







该文发表在 SenSys’23(CCF B) 上,作者是来自港中文的鄢振宇。这是一篇关于云端协同的文章,主要解决边缘设备深度模型的泛化性不足问题,实现 Open-set Learning。
文章目录
背景
随着深度学习以及芯片的发展,越来越多的深度模型选择在边缘端部署。由于边缘设备资源有限(无论是内存资源,还是计算资源),并不能发挥出模型 100% 的能力。当前大多数边缘 AI 模型都是基于特定任务的,仅仅识别训练中出现的类别,对于未知类别的输入数据,模型的精度会大幅降低。
而大模型并不会出现这种问题。如图一所示,大模型具有零样本学习能力,对于未知类别的输入,也会很好地完成分类。而且大模型可以处理多个不同下游任务,比如我们可以只使用 GPT-4 就可以完成中英文翻译、知识问答、作诗等多种不同任务。
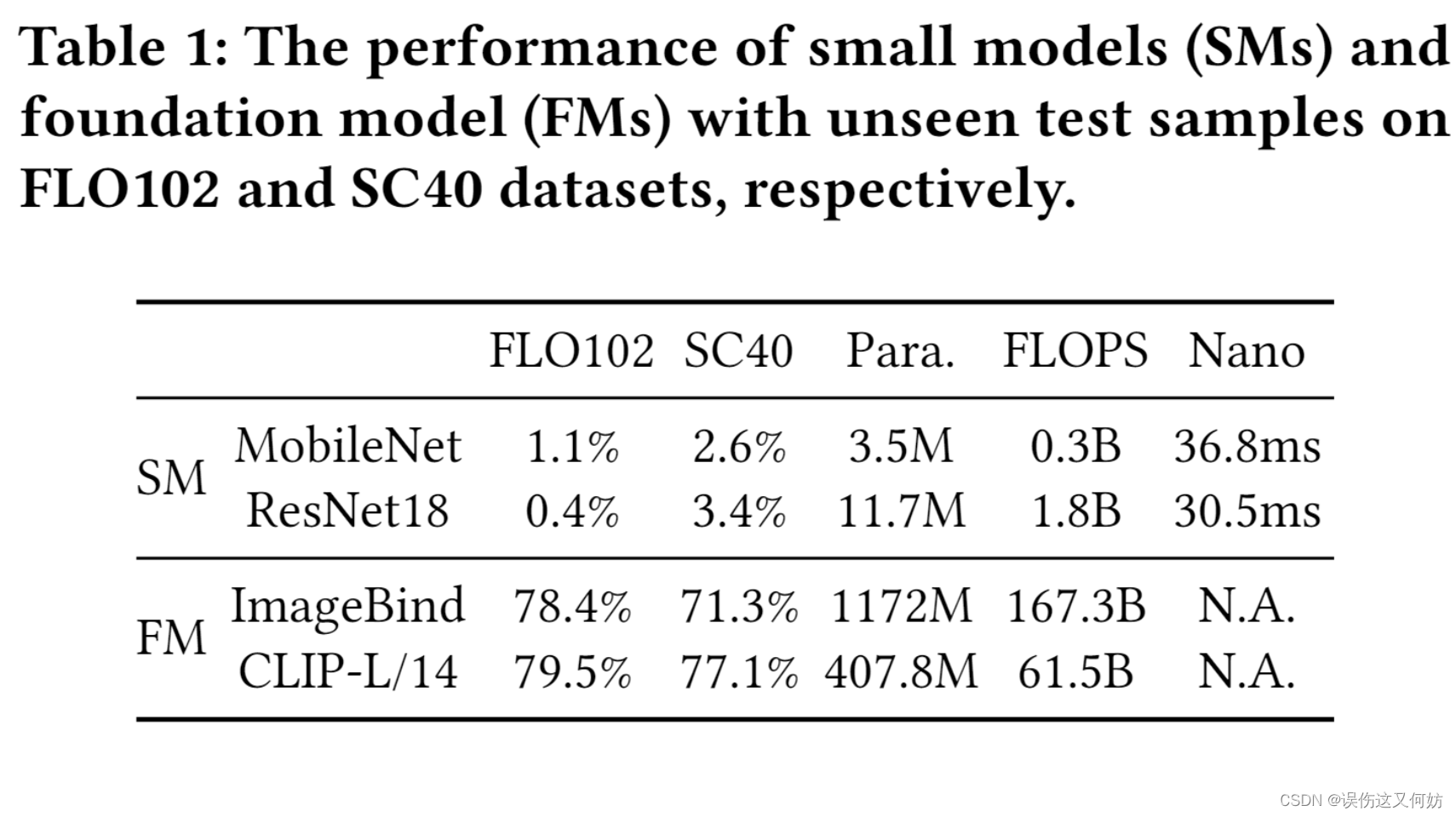
当前工作都是基于闭集识别(仅可识别训练中出现的类)的研究,对于 Open-set Recognition 方面,并没有人涉及到。
Open-Set Recognition 的挑战
- 资源有限
一旦涉及到边缘设备,资源问题永远是一大痛点,对于大模型更是如此。我们不可能直接在边缘端直接应用大模型(FMs),那如何利用大模型增强边缘 AI 模型的泛化性成为一个比较大的挑战。 - 在动态环境中保持泛化性
真实环境并不是静态的,网络带宽变化、场景突变都有可能发生。这更加考验系统的鲁棒性。 - 实时性
多数任务都有实时性要求,不可能前朝事今朝判。
EdgeFM 整体架构图
这个系统包括两个主要功能:选择式上传未知数据以及为边缘端定制专有小模型。
- Edge 端收集 Applications(任务、精度和时延)和 Resources (内存,计算资源)数据并进行分析。Model Selection使用该分析结果在 Model Pool 中选取最合适的模型架构。之后该模型架构结合边缘端上传的未知数据进行语义定制。最后把定制好了的小模型部署在 Edge 端。
- 未知数据通过定制小模型生成 Sensor embeding数据,之后进行不确定性量化,最后根据不确定性量化结果决定是否上传 Cloud 端。
- 在推理过程中,Inference Engine 采用 Dynamic Network Apaptation 来检测网络状况并更新阈值搜索表(该表用来查询最优阈值的)。同时,Inference Engine会根据网络带宽和不确定性度量来决定是否在本地运行。
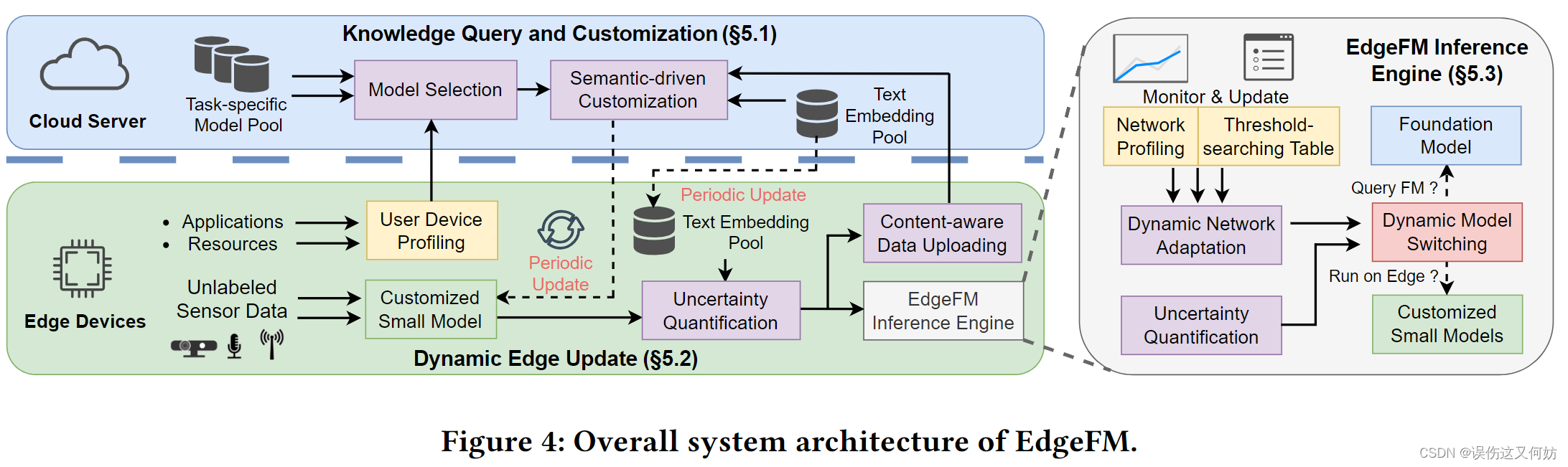
云端:Knowledge Query and Customization
我将重点讲解 Semantic-driven Customization 的做法,其他部分不详细讲述(比较简单QAQ)
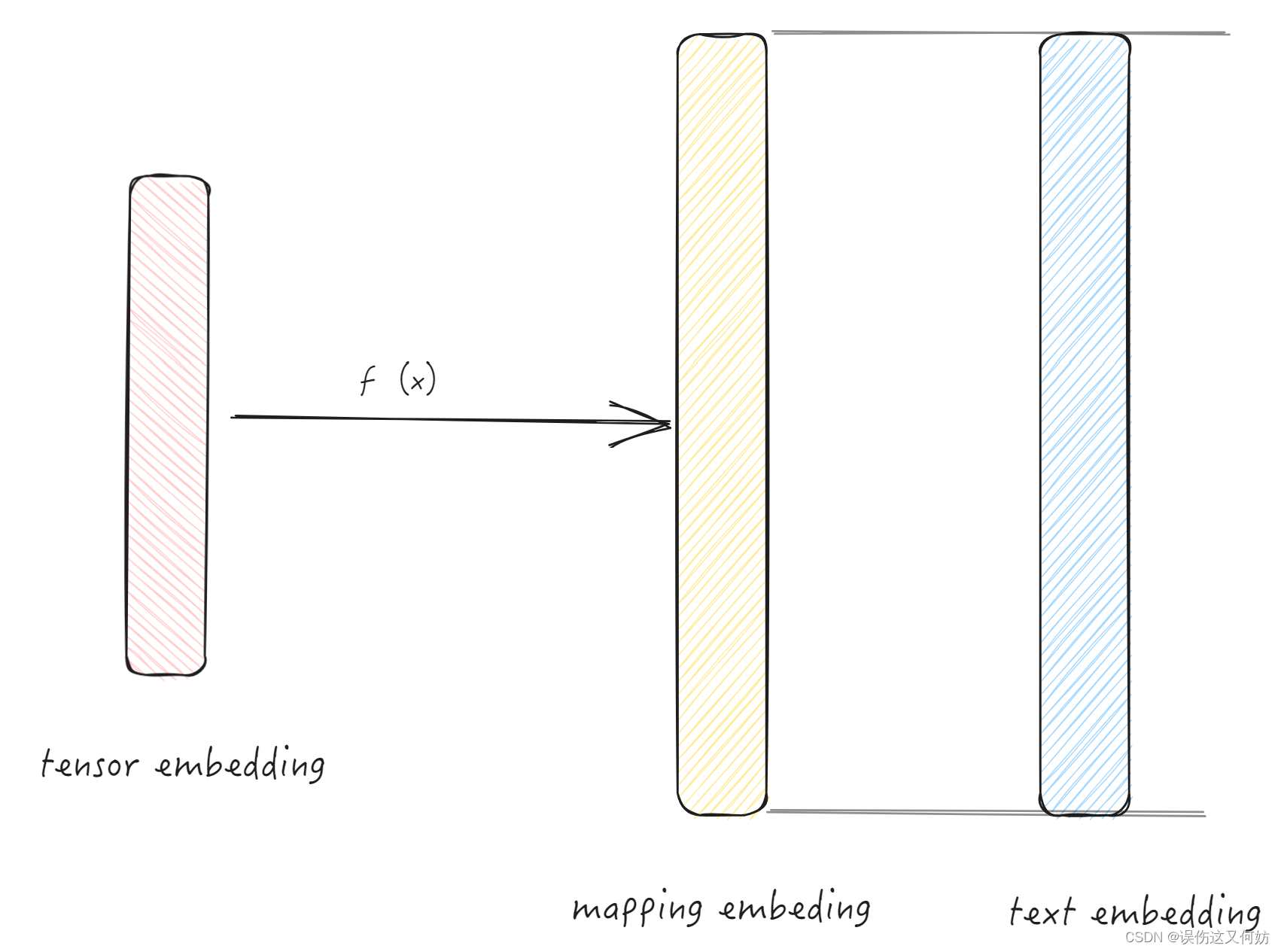
Heterogeneous Feature Mapping
由于边缘 AI 模型和大模型的架构不同,所产生的embedding数据维度也有可能不同。为了小模型可以更简单学习到大模型的知识,因此使用投影网络使得二者embeding维度相同:
v
i
=
ψ
(
S
(
x
i
)
)
\mathbf{v}_{i}=\psi\left(\mathcal{S}\left(\mathbf{x}_{i}\right)\right)
vi=ψ(S(xi))
Knowledge Query from the Foundation Model
这一 part 解决对未知类别样本进行分类问题。中心思想也很简单就是在文本池中选取置信度最高的文本作为该数据标签。
t
i
′
=
argmax
(
⟨
T
v
(
x
i
)
,
t
k
⟩
)
,
t
k
∈
T
\mathbf{t}_{i}^{\prime}=\operatorname{argmax}\left(\left\langle\mathcal{T}_{v}\left(\mathbf{x}_{i}\right), \mathbf{t}_{k}\right\rangle\right), \mathbf{t}_{k} \in \mathbf{T}
ti′=argmax(⟨Tv(xi),tk⟩),tk∈T
Semantic-driven Distillation Loss
大模型的泛化能力很强,因此小模型要学习大模型的输出,尽量达到大模型效果。在这里,本文采用的是双向对比学习方式进行学习。
LOSS:
-
从文本到图像:
L i v → t ′ = − l o g e x p { < Ψ i , t ^ k > / τ } ∑ k = 1 b S e x p { < < Ψ i , t ^ k > / τ } \mathcal{L}_{i}^{v\rightarrow t^{\prime}}=-l o g\frac{e x p\ \left\{\left<\Psi_{i},\hat{\bf t}_{k}\right>/{\tau}\right\}}{\sum_{k=1}^{b_{S}}e x p\ \mathrm{\left\{\left<\left<\Psi_{i},\hat{\bf t}_{k}\right>\right./{\tau}\right\}}} Liv→t′=−log∑k=1bSexp {⟨⟨Ψi,t^k⟩/τ}exp {⟨Ψi,t^k⟩/τ} -
从图像到文本:
L i t ′ → v = − l o g e x p { < t ^ i , v k > / τ } ∑ k = 1 b S e x p { < < t ^ i , v k > / τ } \mathcal{L}_{i}^{t^{\prime}\rightarrow v}=-l o g\frac{e x p\ \big\{\left<\hat{\bf t}_{i},\mathbf{v}_{k}\right>\big/\tau\big\}}{\sum_{k=1}^{b_{S}}e x p\ \mathrm{\left\{\left<\left<\hat{t}_{i},\mathbf{v}_{k}\right>\right.\big/\tau\right\}}} Lit′→v=−log∑k=1bSexp {⟨⟨t^i,vk⟩/τ}exp {⟨t^i,vk⟩/τ}
-
交叉熵loss
L t e x t = 1 b s ∑ i = 1 b s w i { λ L i v → t ′ + ( 1 − λ ) L i t ′ → v } \mathcal{L}_{t e x t}=\frac{1}{b s}\sum_{i=1}^{b s}w_{i}\left\{\lambda\mathcal{L}_{i}^{v\to t^{\prime}}+(1-\lambda)\mathcal{L}_{i}^{t^{\prime}\to v}\right\} Ltext=bs1i=1∑bswi{λLiv→t′+(1−λ)Lit′→v}其中 w i w_i wi 表示预测置信度,代表未知类别输入成功预测几率有多大(注意置信度有可能大于1)。bs表示 batch 大小。
边缘端:Dynamic Edge Update
前面提到:未知数据会有选择地上传云端。下面我们来探讨一下如何选择未知数据到云端。
对于一个样本来说,如果对于某一类别标签的置信度非常高,而对于其他类别标签的置信度很低,那这个样本还用上传云端吗?显然不用,该样本预测正确的概率极大。因此,我们得到一个经验结论:只要第一置信度很高,其他类别置信度很低,那用边缘小模型处理该样本最优。在这里,我们用余弦相似度来表示置信度:
s
i
m
(
x
i
)
=
⟨
V
i
,
t
k
⟩
sim({\bf x}_{i})\;{{{=}}}\;\langle\mathrm{V}_{i},\mathrm{t}_{k}\rangle
sim(xi)=⟨Vi,tk⟩
不确定性度量,这里用第一置信度与第二置信度的差值表示:
U
n
c
(
x
i
)
=
s
i
m
1
(
x
i
)
−
s
i
m
2
(
x
i
)
U n c({\bf x}_{i})\,=\,s i m_{1}({\bf x}_{i})-s i m_{2}({\bf x}_{i})
Unc(xi)=sim1(xi)−sim2(xi)
当 Unc 小于阈值时,代表本地模型无法进行可靠分类,因此发送到云端进行处理。反之,使用本地模型进行处理。
U
n
c
(
x
i
)
<
V
t
h
r
e
U n c({\bf x}_{i})\,<\,V_{t h r e}
Unc(xi)<Vthre
推理侧:EdgeFM Inference Engine
在推理过程中,EdgeFM会自适应性选择最合适的运行方式(cloud or edge)。EdgeFM 还是基于置信度作为衡量指标。(置信度这么好用????)
和上面相同,Unc小于阈值时上传云端,大于阈值时在本地执行。
r ( x i ) = { U n c ( x i ) ≥ t h r e ( t ) } r({\bf x_i}) = \{Unc({\bf x_i}) \ge thre(t)\} r(xi)={Unc(xi)≥thre(t)}
从上面这个公式可以看出, t h r e ( t ) thre(t) thre(t) 的取值直接影响 EdgeFM 的决策。因此我们需要动态调整阈值大小,确保 EdgeFM 做出正确决策。
选取最佳阈值
-
定义系统时延公式:
t ^ e 2 e ( t h r e ) = r ( t h r e ) ⋅ t e d g e + ( 1 − r ( t h r e ) ) ⋅ ( t t r a n s + t c l o u d ) \hat{t}_{e2e}(t h r e)=r(t h r e)\cdot t_{e d g e}+(1-r(t h r e))\cdot(t_{t r a n s}+t_{c l o u d}) t^e2e(thre)=r(thre)⋅tedge+(1−r(thre))⋅(ttrans+tcloud) -
在满足时延要求的情况下,thre 越大越好:
max t h r e ∈ ( 0 , 1 ) t h r e s . t . t ^ e 2 e ( t h r e ) ≤ L a p p \operatorname*{max}_{t h r e\in(0,1)}\ t h r e\quad\mathrm{s.t.}\quad\hat{t}_{e2e}(t h r e)\le L_{a p p} thre∈(0,1)max thres.t.t^e2e(thre)≤Lapp
系统评估
-
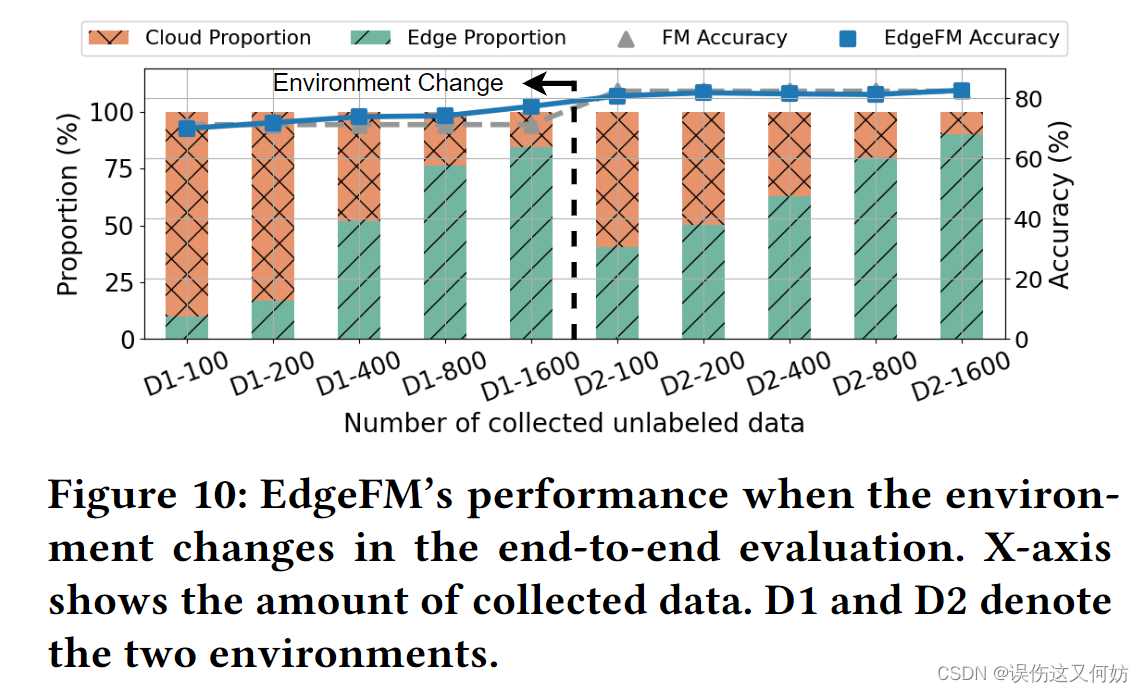
系统具有泛化性
-
在不降低精度的情况下,时延大幅降低(实时性)

评价
ing…















 3220
3220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











