







1. Value Based强化学习方法的局限性
DQN系列强化学习算法主要有三点不足。
(1)对连续动作的处理能力不足;
(2)对受限状态下的问题处理能力不足。在使用特征来描述状态空间中的某一个状态时,有可能因为个体观测的限制或者建模的局限,导致真实环境下本来不同的两个状态却再我们建模后拥有相同的特征描述,进而很有可能导致我们的value Based方法无法得到最优解。
(3)无法解决随机策略问题。Value Based强化学习方法对应的最优策略通常是确定性策略,因为其是从众多行为价值中选择一个最大价值的行为,而有些问题的最优策略却是随机策略,这种情况下同样是无法通过基于价值的学习来求解的。
2.Policy Based强化学习方法引入
回想我们在 Value Based 强化学习方法里,我们对价值函数进行了近似表示,引入了一个动作价值函数 q^ ,这个函数由参数 w 描述,并接受状态 s 与动作 a 作为输入,计算后得到近似的动作价值,即:
在 Policy Based 强化学习方法下,采用类似的思路,只不过这时对策略进行近似表示。此时 即:
将策略表示成一个连续的函数后,我们就可以用连续函数的优化方法来寻找最优的策略了。而最常用的方法就是梯度上升法了,那么这个梯度对应的优化目标如何定义呢
3.策略梯度的优化目标
我们要用梯度上升来寻找最优的梯度,首先就要找到一个可以优化的函数目标。最简单的优化目标就是初始状态收获的期望,即优化目标为:
但是有的问题是没有明确的初始状态的,那么我们的优化目标可以定义平均价值,即:
其中, 是基于策略
生成的马尔科夫关于状态的静态分布。
或者定义为每一时间步的平均奖励,即:
无论我们是采用 J1 , JavV , 还是 JavR 来表示优化目标,最终对 θ 求导的梯度都可以表示为:
![]()
当然我们还可以采用很多其他可能的优化目标来做梯度上升,此时我们的梯度式子里面的∇θlogπθ(s,a) 部分并不改变,变化的只是后面的 Qπ(s,a) 部分。对于 ∇θlogπθ(s,a) , 我们一般称为分值函数(score function)。
现在梯度的式子已经有了,后面剩下的就是策略函数 πθ(s,a) 的设计了。
4.策略函数的设计
现在我们回头看一下策略函数 πθ(s,a) 的设计,在前面它一直是一个数学符号。
最常用的策略函数就是 softmax 策略函数了,它主要应用于离散空间中,softmax 策略使用描述状态和行为的特征 ϕ(s,a) 与参数 θ 的线性组合来权衡一个行为发生的几率,即:
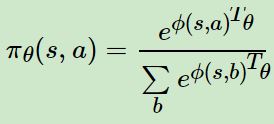
则通过求导很容易求出对应的分值函数为:
![]()
另一种高斯策略则是应用于连续行为空间的一种常用策略。该策略对应的行为从高斯分布N(ϕ(s)Tθ,σ2) 中产生。高斯策略对应的分值函数求导可以得到为:
![]()
有策略梯度的公式和策略函数,我们可以得到第一版的策略梯度算法了。
5.蒙特卡洛策略梯度 reinforce 算法
这里我们讨论最简单的策略梯度算法,蒙特卡罗策略梯度 reinforce 算法, 使用价值函数 v(s) 来近似代替策略梯度公式里面的 Qπ(s,a) 。算法的流程很简单,如下所示:
输入:N个蒙特卡罗完整序列,训练步长α
输出:策略函数的参数θ
1. for 每个蒙特卡罗序列:
a. 用蒙特卡罗法计算序列每个时间位置 t 的状态价值 vt
b. 对序列每个时间位置t,使用梯度上升法,更新策略函数的参数θ:
θ=θ+α∇θlogπθ(st,at)vt
2. 返回策略函数的参数 θ
这里的策略函数可以是 softmax 策略,高斯策略或者其他策略。
6.策略梯度实例
7.策略梯度小结
策略梯度提供了和DQN之类的方法不同的新思路,但是我们上面的蒙特卡罗策略梯度reinforce 算法却并不完美。由于是蒙特卡罗法,我们需要完全的序列样本才能做算法迭代,同时蒙特卡罗法使用收获的期望来计算状态价值,会导致行为有较多的变异性,我们的参数更新的方向很可能不是策略梯度的最优方向。
因此,Policy Based的强化学习方法还需要改进,注意到我们之前有 Value Based 强化学习方法,那么两者能不能结合起来一起使用呢?下一篇我们讨论Policy Based+Value Based结合的策略梯度方法 Actor-Critic。
文章参考来源:强化学习(十三) 策略梯度(Policy Gradient) - 刘建平Pinard - 博客园 (cnblogs.com)















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









