







 本文介绍了深度学习入门阶段的内容,包括使用LLaVA进行模型量化的方法,HuggingFace的Trainer的使用和定制,以及如何通过LAVIS库自动下载数据集和配置yaml文件。此外,还讨论了多模态模型如CLIP和MedSAM的学习,以及遇到的一些常见技术问题和解决方法。
本文介绍了深度学习入门阶段的内容,包括使用LLaVA进行模型量化的方法,HuggingFace的Trainer的使用和定制,以及如何通过LAVIS库自动下载数据集和配置yaml文件。此外,还讨论了多模态模型如CLIP和MedSAM的学习,以及遇到的一些常见技术问题和解决方法。
深度学习入门stage2
- LLaVA学习
- LAVIS库学习
- NCCL_P2P_DISABLE=1
- 对比学习
- 多模态大模型
- CLIP学习
- MedSAM学习
- 记录一些bug
- TensorFlow学习
- Multi-modal Chatbot
- Mask2Former项目配环境踩坑
- 安装detectron2库
- 重新配置mask2former的环境
- 设置可见的device
- training_loop.py报错
- CUBLAS_STATUS_INTERNAL_ERROR:calling cublasSegmm
- CUDA error: device-side assert triggered
- CUDA_LAUNCH_BLOCKING
- Global alloc not supported yet. The following operation failed in the TorchScript interpreter.
- AttributeError: module 'distutils' has no attribute 'version'.
- xformers库安装
LLaVA学习
下载huggingface模型到linux服务器:
如何快速下载huggingface模型——全方法总结
【代码调试】We couldn‘t connect to ‘https://huggingface.co‘ to load this file问题解决
目前的解决方案是,先从huggingface镜像下载文件,然后把代码中的repo名改为本地路径。
finetune过程需要使用OCR-VQA数据集:
通过链接请求下载图像(以OCR-VQA数据集为例子)
peft的模型量化
将模型量化为4bit,使用LoRA训练:
# step1: 创建量化配置config: BitsAndBytesConfig
import torch
from transformers import BitsAndBytesConfig
config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
)
# step2: 用config构建预训练模型: from_pretrained
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", quantization_config=config)
# step3: 预处理量化模型: prepare_model_for_kbit_training
# 在训练transformer模型之前做一些预处理
from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)
# step4: 创建LoRA Config: lora_config
from peft import LoraConfig
lora_config = LoraConfig(
r=16,
lora_alpha=8,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05
bias="none",
task_type="CAUSAL_LM"
)
# step5: 由量化模型创建PeftModel: get_peft_model
from peft import get_peft_model
model = get_peft_model(model, lora_config)
huggingface的Trainer
Trainer包括基本训练循环中的所有代码:
- 执行训练步骤来计算损失
- backward计算梯度
- 根据梯度更新权重
- 重复此过程,直到达到预定的epoch数
指定训练超参数:TrainingArguments类。
Checkpoints
Trainer类将模型的 checkpoints 保存到 TrainingArguments 的 output_dir 指定文件夹中,checkpoint保存在 checkpoint-000子文件夹中,000表示训练step。保存 checkpoint 有助于恢复训练。
# 从最后的checkpoint中恢复
trainer.train(resume_from_checkpoint=True)
# 从指定的checkpoint中恢复
trainer.train(resume_from_checkpoint="path/checkpoint-000")
定制Trainer
重写
Trainer类的许多方法都可以进行子类化和重写,以支持你想要的功能,无需从头开始重写整个训练循环。
- get_train_dataloader()/ get_eval_dataloader()/ get_test_dataloader():创建对应的dataloader。
- log():记录观看训练的各种对象的信息。
- create_optimizer_and_scheduler()/ create_optimizer()/ create_scheduler():创建优化器和学习率调度程序,也可以在__init__()中传递。
- compute_loss()。
- training_step():执行training step。
- prediction_step():执行prediction_step。
- evaluate()。
- predict()。
回调
回调不会改变训练循环中的任何内容。 他们检查训练循环状态,然后根据状态执行一些操作(提前停止、记录结果等)。 回调不能用于实现自定义损失函数之类的东西,您需要为此子类化并重写compute_loss()方法。
继承 TrainerCallback 类,重写一个用于回调的类,传递给 Trainer 的参数callback。
Accelerate and Trainer
不懂。
DeepSpeed
比较好懂的博客:
DeepSpeed使用指南(简略版)
LAVIS库学习
自动下载并加载数据集
以coco caption数据集为例:
# 1. 下载coco images到Lavis库的cache路径下
python lavis/datasets/download_scripts/download_coco.py
# 2. load_dataset()获取数据集, 自动下载annotation files
coco_dataset = lavis.datasets.builders.load_dataset('coco_caption')
# 如果不需要自动下载, 可以传递vis_path参数为绝对路径
coco_dataset = load_dataset("coco_caption", vis_path=YOUR_LOCAL_PATH)
深入了解运行时配置文件yaml
一个yaml文件包括3大类,帮助我们在任务数据集上训练模型:
- model:指定模型架构。
- data:指定使用的数据集。
- run:指定运行时参数。
model配置
arch:指定模型架构。可在model_zoo中查询,如 blipInstruct支持2种模型架构,为blip2_vicuna_instruct和blip2_t5_instruct。model_type:因为同一个模型架构可以有不同的模型配置。如blip2_vicuna_instruct的模型配置为vicuna7b和vicuna13b,blip2_t5_instruct的模型配置为flant5xl和flant5xxl。load_finetuned:是否加载微调权重。对finetune task默认为False, 对evaluation默认为True。load_pretrained:是否加载预训练权重。对finetune task默认为True,对pretrain task默认为False。pretrained:存储预训练模型的URL或本地路径。fineuned:存储微调模型的URL或本地路径。
指定对应模型后,库将从对应的配置文件加载模型,如configs/models/blip2/blip2_instruct_flant5xl.yaml。
模型优先级:run config 优先级高于默认的 model config。
dataset配置
vis_processor和text_processor:处理数据集的视觉和文本输入。注册表机制,根据名称字符串动态加载处理器类。- 数据集名称:在注册表中,指向一个dataset builder类。默认情况下,会加载
DATASET_CONFIG_DICT中的默认数据集配置。 build_info:构建信息,包括annotations和images。annotations指定的文件将在第一次加载数据集时自动下载。images指定图像所在的根目录,默认为到cache directory的相对路径。如果要使用本地路径,可以在和build_info同级加一个images字段,来指定本地绝对路径。build_info下的annotations应该同时包括url、md5和storage3个字段,不论该数据集是否已经下载。因为代码会检查参数中的url和storage数量是否一致,且在download_url()中,通过md5检测是否已经存在storage的本地文件。
build_info:
annotations:
train:
# 表示从远程url下载json文件到本地的storage位置
# 若storage是相对路径, 则为cache root/storage
url: https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json
md5: aa31ac474cf6250ebb81d18348a07ed8
storage: coco/annotations/coco_karpathy_train.json
val:
url: https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_val.json
md5: b273847456ef5580e33713b1f7de52a0
storage: coco/annotations/coco_karpathy_val.json
test:
url: https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_test.json
md5: 3ff34b0ef2db02d01c37399f6a2a6cd1
storage: coco/annotations/coco_karpathy_test.json
images:
# 若想使用本地的绝对路径, 则应该提前下载, 并在storage参数写绝对路径, 从根目录写到images的所有路径
storage: /home/liusn/.cache/lavis/coco/images
runner配置
task:task名称,必须是lavis支持的task。lr_sched:学习率调度器。init_lr:warmup后的初始学习率。min_lr:decay后的最终学习率。warmup_lr:warmup的初始学习率。lr_decay_rate:每个epoch的学习率decay,适用于step_lr_schedule。warmup_steps:warmup策略的steps。max_epoch:训练epoch数。weight_decay:优化器的weight decay系数。batch_size_train:训练的batch size。batch_size_eval:验证的batch size。seed:随机种子。output_dir:输出ckpt、结果、logs的目录。resume_ckpt_path:resume训练要加载的ckpt路径。evaluate:是否仅执行evaluate,不执行train。train_splits:训练过程使用的数据集划分,默认为["train"]。valid_splits:验证过程使用的数据集划分,默认为["val"]。test:测试过程使用的数据集划分,默认为["test"]。device:使用cpu还是gpu,默认为cuda。world_size:参与工作的进程数,默认为1。dist_url:distributed:是否使用分布式训练,默认为True。amp:是否使用自动混合精度训练,默认为False。
添加数据集Datasets
使用lavis.datasets模块,定制新的数据集。包括创建数据集配置、定义和关联新数据集类别。
数据集配置
在lavis.configs.datasets中定义新的数据集配置,存储为一个yaml文件。
dataset_card:包含关于数据集的细节,如description、tasks、metrics,如dataset_card/avsd_dialogue.md。对于特定的数据集,dataset_card中要包含自动下载数据的命令,或者描述从原始数据源的下载指令。data_type:只能选择images、videos、features,前两者是原始数据,后者是指模型提取的视觉特征。build_info:数据被存储和缓存的具体位置。- 对于
text annotations,包括train、val、test。每一种split都包括url和storage。url为在线url或者数据集的本地目录,storage是缓存目录。 - 对于
visual annotations,字段名为images、val或test。一般只写一个storage参数,表示视觉数据缓存的目录。
- 对于
数据集Datasets
BaseDataset
定义一个新的数据集类来继承lavis.datasets.datasets.base_dataset。
默认情况下,使用BaseDataset类中的collator来collate数据样本。
Dataset Builder
新的数据集生成类都应该继承lavis.datasets.builders.base_dataset_builder.BaseDatasetBuilder类,BaseDatasetBuilder类中的标准方法build_datasets用于创建数据集类的实例,_downloaad_data用于下载数据。
在自定义的数据集构建器类中,定义DATASET_CONFIG_DICT把数据集配置和数据集类进行关联。
注册Builder:将新的构建器类加入lavis.datasets.builders.__init__.py中。
NCCL_P2P_DISABLE=1
对比学习
读过的博客:
对比学习损失(InfoNCE loss)与交叉熵损失的联系,以及温度系数的作用
对比学习(Contrastive Learning)概述
一文弄懂什么是对比学习(Contrastive Learning)
无监督学习:不受人类注释标签的监督。因此自监督学习是特殊的无监督学习。
注意:无监督学习只是不使用人类标签的监督,但是他会使用一种能够自我标注的标注数据。
对比学习是一种特殊的无监督学习,学习一个编码器,最大化相关样本之间的相似性,并且最小化不相关样本之间的相似性来学习数据表示。
对比学习的通用框架包括代理任务(如数据增强)和目标函数(损失函数)。
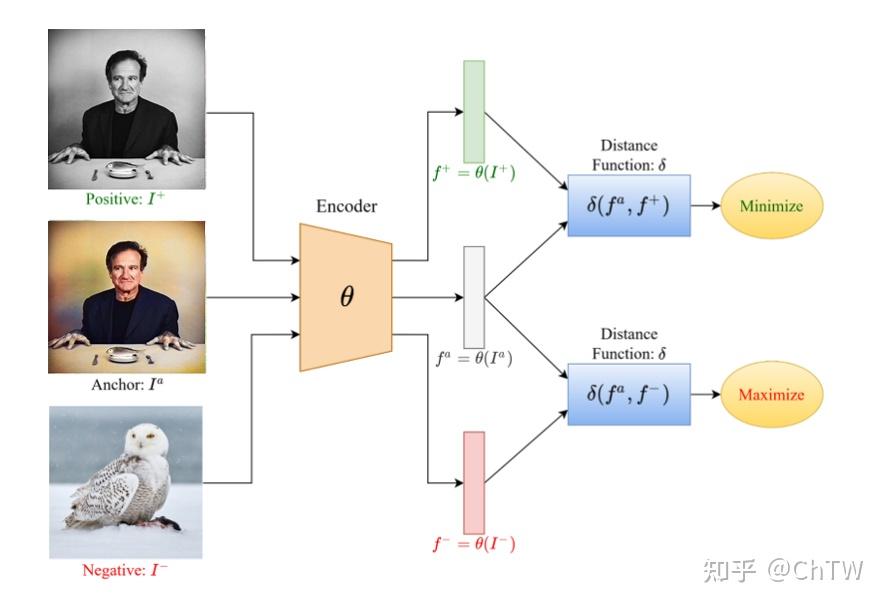
- Positive和Anchor组成正样本对,Negative和Anchor组成负样本对。Positive / Negtive不一定要与Anchor是同种数据类型。比如,Positive可以是对Anchor图片数据增强的结果,也可以是对应图片相关的一段文本。
- Positive、Negtive、Anchor经过同一个编码器,再经过不同的MLP层,得到3个输出。
- 再用损失函数(比如Info NCE Loss)来进行监督。
代理任务:我们为了做对比学习而定义出来的任务,一般包括个体判别和数据聚类。
- 个体判别:除了自身经过数据增强得到的图片是正样本外,其他都是负样本。
- 数据聚类:不同视角、传感器、多模态获取的同一对象的数据,都是正样本。
InfoNCE Loss(Noise Contrastive Estimation):InfoNCE Loss和交叉熵损失函数有点像,但是交叉熵的类别数指的是数据集里类别的数量,而InfoNCE Loss的类别数指的是负样本的数量。而这个负样本的数量是经过了负样本采样的。因为对比学习中,每个对象属于一类,所有种类数过大。只有通过采样,来减少种类数才可以。也就是说,Info NCE Loss就是一个交叉熵损失,做k+1类的分类任务,想把q这张图片分到k+这个类别。
InfoNCE Loss的公式如下:
(懒得写)
温度系数:一个超参数,可以用来控制logits(q·k)的分布形状。当T值变大,logits的分布会变得平滑,对比损失会对所有的负样本一视同仁。当T值变小,logits的分布会更peak,模型会更关注特别困难的负样本。因此,温度系数控制了模型对负样本的区分度。
多模态大模型
这是一篇好文章:
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读
CLIP学习
对CLIP代码的详细解读:
CLIP模型原理与代码实现详解
大batch对比学习的分布式实现:
【DDP】PyTorch多卡分布式训练 | all_gather | 大batch对比学习
MedSAM学习
跑MedSAM_Inference.py时报错:Qt缺失一个so库文件。解决方法如下:
Ubuntu18.04下解决Qt出现qt.qpa.plugin:Could not load the Qt platform plugin “xcb“问题
记录一些bug
执行命令conda create -n qllava2 --clone qllava时报错:CondaHTTPError: HTTP 000 CONNECTION。
解决CondaHTTPError: HTTP 000 CONNECTION 问题
我说呢,昨天才解决这个bug,今天怎么又出问题了。原来是我今天用的tmux设置了http_proxy。
TensorFlow学习
简单的模型训练的步骤:
- 创建计算图和与计算图关联的会话。
g = tf.Graph()
with tf.Session(graph=g) as sess:
- 定义模型结构、输入输出的占位符、优化器和损失函数、精度指标。
- 初始化全局变量。
# sess.run(): 执行计算图中的节点操作和获取节点的值
# 节点:operations或者tensors
sess.run(tf.global_variables_initializer())
# tf.global_variables_initializer():初始化所有全局变量的值, 按照初始化器initializer来初始化
# global variables: Tensorflow中被显式创建&&不属于任何特定范围的变量
- 在for循环里执行训练步骤。
# Session.run()
# 可以同时计算多个operation和Tensor的值
# feed_dict参数: 是前文定义的placeholder
# train_step属于operation, cross_entropy属于tensor
_,loss=sess.run([train_step,cross_entropy],{x: batch_xs, y_: batch_ys, keep_prob: 0.75})
# Tensor.eval(): 计算Tensor的值
# 不需要显式创建会话, 只能计算单个Tensor的值
acc=accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist.test.labels,keep_prob:1})
Multi-modal Chatbot
感谢这篇博客,非常有用!
python使用openai库0.x版本升级为1.x版本代码所需改动
Mask2Former项目配环境踩坑
安装detectron2库
参考博客:
detectron2安装(亲测好用)
把setup.py文件最后一行做修改。(虽然感觉maybe有用的不是这个)
Detectron2安装踩坑记录(比较详细版)
我的CUDA是11.1,运行:
# CUDA 11.1
python -m pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu111/torch1.9/index.html
顺利安装!
补充:因为自己可能需要修改detectron2的源码,所以将原始环境mask2former复制一份变成mask2former2,在mask2former环境里,执行pip uninstall detectron2,然后在pip install -e .重新安装好。
另一种解法:在命令行输入echo $CUDA_HOME查看CUDA_HOME的配置路径。发现报错原因是,CUDA_HOME直接赋值即可,不要加美元符。
重新配置mask2former的环境
按照官方readme操作:
conda create --name mask2former python=3.8 -y
conda activate mask2former
conda install pytorch==1.9.0 torchvision==0.10.0 cudatoolkit=11.1 -c pytorch -c nvidia
pip install -U opencv-python
# under your working directory
git clone git@github.com:facebookresearch/detectron2.git
cd detectron2
pip install -e .
pip install git+https://github.com/cocodataset/panopticapi.git
pip install git+https://github.com/mcordts/cityscapesScripts.git
cd ..
git clone git@github.com:facebookresearch/Mask2Former.git
cd Mask2Former
pip install -r requirements.txt
cd mask2former/modeling/pixel_decoder/ops
sh make.sh
需要做一些修改:
- 在创建环境之前,先把linux的CUDA版本修改成11.1。
- 安装pytorch、torchvision、cudatoolkit,不能用conda install,必须使用pip install,我用的命令是
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html。
设置可见的device
修改配置文件的参数cfg.MODEL.DEVICE='cuda:0,1'。
training_loop.py报错
升级pytorch从1.09.0–>1.10.0。
升级完之后报了新的错误:MultiScaleDeformableAttention处报错。先删掉编译好的C文件,然后重新编译C文件。
CUBLAS_STATUS_INTERNAL_ERROR:calling cublasSegmm
在脚本里修改CUDA_VISIBLE_DEVICES=0。
CUDA error: device-side assert triggered
报错位置:self.criterion(outputs, targets)
报错原因:num_classes设置错误,原始设置为65,修改为1。
CUDA_LAUNCH_BLOCKING
设置环境变量CUDA_LAUNCH_BLOCKING=1,使得CUDA操作可以同步执行,有助于debug的准确定位。
Global alloc not supported yet. The following operation failed in the TorchScript interpreter.
解决方案:当tgt_mask.shape[0]==0时,不用torch,jit.script()函数。
AttributeError: module ‘distutils’ has no attribute ‘version’.
解决方案:更新setuptools的版本,从72.1.0变成59.5.0。
xformers库安装
pip install xformers==0.0.19
xformers库的版本必须和pytorch版本严格对应。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









