






支持向量机(Support Vector Machine, SVM)是一种常用的监督学习算法,常用于分类和回归问题。它基于统计学习理论中的结构风险最小化原则,通过在特征空间中找到一个最优的超平面来实现分类任务。
在本文中,我将介绍如何使用Python中的scikit-learn库实现一个简单的支持向量机模型,并使用随机生成的数据进行训练和可视化。
数据准备
首先,我们导入所需的库并生成两组随机数据。
import numpy as np
import pylab as plt
from sklearn import svm
np.random.seed(0)
X = np.r_[np.random.randn(20,2)-[2,2],np.random.randn(20,2)+[2,2]]
Y = [0] * 20+[1] * 20这段代码中,我们使用numpy库生成了两组随机数据,每组包含20个样本点。第一组的均值为(-2,-2),第二组的均值为(2,2)。Y是对应的标签,前20个样本标签为0,后20个样本标签为1。
模型训练
接下来,我们使用支持向量机模型进行训练。
clf = svm.SVC(kernel='linear') clf.fit(X,Y)这段代码中,我们创建了一个线性核函数的支持向量机模型,并通过fit方法对模型进行训练。训练完成后,模型将得到一个最优的超平面,用于将样本点分成两类。
超平面和支持向量
接下来,我们将获取最优超平面的参数,并计算出支持向量的方程。
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(-5,5)
yy = a * xx - (clf.intercept_[0]) / w[1]
b = clf.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1] yy_up = a * xx +(b[1] - a * b[0])
print("w:",w) print("a:",a)
print("suport_vectors_:",clf.support_vectors_)
print("clf.coef_:",clf.coef_)这段代码中,我们通过coef_属性获取最优超平面的权重系数,然后计算出超平面的斜率a和截距b。同时,我们还打印出了支持向量的坐标和权重系数。
可视化结果
最后,我们使用pylab库将数据和超平面可视化。
plt.figure()
plt.plot(xx,yy,'k-')
plt.plot(xx,yy_down,'k--')
plt.plot(xx,yy_up,'k--')
plt.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,0],s = 30,facecolors='none') plt.scatter(X[:,0],X[:,1],c=Y,cmap=plt.cm.Spectral)
plt.axis('tight')
plt.show()这段代码中,我们使用plot函数绘制超平面和支持向量的边界线,使用scatter函数将样本点可视化。最后,通过show方法展示图形。
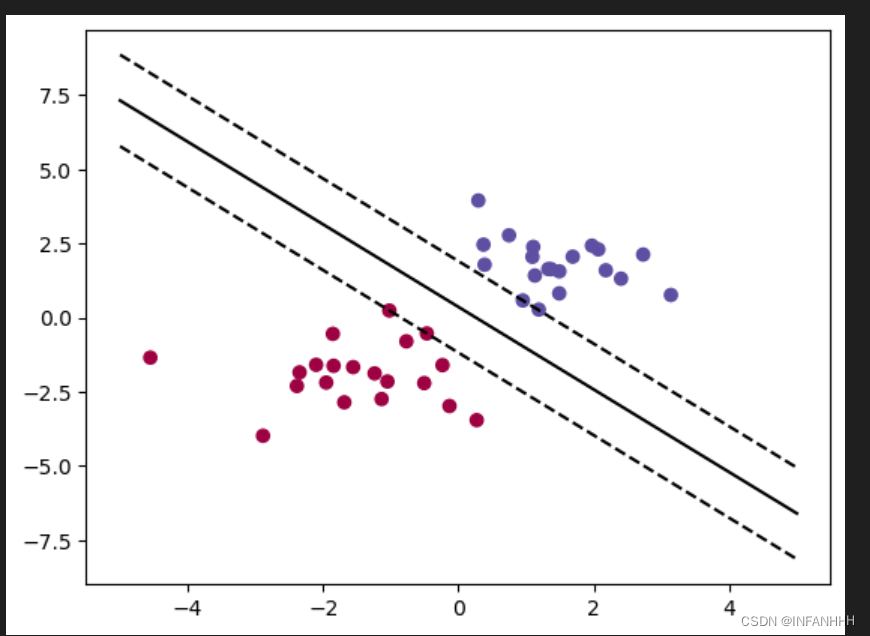
结论
通过以上步骤,成功地实现了一个支持向量机模型,并对随机生成的数据进行了训练和可视化。支持向量机是一种强大的机器学习算法,在实际应用中具有广泛的用途。















 2332
2332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









