







 文章目录1. 演员、环境和奖励2. 最大化期望奖励1. 演员、环境和奖励(1)定义演员就是一个网络,输入状态,输出动作。环境就是一个函数,输入状态和动作,输出状态。环境是基于规则的规则,是确定不变的。奖励是在某一个状态下采取某个动作能够获得的分数。环境是一个随机变量(因为状态和环境都是在一定分布下抽样获得的),我们可以计算的是奖励的期望值。(2)某一个轨迹发生的概率pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣a1,s1)pθ(a2∣s2)p(s3∣a2,s2)⋯=p(s1)∏t=
文章目录1. 演员、环境和奖励2. 最大化期望奖励1. 演员、环境和奖励(1)定义演员就是一个网络,输入状态,输出动作。环境就是一个函数,输入状态和动作,输出状态。环境是基于规则的规则,是确定不变的。奖励是在某一个状态下采取某个动作能够获得的分数。环境是一个随机变量(因为状态和环境都是在一定分布下抽样获得的),我们可以计算的是奖励的期望值。(2)某一个轨迹发生的概率pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣a1,s1)pθ(a2∣s2)p(s3∣a2,s2)⋯=p(s1)∏t=
文章目录
Reference
[1] David Silver: https://www.youtube.com/watch?v=KHZVXao4qXs&t=4609s
1. Introduction
1.1 Value-Based and Policy-Based
定义
Value-Based和Policy-Based是RL的两种学习方式。Value-Based需要先学习价值评估,再根据价值选择最优动作。Policy-Based则是直接学习策略选择。
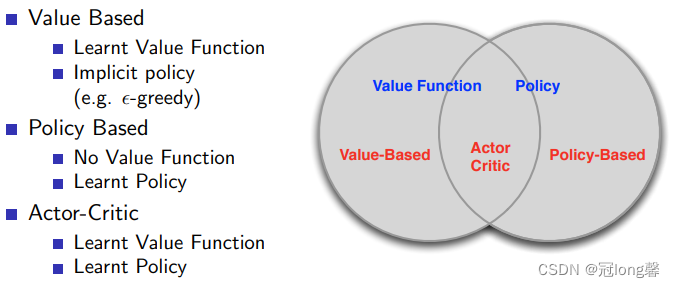
- 因为不用价值预测,Policy-Based方法在高维或连续动作空间中更加高效,也更容易收敛。
- Value-Based方法中函数通过近似逼近真实的价值,并通过循环的价值迭代接近最优价值以及确定的最优策略。而Policy-Based方法则支持随机策略选择。
1.2 Policy-Gradient
因为在强化学习(五)中我们介绍了常见的Value-Based方法,本章我们着重介绍Policy-Based方法。
Policy-Based方法具有两个基本要素:目标函数、策略优化。
1.2.1 目标函数(Policy Objective Functions)
目标函数用于衡量选择策略的好坏。目标函数可以采用开始价值和平均价值衡量,价值又可以通过MC或TD采样获得。

1.2.2 策略优化(Policy Optimisation)
策略优化的目标是使得执行策略得到的目标函数最大,我们也有多种优化方法。

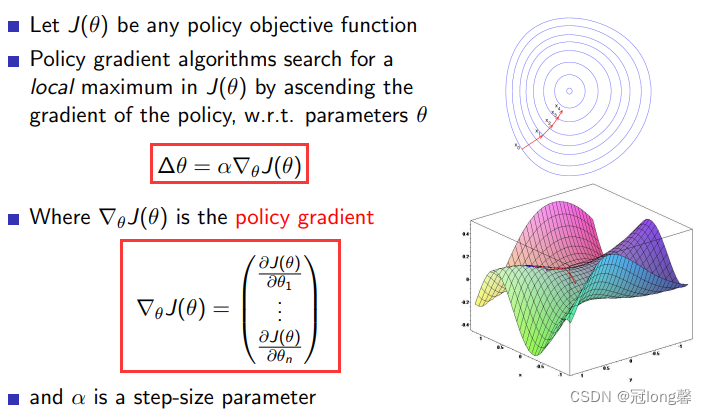
当我们选择梯度下降作为策略优化方法后,便获得了梯度下降算法。通过梯度下降方法优化,使得采用策略能够获得最大的价值。
1.2.3 梯度下降(Gradient Descent)
1.2.4 Score Function

1.3 单步马尔可夫决策过程(One-Step MDPs)
环境起始于状态s,终止于采取动作后的下一时间步。此时目标函数可以用采取动作获得奖励的期望表示。

1.4 多步马尔可夫决策过程(Multi-Step MDPs)
多步MDPs可以使用长期价值 Q π ( s , a ) = R s a + ∑ s ′ ∈ S P s s ′ V π ( s ′ ) Q^\pi(s,a)=R_s^a+\sum_{s' \in S} P_{ss'}V^\pi(s') Qπ(s,a)=Rsa+∑s′∈SPss′Vπ(s′)代替单步即时奖励r。所以多步马尔可夫决策过程的策略梯度可以表示为

2. 蒙特卡洛策略梯度(MC Policy Gradient)
如上文所述,策略梯度由目标函数与梯度下降优化算法两部分组成。在多部马尔可夫决策过程中,目标函数可以通过MC或者TD方法求得。这一节主要介绍MC求目标函数与梯度下降的结合。
2.1 REINFORCE
在强化学习(五)价值函数近似中我们了解到回报 G t G_t Gt可以通过无偏估计V函数或有偏估计Q函数近似。REINFORCE采取采样轨迹的回报计算Q函数。
算法

特点
- 需要在一条完整的轨迹上学习
- 采用随机梯度下降策略
- 学习效率低,具有高方差
结合强化学习(五)价值函数近似,我们可以尝试使用函数近似代替MC采样轨迹的回报,这样就不需要从完整的轨迹中进行学习了。
3. 演员评论家策略梯度(Actor-Critic Policy Gradient)
定义
加入critic替代MC预估动作价值函数。actor用于选择和优化策略。

根据强化学习(五)中的内容,Critic可以采用多种方式预测动作价值函数,下面我们将一一介绍。
3.1 QAC(Action-Value Actor-Critic)
算法


问题
- 采用动作价值 Q w ( s , a ) Q_w(s,a) Qw(s,a)替代期望汇报会引入偏差。
3.2 A2C(Advantage Actor-Critic)
在QAC的基础上引入baseline来对偏差进行修正。使用优势函数乘上梯度对 θ \theta θ予以修正。
3.2.1 Baseline

3.2.2 Advantage function

3.2.3 Estimating the Advantage function
方式一:同时预测Q函数与V函数
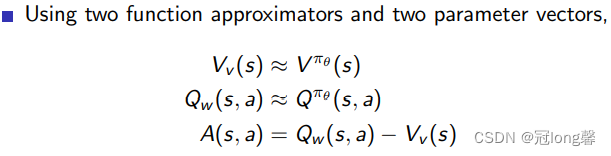
方式二:预测TD error
采用方式一需要预测Q, V两个网络,参数很多。我们可以通过公式 Q ( s , a ) = R s a + ∑ s ′ ∈ S P s s ′ V ( s ′ ) Q(s,a)=R_s^a+\sum_{s' \in S} P_{ss'}V(s') Q(s,a)=Rsa+∑s′∈SPss′V(s′)进行替代。

通过转换后就仅需要学习一个V网络的参数即可。
3.3 Summary

4. 附录
以下内容为笔记更新前的内容
4.1 演员、环境和奖励
(1)定义
- 演员就是一个网络,输入状态,输出动作。
- 环境就是一个函数,输入状态和动作,输出状态。
环境是基于规则的规则,是确定不变的。 - 奖励是在某一个状态下采取某个动作能够获得的分数。
环境是一个随机变量(因为状态和环境都是在一定分布下抽样获得的),我们可以计算的是奖励的期望值。
(2)某一个轨迹发生的概率
p θ ( τ ) = p ( s 1 ) p θ ( a 1 ∣ s 1 ) p ( s 2 ∣ a 1 , s 1 ) p θ ( a 2 ∣ s 2 ) p ( s 3 ∣ a 2 , s 2 ) ⋯ = p ( s 1 ) ∏ t = 1 T p θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











