






什么是模型评估方法
模型评估方法是用于评估机器学习模型性能的一系列技术、策略和指标。在模型训练过程中,我们通常使用一部分数据(如训练集、验证集和测试集)来训练模型,然后使用另一部分数据(如测试集或实际应用中的数据)来评估模型的性能。评估方法的目的在于了解模型的预测能力,找出模型可能存在的问题(如过拟合或欠拟合),并调整模型的超参数以优化性能。
常用的模型评估方法
1. 数据集划分:将数据集划分为训练集、验证集和测试集,用于训练模型、调整超参数以及评估模型性能。
2. 交叉验证:一种统计学方法,通过将数据集划分为多个子集(通常为 k 折交叉验证),并在每次迭代中使用一个子集作为验证集,其余子集作为训练集,以评估模型的性能。
3. 混淆矩阵:一种可视化方法,用于展示二分类模型中的分类结果。混淆矩阵包含四个元素:真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。通过混淆矩阵,我们可以计算其他评估指标,如准确率、精确率、召回率和 F1 分数等。
4. 评估指标:用于衡量模型性能的指标,如准确率、精确率、召回率和 F1 分数等。这些指标可以帮助我们了解模型的优缺点,并选择最佳的模型。
常见模型指标
模型评估指标是用于衡量机器学习模型性能的各种指标,这些指标可以帮助我们了解模型的优缺点,并选择最佳的模型。以下是一些常用的模型评估指标:
1. 准确率(Accuracy):表示模型预测正确的样本数占总样本数的比例。准确率适用于类别平衡的情况,如果类别不平衡,准确率可能会有偏。
2. 精确率(Precision):针对预测结果而言,表示被模型预测为正例的样本中真正为正例的比例。精确率适用于关注假阳性(False Positive)的情况。
3. 召回率(Recall):针对实际情况而言,表示实际为正例的样本中被模型预测为正例的比例。召回率适用于关注假阴性(False Negative)的情况。
4. F1 分数(F1-score):精确率和召回率的调和平均,它可以综合评价模型的性能。
5. 混淆矩阵(Confusion Matrix):一种可视化方法,用于展示二分类模型中的分类结果。混淆矩阵包含四个元素:真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。通过混淆矩阵,我们可以计算其他评估指标,如准确率、精确率、召回率和 F1 分数等。
6. ROC 曲线(Receiver Operating Characteristic Curve):用于评估二分类模型在区分正负例方面的性能。ROC 曲线上的面积(AUC,Area Under Curve)可以作为模型性能的度量指标。
7. PR 曲线(Precision-Recall Curve):用于评估模型的精确率和召回率。PR 曲线上的面积(AUC,Area Under Curve)也可以作为模型性能的度量指标。
8. 对数损失(Log Loss):适用于二分类问题,是分类问题中常用的一种损失函数。
9. 分类报告(Classification Report):包括模型分类的详细信息,如精确率、召回率、F1 分数等。
这些指标可以帮助我们全面了解模型的性能,选择最佳的模型,并调整模型的超参数以优化性能。
代码实现
from sklearn.datasets import make_classification
from sklearn.metrics import precision_score,recall_score,roc_auc_score,f1_score,accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
"生成一个二分类数据"
#n_samples代表生成数量,n_calss代表分类类型,random_state代表随机种子
X,y=make_classification(n_samples=2000,n_classes=2,random_state=42)
"""
生成训练集和测试机
"""
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42,test_size=0.2)
"""
训练逻辑回归模型
"""
logistci=LogisticRegression(random_state=42)
logistci.fit(X_train,y_train)
"""
预测
"""
y_pre=logistci.predict(X_test)
# print(y_pre)
"""
模型评估
"""
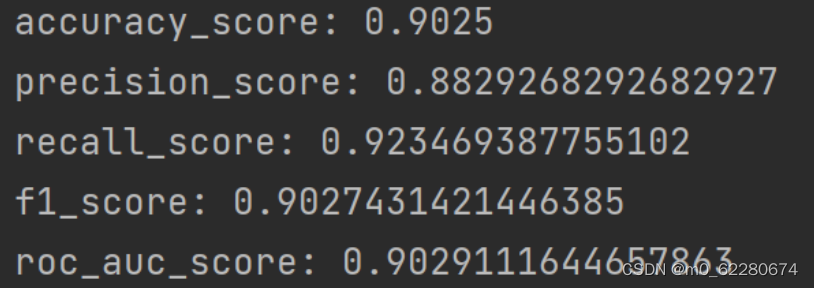
accuracy_score=accuracy_score(y_test,y_pre)
print("accuracy_score:",accuracy_score)
precision_score=precision_score(y_test,y_pre)
print('precision_score:',precision_score)
recall_score=recall_score(y_test,y_pre)
print('recall_score:',recall_score)
f1_score=f1_score(y_test,y_pre)
print('f1_score:',f1_score)
roc_auc_score=roc_auc_score(y_test,y_pre)
print("roc_auc_score:",roc_auc_score)
总结:
在实际应用中,随着模型的不断变化,我们的实际情况变化也要随着当时的情况而调整,而不是一味的套用,这样才能达到我们想要的效果















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









