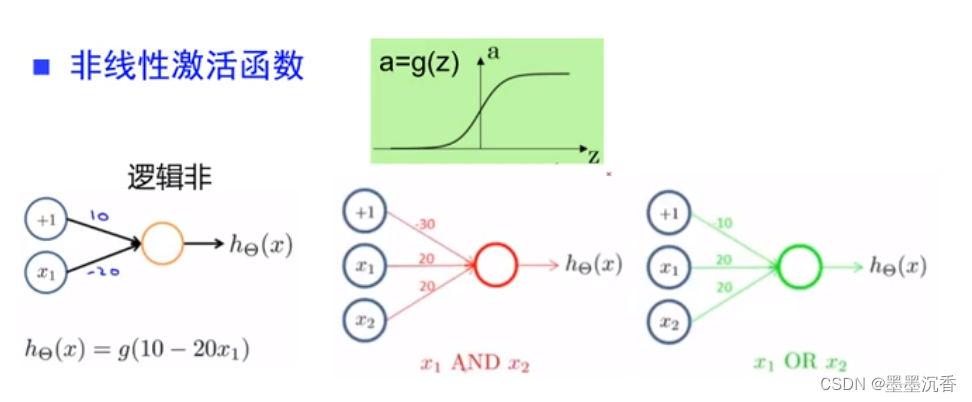
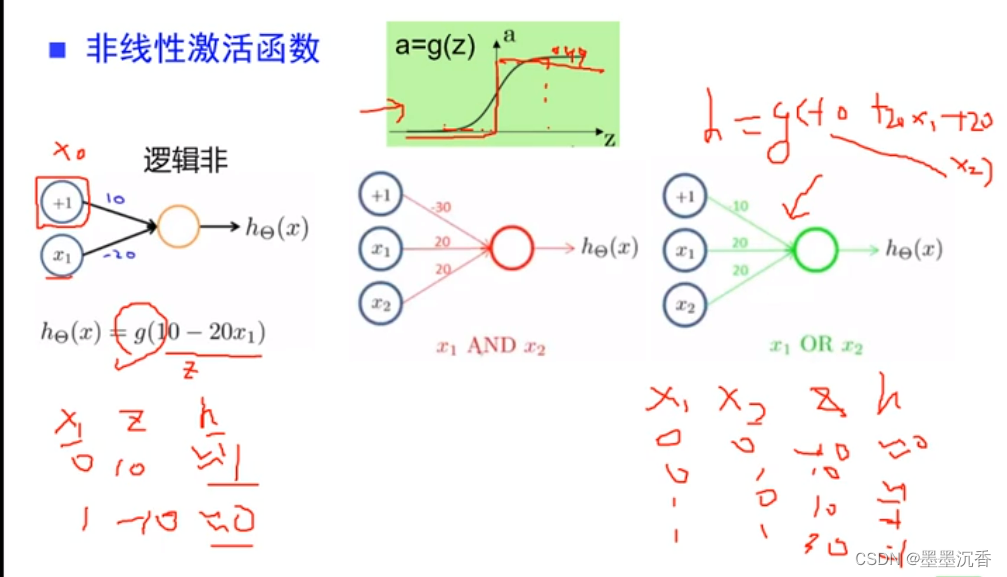
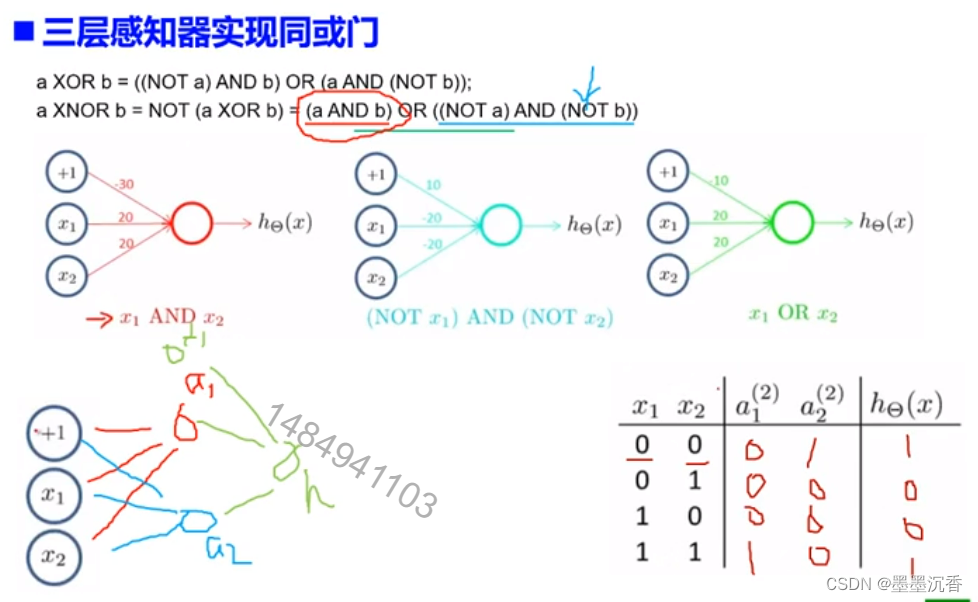
相当于在二维空间画了一个分解面(以上图x1 AND x2为例)
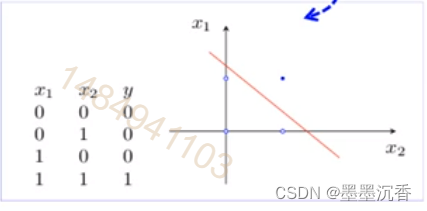
分界面之上的输出1
分界面之下的输出0
单层→多层感知器
单层感知器无法实现异或等复杂的逻辑问题
复杂的逻辑问题可以由多个与非或门实现
一个神经网络可视化的demo
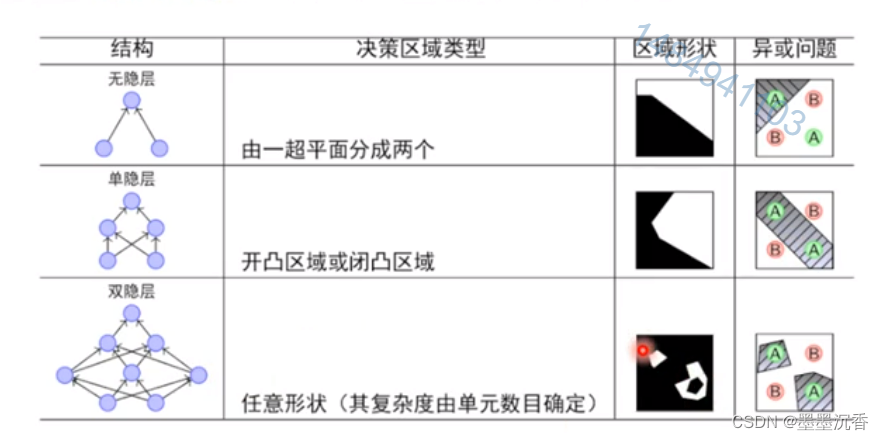
万有逼近定理
万有逼近定理
如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。
为什么线性分类任务组合后可以解决非线性分类任务?
其实是通过空间变换将非线性分布转变为线性分布
双隐层感知器逼近非连续函数
当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数:可以解决任何复杂的分类问题。
神经网络每一层的作用
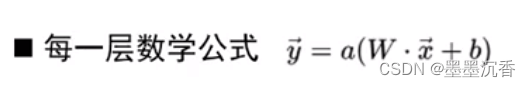
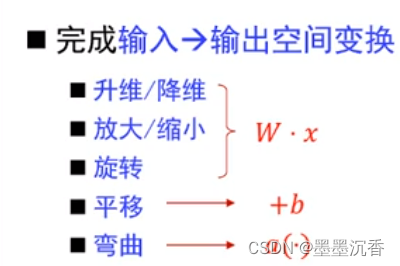
神经网络学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投影到线性可分的空间去分类/回归。
增加节点数:增加维度,即增加线性转换能力。
增加层数:增加激活函数的次数,即增加非线性转换次数。
多层神经网络的问题:梯度消失
神经网络的参数学习:误差反向传播

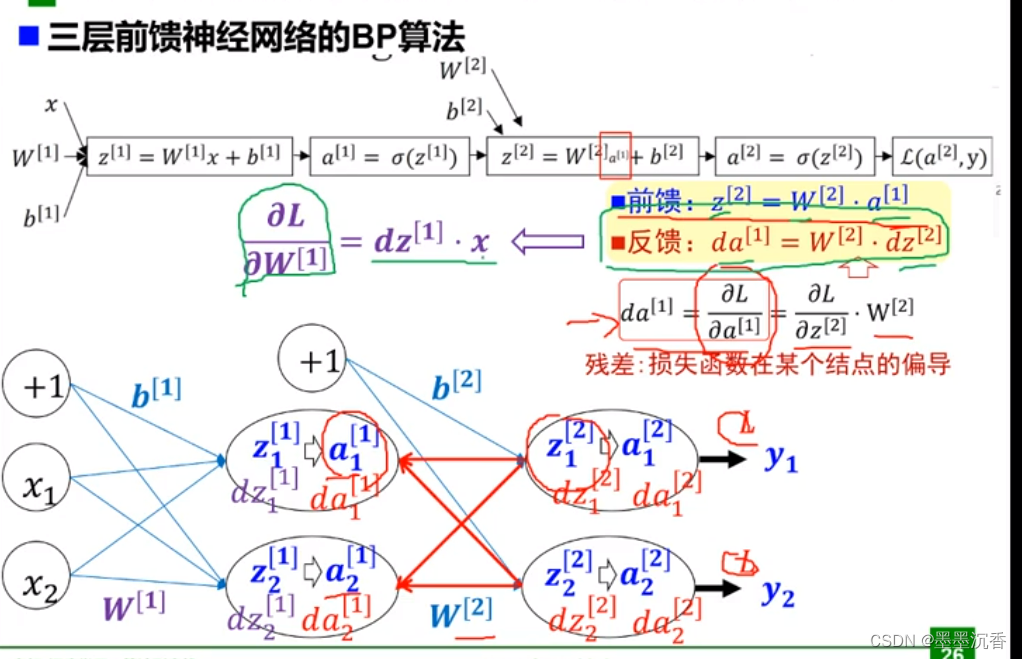
梯度和梯度下降
梯度
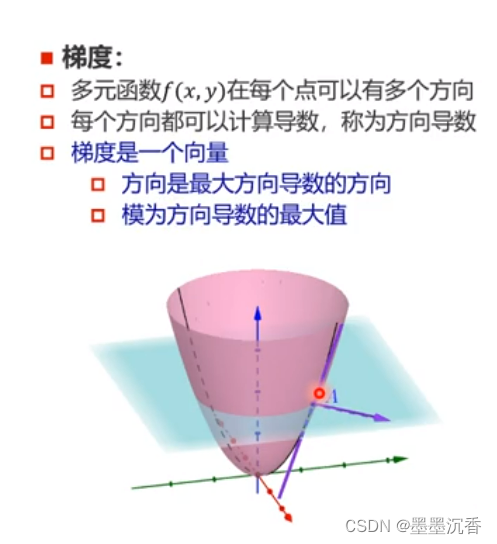
无约束优化:梯度下降
参数沿负梯度方向更新可以使函数值下降。
梯度消失
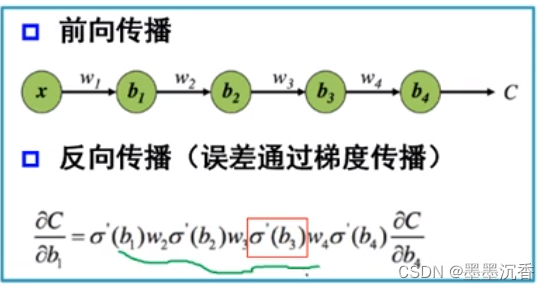
当激活函数的导数的值很小时,梯度值可能过小导致消失现象。
增加深度会造成梯度消失,误差无法传播(三层神经网络是主流);
多层网络容易陷入局部极值,难以训练(预训练、新激活函数使深度成为可能)。
深度学习
逐层预训练
对参数初始化使得训练模型获得很好的初始值
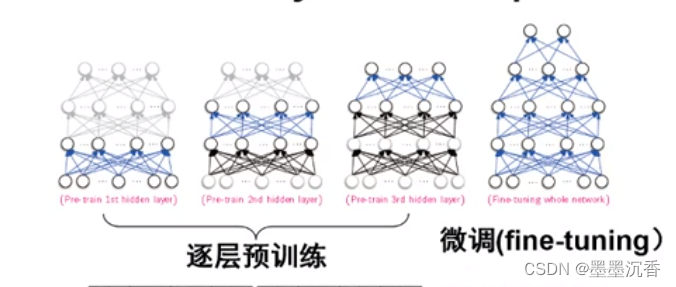
微调的效果很有限,主要依靠逐层预训练
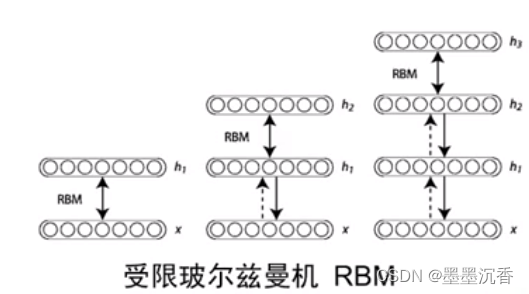
受限玻尔兹曼机和自编码器
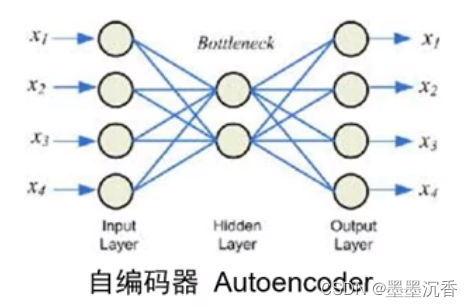
自编码器
自编码器假设输出与输入相同,是一种尽可能复现输入信号的神经网络,没有额外监督信息。
自编码器一般是一个多层神经网络(最简单:三层):
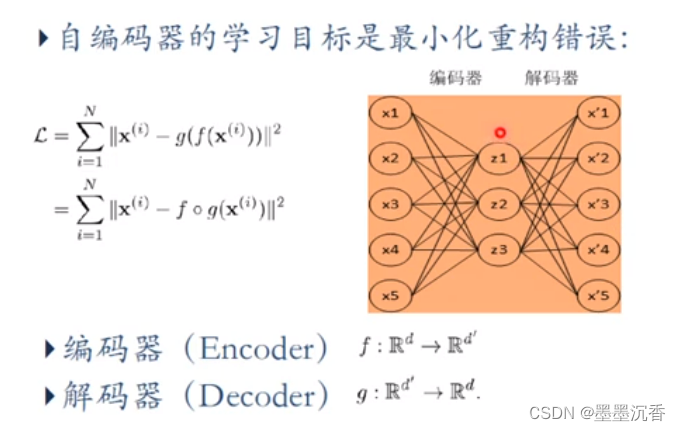
训练目标是使输出层与输入层误差最小;
中间隐层是代表输入的特征,可以最大程度上代表原输入信号。
堆叠自编码器
将多个自编码器得到的隐层串联;
所有层预训练完成后,进行基于监督学习的全网络微调。
自编码器总结
自编码器是一种网络结构,可配合其他结构搭建深度网络(如卷积、池化等)。
受限玻尔兹曼机(RBM)
RBM是两层神经网络,包含可见层v(输入层)和隐藏层h
不同层之间全连接,层内无连接→二分图
RBM没有显式的重构过程
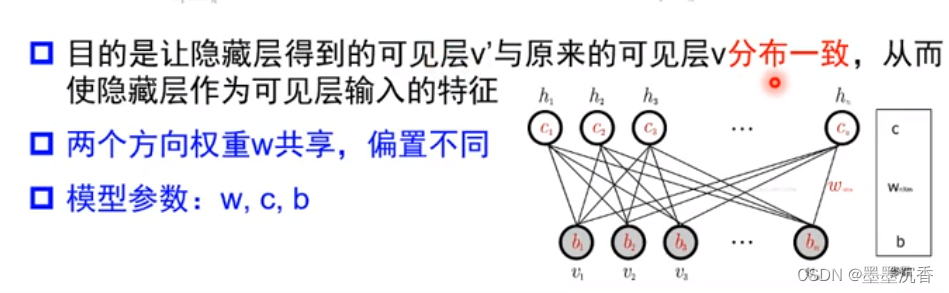
条件概率建模
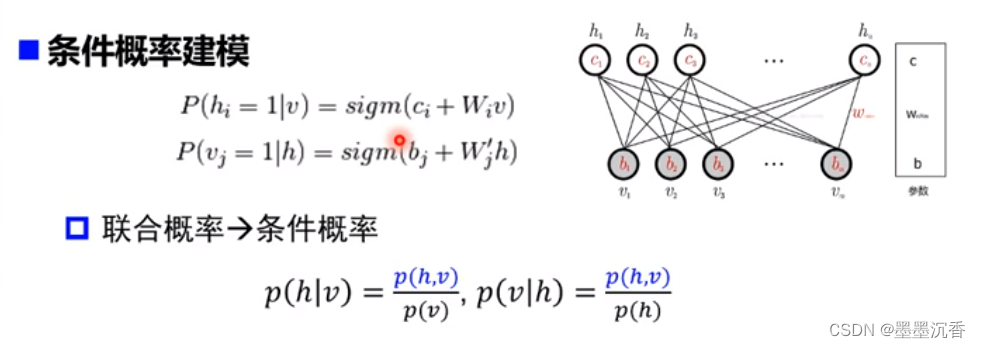
受限玻尔兹曼机采用联合概率→条件概率的方法


模型求解

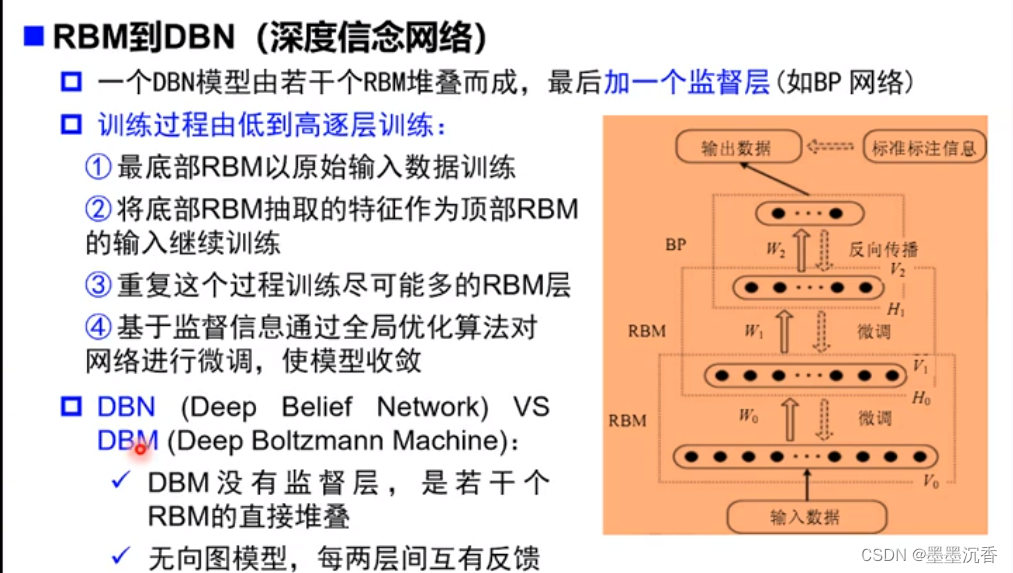
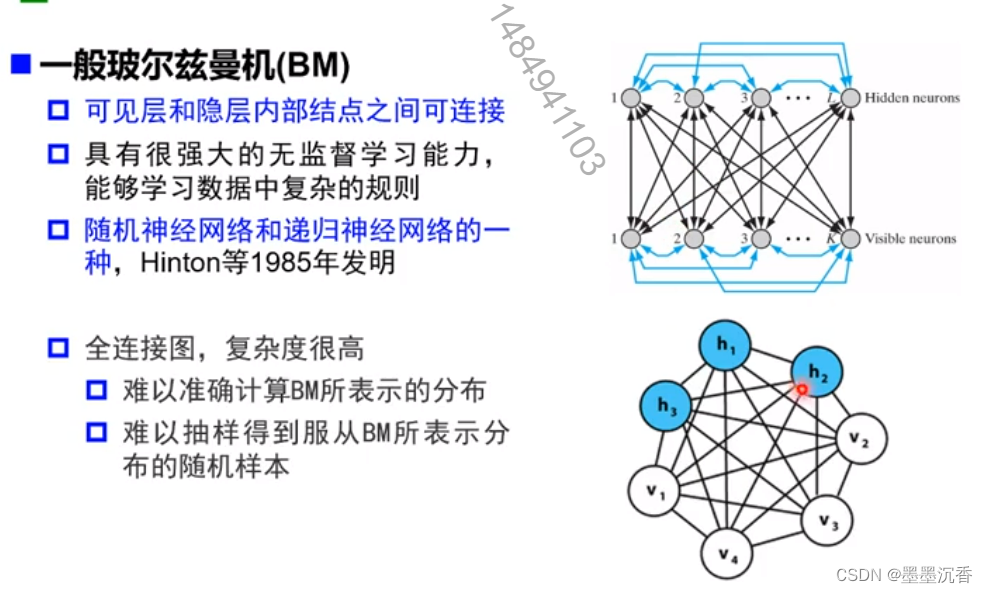
更多
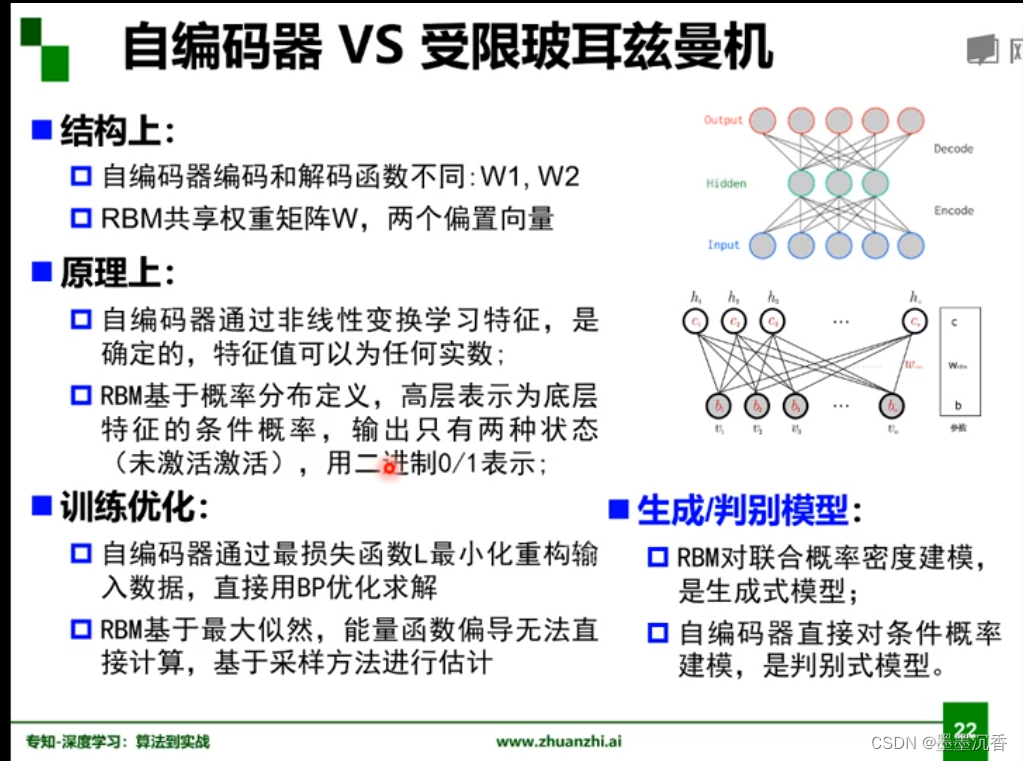
自编码器VS受限玻尔兹曼机
预训练的实际作用
















 1081
1081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









