









【人工智能与深度学习】监督方法的成功故事: 前置训练
监督方法的成功故事: 前置训练
在上十年,一个用在许多不同的计算机视觉问题上的主要成功秘诀就是对ImageNet分类进行监督学习来学习视觉的「表示」。而且在没有大量标记了的数据时,使用这些学习到的表示,或模型中学习了东西的权重都作为其他计算机视觉任务的初始化部分,这都是成功秘诀之一。
相對地,取得ImageNet这样大小的数据集的注解是超花时间和昂贵。比如:ImageNet标记一千4百万张图就花了22年。
因为这样,社区就找下别的标记方法,比如社交媒体图片的主题标签(hashtags),GPS位置,自我监督的方法,也就标签是数据样本本身的属性。
但更重要的问题就在别的标记法中出现了:
到底我们真正需要标记多少图片才够呢?
- 如果我们以物件类别分类和边界框式分类,那就有1百万张图片。
- 现在,如果边界框式分类的框被松开的话,那图片数量就跳跃到1400万(大约)。
- 相反,如果我们考虑用上互联网所有图像,就后方加多五个零吧。
- 而且,之后就要处理图片背后包含的数据,那就更要求其他感觉到这些的数据的输入来捕获或理解这些的数据。
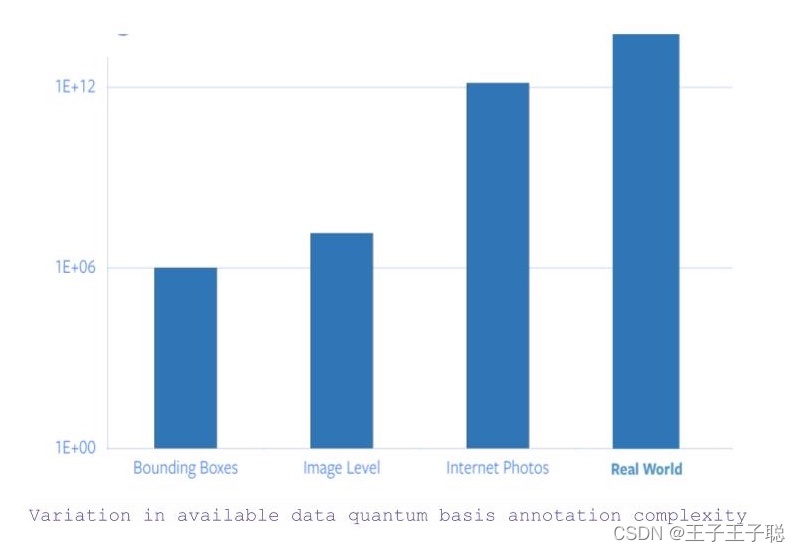
**图 1:**注释可用数据的总额基础复杂度的变化
所以,以事实上ImageNet对图片的注释就花了22个人类年,那标签网上所有的图片就是不可行的。
稀有概念的问题 (长尾巴问题)
就是了,大

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











