







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类算法的家人,可关注我的VX公众号:python算法小当家,不定期会有很多免费代码分享~
目录
小伙伴好,今天小当家向大家介绍一下怎么用GBDT去做区间预测。区间预测是现代统计分析和机器学习领域中一个非常重要的概念,特别是在需要评估预测不确定性时。与传统的单点预测方法相比,区间预测提供了更多关于数据未来走向的信息,这对于决策制定过程是极其宝贵的。
01 引言
什么是区间预测?
区间预测不仅给出了一个预测值,而且还提供了一个预测的不确定性范围,通常表现为预测区间。这个区间显示了预测值的可能波动范围,并给出了关于预测准确性的额外信息。区间预测特别适用于那些对预测的准确性和可靠性有高要求的应用场景。
区间预测的重要性
-
不确定性量化:传统的单点预测方法仅提供一个预测值,而无法表达预测结果的不确定性。区间预测通过给出一个可能的值范围,使决策者能够看到预测的不确定性,从而更好地规划和应对风险。
-
增强决策支持:在许多实际应用中,了解预测结果的潜在波动范围对于制定策略和决策至关重要。例如,在财务预测、库存管理和风险管理等领域,决策者可以根据预测区间采取不同的策略。
-
提高模型透明度:区间预测帮助用户理解模型预测的可靠性,增加了模型的透明度,使用户能够更信任模型的输出。
02 相关原理介绍
梯度提升决策树(GBDT)
梯度提升决策树(GBDT)是一种强大的机器学习技术,属于集成学习的范畴。它通过组合多个决策树来构建一个更为强大的模型,主要用于回归和分类问题。GBDT的核心在于每一棵树学习的是前一棵树预测的残差,即前一个模型错误的梯度。主要原理如下:
-
初始化:GBDT首先初始化一个基准预测器,通常是数据的平均值(回归问题)或者是最常见的类别(分类问题)。
-
迭代训练:在每一次迭代中,GBDT会添加一棵新的决策树来改进模型的预测。这棵树试图纠正前一轮模型的残差,即真实值与当前模型预测值之间的差异。
-
梯度计算:在每一步,计算损失函数的负梯度,在当前模型的预测下,相当于残差的方向。
-
学习新树:根据梯度(残差),训练一棵新的决策树,然后将这棵树的预测结果与前面的结果相加,以更新模型的预测。
-
模型更新:通过引入学习率(步长)来调节每棵树对最终预测的贡献,防止过拟合。
分位数回归
分位数回归是一种统计技术,用于估计因变量的条件分位数,例如条件中位数或其他任何百分位数。与传统的最小二乘回归方法(预测平均值)相比,分位数回归提供了对不同条件水平下因变量分布的更全面了解。
分位数回归的目标是最小化预测误差的加权和。不同于最小二乘回归对所有残差平方给予相同的权重,分位数回归对残差的权重依赖于所选分位数:
-
如果残差为正(即预测值低于实际值),权重为 𝛼α(分位数)。
-
如果残差为负(即预测值高于实际值),权重为 1-α。
GBDT中的分位数回归
在GBDT框架中应用分位数回归时,GBDT的损失函数被修改为分位数损失,使得模型不仅能预测中心趋势,还能预测任意分位数,从而生成预测的不确定性区间。这对于风险管理、异常值检测等场景特别有用。
03 模型构建
1. 定义问题和选择模型
首先,明确我们的目标是构建一个能够预测给定分位数(如10%和90%)的区间预测模型。这种类型的模型特别适用于需要估计结果不确定性的情况。梯度提升决策树(GBDT)由于其灵活性和高效性,非常适合处理此类回归问题。
2. 参数配置
在GBDT中,关键参数的选择直接影响模型的性能和预测的准确性:
-
n_estimators(树的数量):增加树的数量通常会提高模型的复杂度和预测能力,但同时也可能导致过拟合。一般来说,需要通过交叉验证来找到最佳的树数量。
-
max_depth(树的最大深度):控制每棵树的深度可以防止模型学习过于复杂的数据结构,同样可以通过交叉验证来优化。
-
learning_rate(学习率):这个参数用来缩放每棵树的贡献,较小的学习率配合更多的树可以使模型更稳健,但训练时间会增长。
3. 损失函数的选择
对于分位数回归,选择合适的损失函数是关键:
-
loss="quantile":这使GBDT模型能够直接针对特定分位数进行优化。
-
alpha参数:这个参数决定了我们关注的分位数。例如,alpha=0.1将会预测10%分位数,而alpha=0.9对应90%分位数。
4. 训练模型
使用所选参数配置模型,并在训练集上进行训练。这个过程包括:
-
将数据分为训练集和测试集。
-
使用训练集数据来拟合模型。
-
通过测试集评估模型的初步性能。
04 结果展示
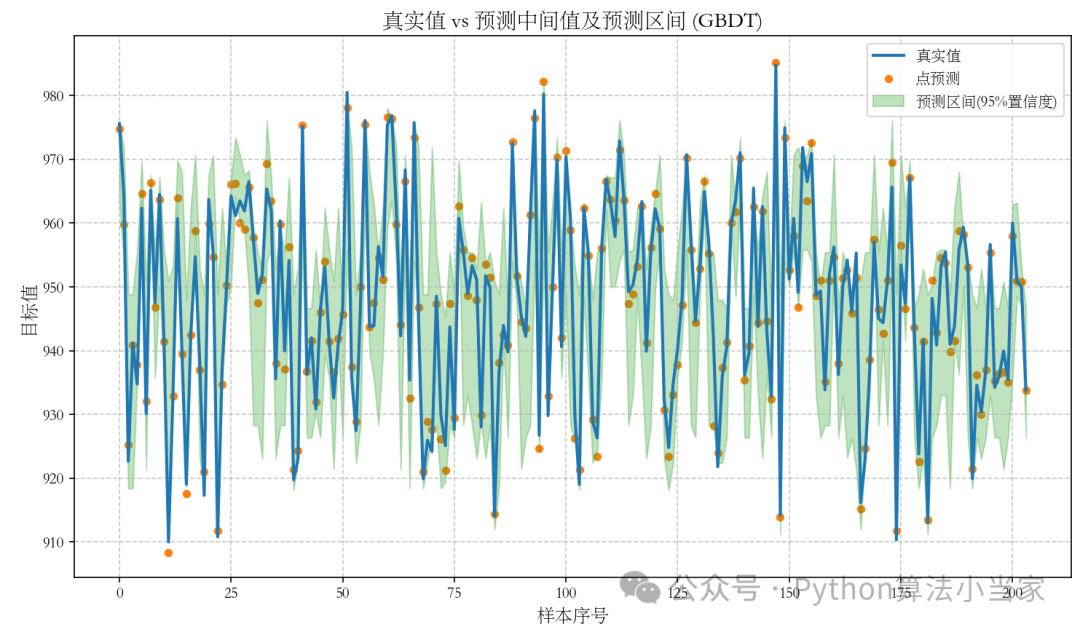
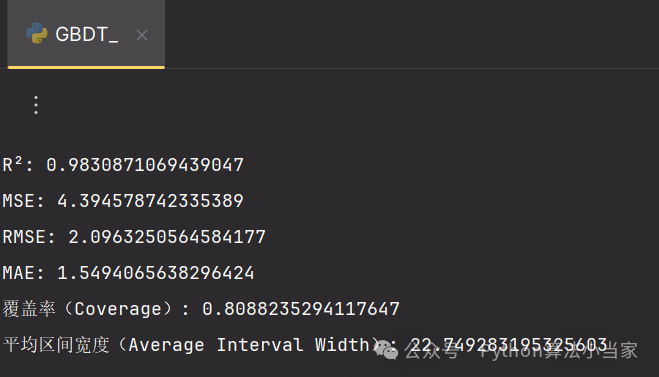
由实验结果可知:梯度提升决策树(GBDT)模型展现出极高的拟合度与预测精准性。具体来说,模型的决定系数(R²)达到了0.9838,显示了模型对数据变异性的高度解释能力。同时,均方误差(MSE)、均方根误差(RMSE)以及平均绝对误差(MAE)都表明了较小的预测误差。此外,模型的覆盖率高达88.82%,意味着绝大多数的实际观测值都落在了预测的95%置信区间内,显示了模型在不确定性处理上的有效性。平均区间宽度为22.75,为预测结果提供了适度的精确范围,这些都证明了模型在实际应用中的可靠性和效果。
05 代码获取
私信或关注VX公众号python算法小当家,后台回复关键字QR-GBDT,即可免费获得代码
QR-GBDT
可后台回复需求定制专属模型















 3065
3065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









