








Unsupervised Point Cloud Representation Learning With Deep Neural Networks: A Survey
Abstract
点云数据因其卓越的精度和在各种不利情况下的鲁棒性而受到广泛关注。与此同时,深度神经网络(DNN)在监控和自动驾驶等各种应用中取得了令人瞩目的成就。点云和 DNN 的融合催生了许多深度点云模型,这些模型大多是在大规模、高密度标签点云数据的监督下进行训练的。无监督点云表示学习旨在从未标明的点云数据中学习一般和有用的点云表示,由于大规模点云标注的限制,这种学习方法最近引起了越来越多的关注。本文全面回顾了使用 DNN 的无监督点云表示学习。本文首先介绍了近期研究的动机、一般流程和术语。然后简要介绍了相关背景,包括广泛采用的点云数据集和 DNN 架构。随后,根据技术方法对现有的无监督点云表示学习方法进行了广泛讨论。我们还在多个广泛采用的点云数据集上对所审查的方法进行了定量基准测试和讨论。最后,我们就未来无监督点云表示学习研究中可能面临的几个挑战和问题分享了自己的浅见。
I. INTRODUCTION
近年来,三维采集技术得到了快速发展。不同的三维传感器在工业领域和日常生活中日益普及,如自动驾驶汽车中的激光雷达传感器、Kinect 和苹果设备中的 RGB-D 摄像头、各种重建任务中的三维扫描仪等。与此同时,网格、点云、深度图像和体积网格等不同模式的三维数据也被收集起来,并广泛应用于自动驾驶、机器人、医疗、遥感等不同领域。
点云作为无处不在、应用广泛的三维数据源之一,可直接用入门级深度传感器采集,然后再将其三角化为网格或转换为体素。这使其很容易应用于各种三维场景理解任务[1],如三维物体检测和形状分析、语义分割等。随着深度神经网络(DNN)的发展,点云理解已引起越来越多的关注,近年来开发的大量深度架构和深度模型就是证明[2]。另一方面,深度网络的有效训练需要大规模的人类注释训练数据,如用于物体检测的三维边界框和用于语义分割的点状注释,由于三维视图的变化以及人类感知与点云显示之间的视觉不一致,这些数据的收集通常费时费力。在处理各种现实世界任务时,高效收集大规模注释点云已成为有效设计、评估和部署深度网络的一个瓶颈[3]。
无监督表征学习(unsupervised representation learning,URL)旨在从无标签数据中学习稳健而通用的特征表征,近来已得到深入研究,以减轻费力费时的数据标注挑战。如图 1 所示,URL 的工作方式类似于预训练,即从未标明数据中学习有用的知识,并将所学知识转移到各种下游任务中[4]。更具体地说,URL 可以提供有用的网络初始化,利用这种初始化,只需少量标明和特定任务的训练数据,就能训练出性能良好的网络模型,而且与随机初始化训练相比,不会出现过拟合现象。因此,URL 可以帮助减少训练数据和注释,这在以下方面已证明非常有效,自然语言处理 (NLP) [5]、[6]、二维计算机视觉 [7]、[8]、[9]、[10] 等领域。

图 1.点云无监督表征学习的一般流程:深度神经网络首先通过对某些预文本任务的无监督学习,使用未标注的点云进行预训练。然后,将学习到的无监督点云表征转移到各种下游任务中,以提供网络初始化,并利用少量特定任务的注释点云数据对预训练网络进行微调。
与文本和二维图像等其他类型数据的 URL 类似,点云的 URL 近来也引起了计算机视觉研究界越来越多的关注。已有许多 URL 技术被报道,这些技术通常是通过设计不同的预文本任务来实现的,如三维物体重建 [11]、部分物体补全 [12]、三维拼图求解 [13] 等。然而,与 NLP 和二维计算机视觉任务相比,点云的 URL 仍然远远落后。就目前而言,在各种目标新数据上从头开始训练仍是大多数现有三维场景理解开发的主流方法。另一方面,点云数据的 URL 面临着越来越多的问题和挑战,这主要是由于缺乏大规模和高质量的点云数据、统一的深度骨干架构、可推广的技术方法以及全面的公共基准。
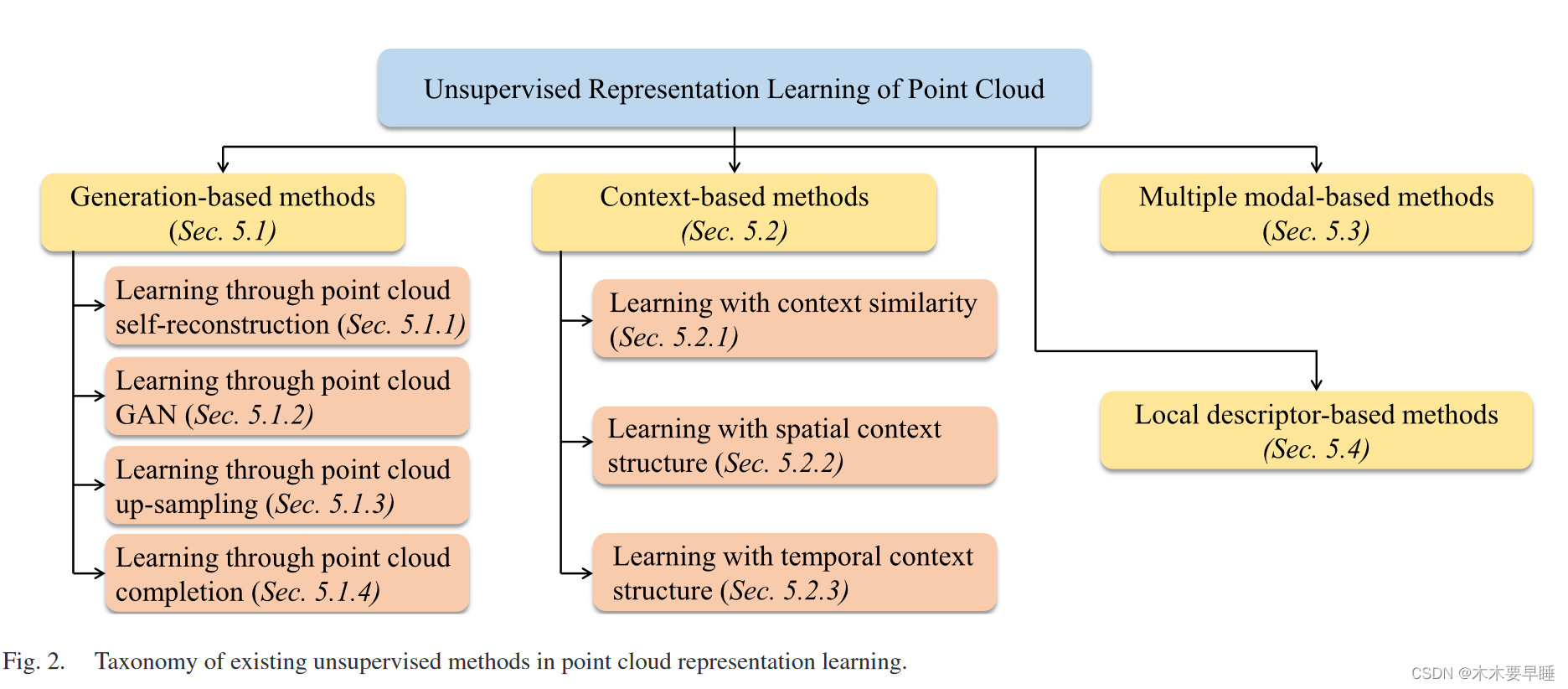
此外,针对点云的 URL 仍然缺乏系统性的调查,无法为这一全新而又充满挑战的任务提供清晰的全貌。为了填补这一空白,本文从数据集、网络架构、技术方法、性能基准和未来研究方向等方面,全面考察了无监督点云表示学习的最新进展。如图 2 所示,我们将现有方法按其前置任务大致分为四类,包括使用数据生成、全局和局部上下文、多模态数据和局部描述符的 URL 方法,更多细节将在下面的小节中讨论。
这项工作的主要贡献有三个方面:1)全面回顾了无监督点云表示学习的最新发展。据我们所知,这是第一份为这一令人兴奋的研究课题提供概述和全貌的调查报告。
2) 它研究了无监督点云表示学习的最新进展,包括在多个公共数据集上对现有方法进行全面的基准测试和讨论。
3) 分享了无监督点云表示学习的几个研究挑战和潜在研究方向。
本研究报告的其余部分安排如下:在第二节中,我们将介绍无监督点云学习的背景知识,包括术语定义、点云理解的常见任务以及与本研究相关的调查。第三节介绍广泛使用的数据集及其特点。第四部分介绍了常用的深度点云架构以及点云 URL 常用的典型模型。第五节我们系统地回顾了点云 URL 方法。第六节总结并比较了现有方法在多个基准数据集上的性能。最后,我们在第七部分列出了无监督点云表示学习的几个有前途的未来方向。
II. BACKGROUND
A. Basic Concepts
我们首先定义所有相关术语和概念,这些术语和概念将在接下来的章节中使用。点云数据:点云 P 是一组向量 P = {p1,...pN },其中每个向量代表一个点 pi = [Ci,Ai]。这里,Ci∈R1×3 指的是点的三维坐标(xi,yi,zi),Ai 指的是点的特征属性,如 RGB 值、LiDAR 强度、法线值等。
监督学习:在深度学习范式下,监督学习旨在通过使用标记的训练数据来训练深度网络模型。
无监督学习无监督学习旨在使用无标签的训练数据来训练网络。
无监督表征学习:URL 是无监督学习的一个子集。其目的是在不使用任何数据标签/注释的情况下,从数据中学习有意义的表征,学习到的表征可以转移到不同的下游任务中。有些文献也使用 "自监督学习"(self-supervised learning)这一术语。
半监督学习在半监督学习中,深度网络使用少量标记数据和大量未标记数据进行训练。其目的是通过从具有相似分布的少量标注数据和大量未标注数据中学习,缓解数据标注限制。
预训练:网络预训练是在其他数据集的基础上,通过某些前置任务进行学习。学习到的参数通常用于模型初始化,以便利用各种特定任务数据进一步微调。
迁移学习:迁移学习旨在跨任务、跨模式或跨数据集迁移知识。与这一调查相关的一个典型场景是为以下任务执行无监督学习预训练,将所学知识从无标签数据转移到各种下游网络。
B. Common 3D Understanding Tasks
本小节将介绍常见的三维理解任务,包括对象分类和对象部分分割中的对象级任务,以及三维对象检测、语义分割和实例分割中的场景级任务。这些任务已被广泛用于评估通过各种无监督学习方法学习到的点云表示的质量,第六节将详细讨论这些任务。
1) 对象分类:对象分类的目的是将点云对象划分为若干预定义的类别。最常用的评价指标有两个:总体准确度 (OA) 表示测试集中所有实例的平均准确度;平均类别准确度 (mAcc) 表示测试集中所有对象类别的平均准确度。
2) 物体部分分割:物体部件分割是点云表示学习的一项重要任务。如图 3 所示,其目的是为每个点分配一个部件类别标签(如飞机机翼、桌子腿等)。平均相交联合度(mIoU)[15] 是最广泛采用的评估指标。对于每个实例,属于该对象类别的每个部件都要计算 IoU。各部分 IoU 的平均值代表了该对象实例的 IoU。总体 IoU 是根据所有测试实例的 IoU 平均值计算的,而类别 IoU(或类别 IoU)则是根据该类别下实例的平均值计算的。
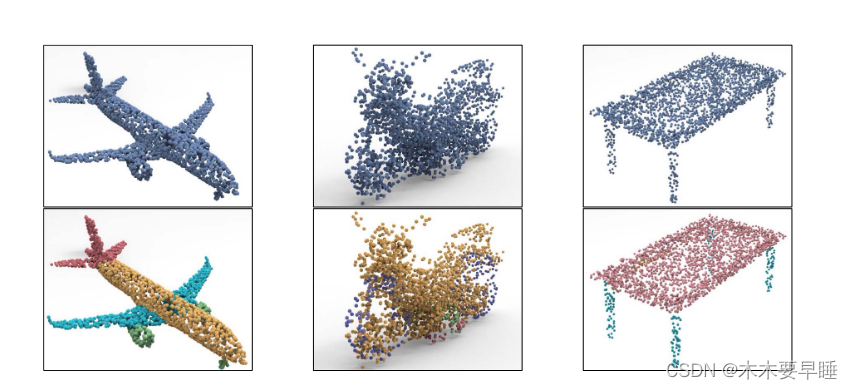
图 3物体部分分割示意图:第一行显示的是 ShapeNetPart 数据集 [14] 中的一些物体样本,包括飞机、摩托车和表格。第二行显示的是用不同颜色突出显示的不同部分的实际分割结果。
3) 3D 物体检测:点云上的三维物体检测是自动驾驶和家用机器人等许多现实世界应用中不可或缺的重要任务。这项任务旨在定位三维空间中的物体,即图 4 所示的三维物体边界框。平均精度(AP)指标已被广泛用于三维物体检测的评估 [16], [17]。
4) 三维语义分割:如图 5 所示,点云的三维语义分割是三维理解的另一项关键任务。与分割点云对象的对象部分分割不同,三维语义分割的目的是为场景级点云中的每个点分配一个类别标签,其复杂性要高得多。广泛采用的评估指标包括 OA、语义类别 mIoU 和 mAcc。
5) 三维实例分割:如图 6 所示,三维实例分割旨在检测和划分场景级点云中每个不同的感兴趣对象。语义分割只考虑语义类别,而实例分割则为每个物体分配唯一的标识。平均精度(mAP)已被广泛用于对这项任务进行定量评估。

C. Relevant Surveys
据我们所知,本文是第一份全面回顾无监督点云学习的研究报告。目前已经进行了几项相关但不同的调查。例如,有几篇论文回顾了点云深度监督学习的最新进展:Ioannidou 等人[22]综述了三维数据的深度学习方法;Xie 等人[23]对点云分割任务进行了文献综述;Guo 等人[2]对分类、检测、跟踪和分割等多个任务的点云深度学习进行了全面而详细的调查。此外,还有几篇论文对其他数据模式的无监督表示学习进行了综述:Jing 等人[24]介绍了二维计算机视觉中无监督表示学习的进展;Liu 等人[25]研究了二维计算机视觉、NLP 和图学习中无监督表示学习方法的最新进展;Qi 等人[26]介绍了包括无监督和半监督方法在内的小数据学习的最新进展。
III. POINT CLOUD DATASETS

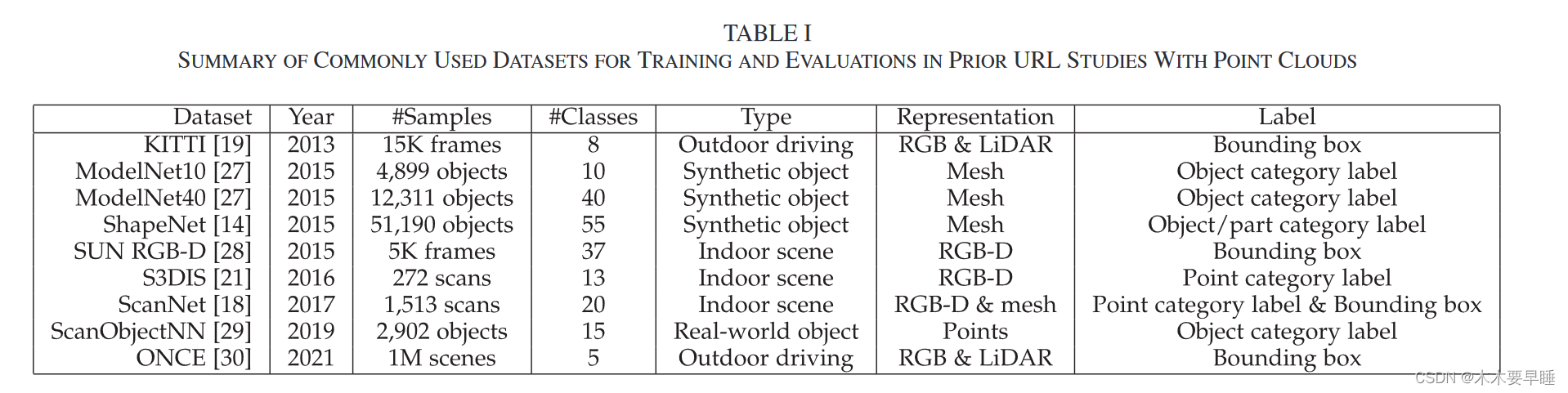
在本节中,我们将总结用于训练和评估无监督点云表示学习的常用数据集。如表一所列,现有工作主要从 1) 合成对象数据集(包括 ModelNet [27] 和 ShapeNet [14])或 2) 真实场景数据集(包括 ScanNet [18] 和 KITTI [19])中学习无监督点云表示。此外,还收集了各种特定任务数据集,可用于微调下游模型,如用于点云分类的 ScanObjectNN [29]、ModelNet40 [27] 和 ShapeNet [14],用于部件分割的 ShapeNetPart [14],用于语义分割的 S3DIS [21]、ScanNet [18] 或 Synthia4D [31],用于物体检测的室内数据集 SUNRGB-D [28] 和 ScanNet [18] 以及室外数据集 ONCE [30]。详细可看这篇
IV. COMMON DEEP ARCHITECTURES
在过去十年中,深度学习在点云处理和理解方面发挥了越来越重要的作用。这可以从近年来开发的大量深度架构中观察到。与将点云转换为八叉树(Octrees)[34] 或哈希体素列表(Hashed Voxel Lists)[35] 等结构的传统三维视觉不同,深度学习更倾向于可微分性和/或高效神经处理的结构,这些结构在各种三维任务中都取得了非常出色的性能。
在另一端,基于 DNN 的点云处理和理解远远落后于 NLP 和二维计算机视觉领域的同行。这在无监督表示学习任务中尤为明显,这主要是由于点云数据中缺乏规则表示。具体来说,单词嵌入和二维图像具有规则和明确的结构,但由无序点集表示的点云却没有这种通用的结构数据格式。
在本节中,我们将介绍针对点云 URL 所探索的深度架构。过去十年间,点云深度学习取得了重大进展,我们看到了大量三维深度架构和三维模型的提出。然而,我们并没有像二维计算机视觉中的 VGG [36] 或 ResNet [37] 那样通用的、无处不在的 "三维骨干"。因此,我们在本调查中将重点放在点云 URL 中常用的架构上。
为便于描述,我们将它们大致分为五类,即基于点的架构、基于图的架构、基于稀疏体素的架构、基于空间 CNN 的架构和基于变换器的架构。请注意,正如文献[2]所讨论的,其他深度架构也适用于各种三维任务,如基于投影的网络[38]、[39]、[40]、[41]、[42]、[43],递归神经网络[44]、[45]、[46],三维胶囊网络[47]等。不过,它们并不常被用于 URL 任务,因此本调查报告未作详细介绍。
A. Point-Based Deep Architectures
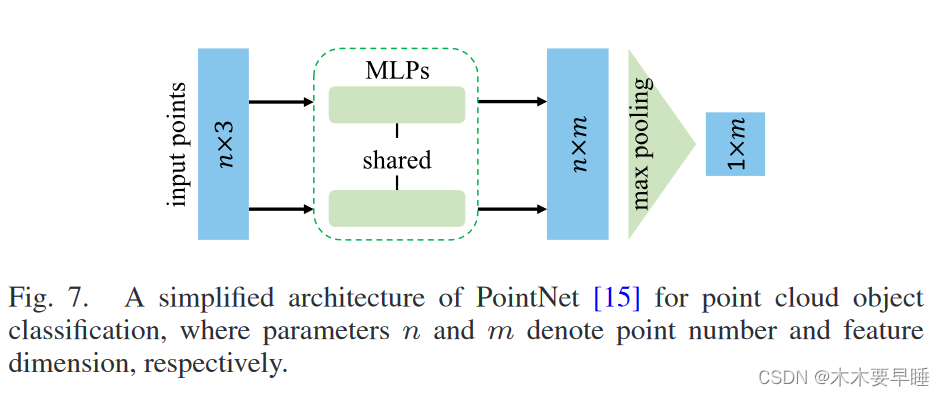
基于点的网络旨在直接处理原始点云,而无需事先进行点数据转换。通常首先通过多层感知器(MLP)堆叠网络提取独立点特征,然后利用对称聚合函数将其聚合为全局特征。如图 7 所示,PointNet [15] 是基于点的网络先驱。它通过堆叠多个 MLP 层来独立学习点特征,并将学习到的特征转发给最大池化层,以提取全局特征,从而实现包覆不变性。为了改进 PointNet,Qi 等人提出了 PointNet++[48],从点的邻域学习局部几何细节,其中集合抽象层包括采样层、分组层和 PointNet 层,用于学习局部和层次特征。PointNet++ 在物体分类和语义分割等多项三维任务中取得了巨大成功。以 PointNet++ 为骨干,Qi 等人设计了首个基于点的三维物体检测网络 VoteNet [16]。VoteNet 采用 Hough 投票策略,在物体中心周围生成新点,并将这些点与周围的点进行分组,从而生成三维方框提案。
B. Graph-Based Deep Architectures
如图 8 所示,基于图的网络将点云视为欧几里得空间中的图,顶点为点,边表示相邻点的关系。它采用图卷积技术,滤波器权重以边缘标签为条件,并针对单个输入样本动态生成。这样就可以通过强制权重共享和提取局部特征来捕捉相邻点之间的依赖关系,从而降低所学模型的自由度。动态图卷积神经网络(DGCNN)[49] 是一种典型的基于图的网络,经常用于点云的 URL。它与一个名为 EdgeConv 的图卷积模块堆叠在一起,可在特征空间中对图进行动态卷积。DGCNN 将 EdgeConv 集成到基本版本的 PointNet 结构中用于学习点云理解的全局形状属性和语义特征.
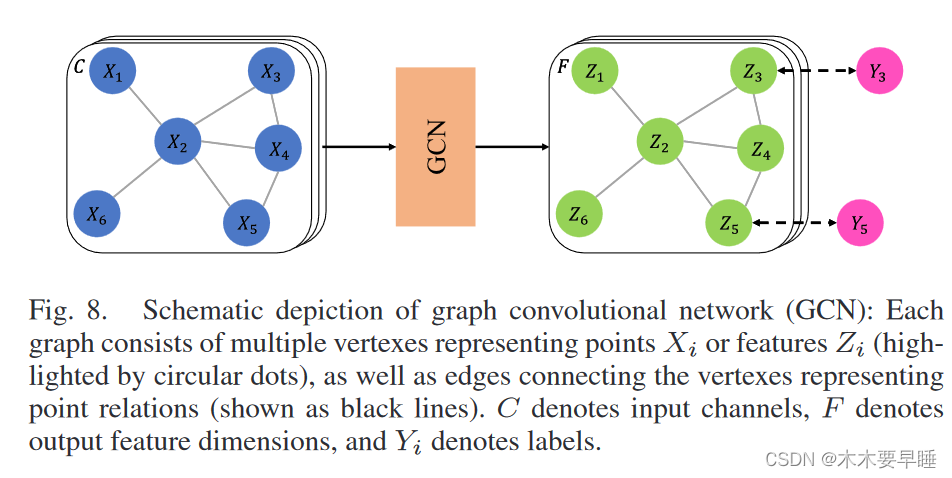
C. Sparse Voxel-Based Deep Architectures
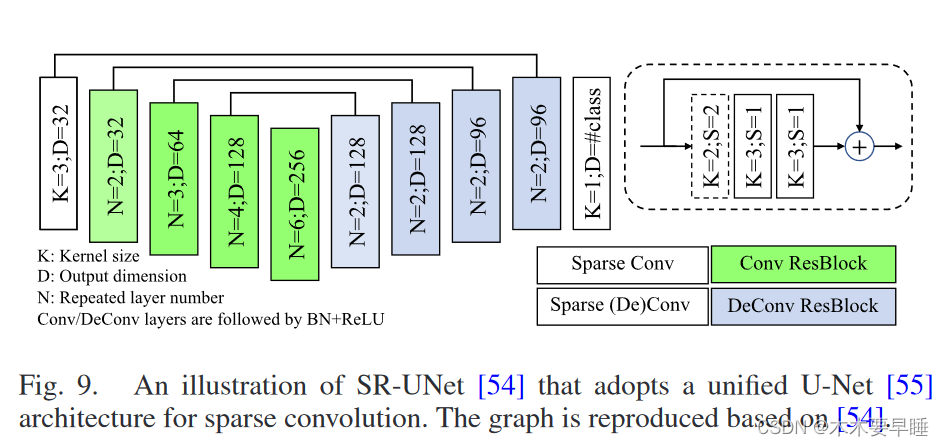
基于体素的架构先将点云细化为三维网格,然后再将三维 CNN 应用于体积表示。由于点云数据的稀疏性,在处理大量点时往往会产生巨大的计算冗余或牺牲表示精度。为了克服这一限制,[50]、[51]、[52]、[53] 采用稀疏张量作为基本单位,用数据列表和索引列表来表示点云。与使用滑动窗口(PyTorch 和 TensorFlow 中的 im2col 函数)构建计算流水线的标准卷积操作不同,稀疏卷积 [50] 收集了包括卷积核元素在内的所有原子操作,并将它们作为计算指令保存在规则手册中。最近,Choy 等人提出了 Minkowski 引擎[51],引入了广义稀疏卷积和稀疏张量的自动微分库。在此基础上,Xie 等人[54]采用统一 U-Net [55]架构,建立了一个用于无监督预训练的骨干网络(SR-UNet,如图 9 所示)。学习到的编码器可用于不同的下游任务,如分类、物体检测和语义分割。
D. Spatial CNN-Based Deep Architectures
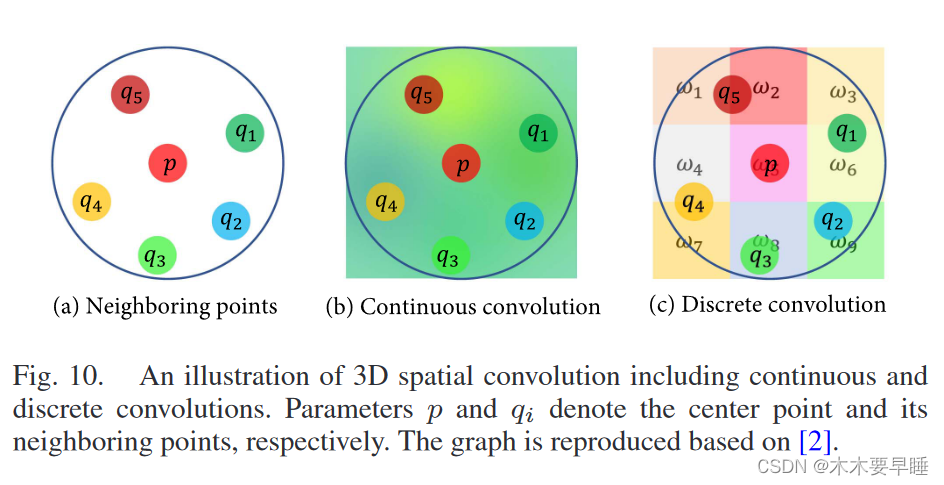
基于空间 CNN 的网络是为了扩展常规网格 CNN 的功能,以分析不规则间隔的点云而开发的。如图 10 所示,连续卷积网络定义了连续空间中的卷积核、其中,相邻点的权重由它们相对于中心点的空间分布决定。不同的是,离散卷积网络在规则网格上运行,并在离散空间中定义卷积核,在离散空间中,相邻点相对于中心点有固定的偏移量。连续卷积模型的一个典型例子是 RS-CNN [56],它已被广泛用于点云的 URL。具体来说,RS-CNN 提取局部中心与周围点之间的几何拓扑关系,并学习卷积的动态权重。
E. Transformer-Based Deep Architectures
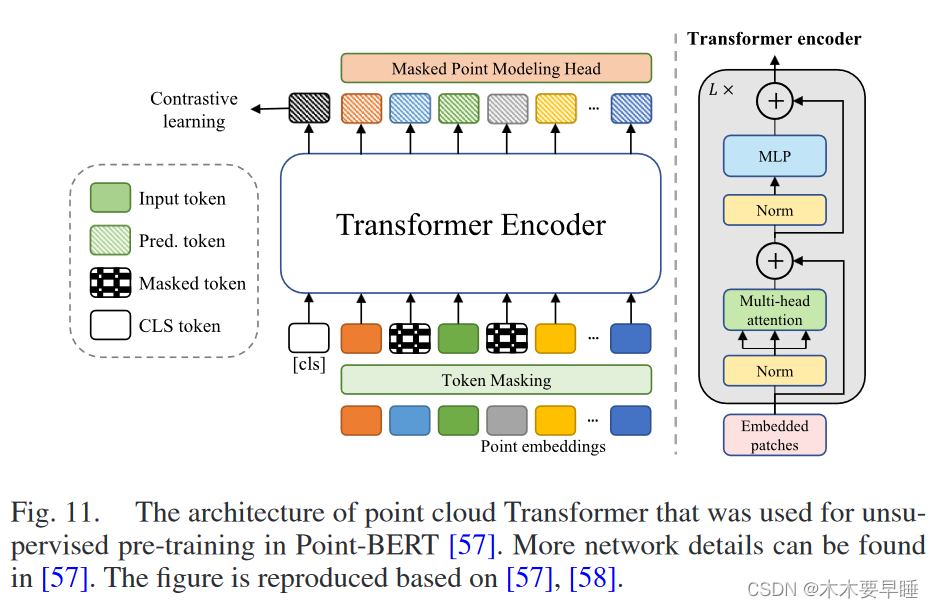
在过去几年中,变形器凭借其结构优势和多功能性,在 NLP [32], [59] 和 2D 图像处理 [58], [60] 等研究领域取得了惊人的进展。最近,它们还被引入点云处理领域 [57], [61]。图 11 显示了用于点云 URL 的标准 Transformer 架构[57],它包含一叠 Transformer 模块[59],每个模块由多头自注意层和前馈网络组成。无监督预训练的 Transformer 编码器可用于微调对象分类和语义分割等下游任务。



















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











