






 本文介绍了图像翻译的基本概念,着重讲解了条件生成对抗网络(CGAN)和U-Net在图像转换中的应用,以及Pix2Pix模型如何利用U-Net和PatchGAN进行图像到图像的翻译。讨论了损失函数的调整和网络结构的设计,展示了Pix2Pix在图像处理中的关键点和优化策略。
本文介绍了图像翻译的基本概念,着重讲解了条件生成对抗网络(CGAN)和U-Net在图像转换中的应用,以及Pix2Pix模型如何利用U-Net和PatchGAN进行图像到图像的翻译。讨论了损失函数的调整和网络结构的设计,展示了Pix2Pix在图像处理中的关键点和优化策略。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
一、背景知识
1.1 图像翻译
图像翻译指的是将图像从源域转换到目标域的过程,同时保持图像内容的一致性。具体解释如下:
图像内容(Content):这是图像的固有属性,指的是图像展示的对象、场景或任何其他可视化信息。图像内容是区分不同图像的主要依据。
图像域(Domain):在图像翻译的背景下,一个域可以被认为是一组具有共同特征的图像。例如,所有带有蓝色天空的照片可以属于同一个域。在图像翻译中,通常涉及至少两个域:源域和目标域。域内的图像可以认为其内容被赋予了某些相同的风格、纹理或其他视觉特性。
图像翻译(Image-to-Image Translation, I2I):这是一个过程,目的是将图像从一个域(源域)转换到另一个域(目标域),同时尽可能保留原始图像的内容。这涉及到一系列复杂的算法和模型,如生成对抗网络(GANs),它们能够捕捉并学习不同域之间的映射关系。这个过程在计算机视觉和图像处理领域有着广泛的应用,包括图像风格转换、草图着色、照片卡通化等。
1.2 CGAN
条件生成对抗网络(CGAN)是在生成对抗网络(GAN)的基础上进行了一些改进。对于原始GAN的生成器而言,其生成的图像数据是随机不可预测的,因此我们无法控制网络的输出,在实际操作中的可控性不强。
针对上述原始GAN无法生成具有特定属性的图像数据的问题,Mehdi Mirza等人在2014年提出了条件生成对抗网络,通过给原始生成对抗网络中的生成器G和判别器D增加额外的条件,例如我们需要生成器G生成一张没有阴影的图像,此时判别器D就需要判断生成器所生成的图像是否是一张没有阴影的图像。条件生成对抗网络的本质是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,旨在把无监督学习的GAN转化为有监督学习的CGAN,便于网络能够在我们的掌控下更好地进行训练。CGAN网络结构如下图所示。

由上图的网络结构可知,条件信息y作为额外的输入被引入对抗网络中,与生成器中的噪声z合并作为隐含层表达;而在判别器D中,条件信息y则与原始数据x合并作为判别函数的输入。这种改进在以后的诸多方面研究中被证明是非常有效的,也为后续的相关工作提供了积极的指导作用。
原始GAN包含一个生成器和一个判别器,其中生成器G和判别器D进行极大极小博弈,损失函数如下:

CGAN添加的额外信息y只需要和x与z进行合并,作为G和D的输入即可,由此得到了CGAN的损失函数如下:

1.3 U-Net
U-Net是一种专为图像分割任务设计的深度学习网络结构,具有以下特点:
编码器-解码器(Encoder-Decoder)结构:U-Net由一个收缩路径(编码器)和一个对称的扩展路径(解码器)组成。编码器部分主要负责通过卷积层提取特征,而解码器部分则用于上采样特征图,逐步恢复到原始图像的尺寸。
跳跃连接(Skip Connections):在编码和解码阶段之间存在跳跃连接,即从编码器到解码器的深层特征图会与解码器相应层次的输出进行拼接。这种设计可以帮助保持图像的细节信息,并有助于更好地进行精确的分割。
多层次特征融合:U-Net结构允许在不同层级的特征之间进行融合,这样可以让网络同时学习到浅层次的细节特征和深层次的语义特征,从而增强模型对不同尺度结构的识别能力。
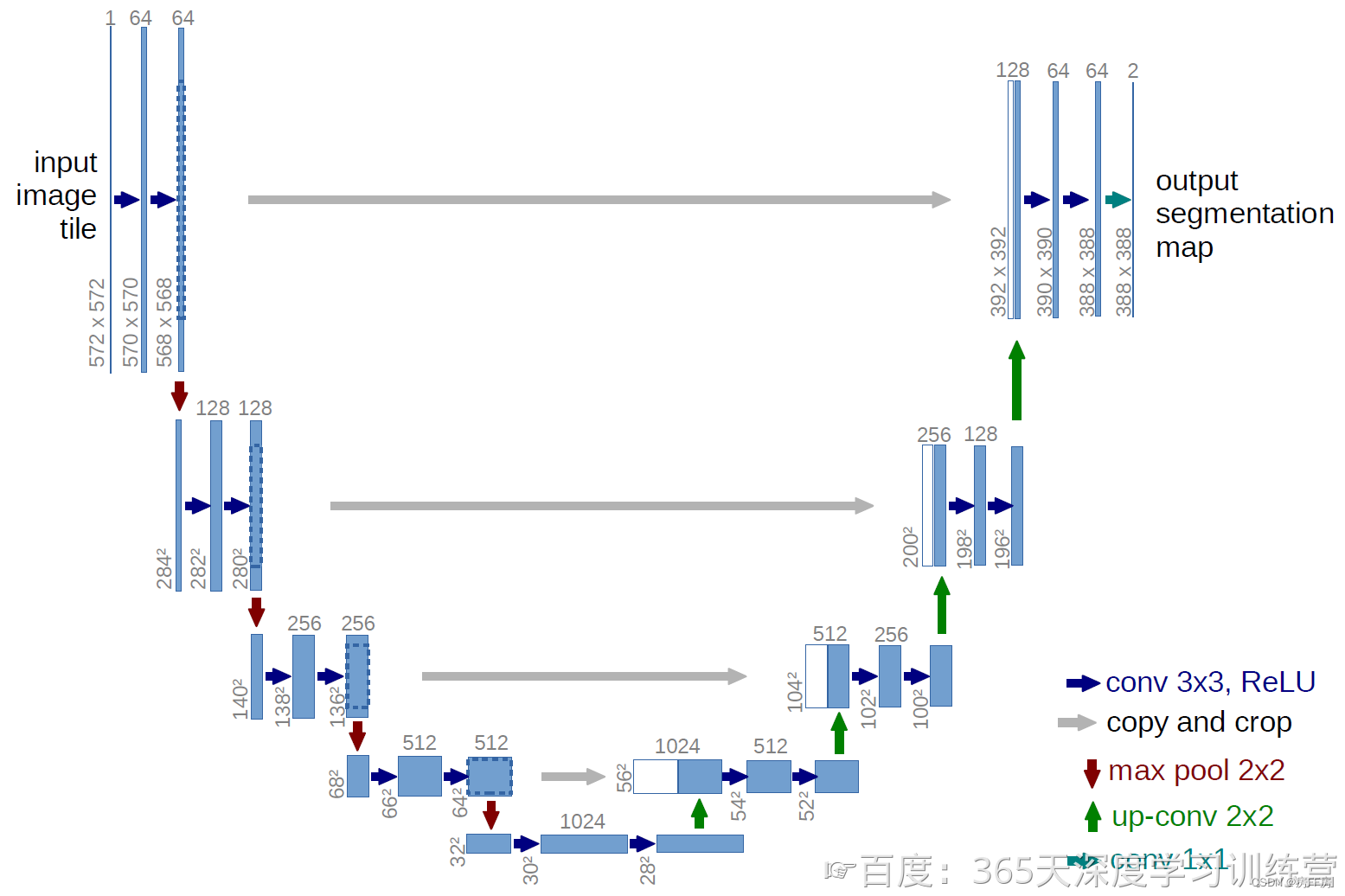
分割任务是图像翻译任务的一个分支,因此U-Net也可以被用作其它的图像翻译任务,这里要介绍的Pix2Pix便是采用了U-Net作为主体结构。
二. pix2pix解析
Pix2pix 是借鉴了 cGAN 的思想。cGAN 在输入 G 网络的时候不光会输入噪音,还会输入一个条件(condition),G 网络生成的 fake images 会受到具体的 condition 的影响。那么如果把一副图像作为 condition,则生成的 fake images 就与这个 condition images 有对应关系,从而实现了一个 Image-to-Image Translation 的过程。Pixpix 原理图如下:

Pix2pix 的网络结构如上图所示,生成器 G 用到的是 U-Net 结构,输入的轮廓图x编码再解码成真实图片,判别器 D 用到的是作者自己提出来的条件判别器 PatchGAN ,判别器 D 的作用是在轮廓图x的条件下,对于生成的图片 G(x)判断为假,对于真实图片判断为真。
2.1损失函数
因为 Pix2Pix 和 CGAN 的输入数据不同了,所以它们的损失函数也要对应的进行调整,根据前面的定义,CGAN表示为下式。

我们可以在损失函数中加入正则项来提升生成图像的质量,不同的是Pix2Pix使用的是L1正则而不是L2正则,使用L1正则有助于使生成的图像更清楚。

我们最终目标是在正则约束情况下的生成器和判别器的最大最小博弈:

GAN其实是一种相对于 L1 loss 更好的判别准则或者loss。有时候单独使用GAN loss效果好,有时候与L1 loss配合起来效果好。在pix2pix中,作者就是把L1 loss 和GAN loss相结合使用,因为作者认为L1 loss 可以恢复图像的低频部分,而GAN loss可以恢复图像的高频部分。
2.2 模型结构
生成器采用U-Net网络结构,融合底层细粒度特征和高层抽象;判别器采用patchGAN网络结构,在图块尺度提取纹理等高频信息。
2.2.1 生成器
生成器是一个U-Net网络结构,也是图像分割领域常用的一个网络,特点是结构像U型一样。U-Net的结构先是一个编码器Encoder,然后是一个解码器decoder。编码器的话先逐层下采样,中间是一个维度很小瓶颈层,再逐层的上采样,上采样和下采样是对称的,输入一张图再生成另外一张大小一样的图。这样的话所有的信息流都会被逼得流过瓶颈层,而瓶颈层的维度又很小,所以就不可避免地会带来信息的丢失。为了避免这一问题呢,U-Net在对称的层都引入了一个跳转连接skip connection,通俗理解skip connection就是抄近道,能够把底层的像素级别的特征融合到高层,这样就可以充分利用好底层特征(底层特征是极其重要滴)。如何对信息进行融合腻,直接沿通道方向摞起来就可以啦,摞起来再输入下一层进行卷积处理。

1、Pix2Pix使用的是以U-Net为基础的结构,即在压缩路径和扩张路径之间添加一个跳跃接;
2、Pix2Pix的输入图像的大小是 256 × 256 × 3 256×256×3256×256×3 ;
3、每个操作仅进行了三次降采样,每次降采样的通道数均乘以2,初始的通道数是64;
4、在压缩路径中,每个箭头表示的操作是卷积核大小为 4×4 的same卷积+BN+ReLU,它根据是否降采样来控制卷积的步长;
5、在扩张路径中,它使用的是反卷积上采样;
6、压缩路径和扩张路径使用的是拼接操作进行特征融合。
2.2.2判别器(PatchGAN)
判别器呢在努力地分辨照片的真假。生成器生成的假照片和这个输入会组成一对图像喂给判别器,判别器如果足够优秀的话,应该会给这一对图像判成假;若再把真实的照片和这个输入一起喂给判别器的话,好的判别器应该会给这一对判别为真。所以发现了没,判别器其实也是一个二分类模型,只不过它输入的是图像对,而不是单张图像,它判断的是这一对是真是假🤔🤔🤔
判别器的名字叫马尔科夫判别器,马尔科夫的意思是说patch之间是互相独立的,就符合马尔科夫假设嘛。为了让判别器去捕捉高级特征,就使用到了局部小图块的尺度进行判别,这就叫做PatchGAN。也就是把整个图分成n×n的网格,然后对每一个网格来做二分类,PatchGAN对每一小块的纹理、颜色辨别真伪,来判定里面的图是真图还是假图。这样的好处就是可以全卷积的运行每一张图像,把n×n的每个结果加起来做平均,就可以得到对整张图像的判别结果。
传统GAN的一个棘手的问题是它生成的图像普遍比较模糊,一个重要的原因是它使用了整图作为判别器的输入。不同于传统的将这个图作为判别器判别的目标(输入),Pix2Pix提出了将输入图像分成 N×N 个图像块(Patch),然后将这些图像块依次提供给判别器,因此这个方法被命名为 PatchGAN ,PatchGAN可以看做针对图像纹理的损失。
当 N=70 时模型的表现最好,但是从生成图像来看, N 越大,生成的图像质量越高。其中 1×1 大小的图像块的判别器又被叫做 PixelGAN 。

三.代码运行


















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











