







数据集查找
我从kaggle等多个平台上搜集到了一些免费的数据集:

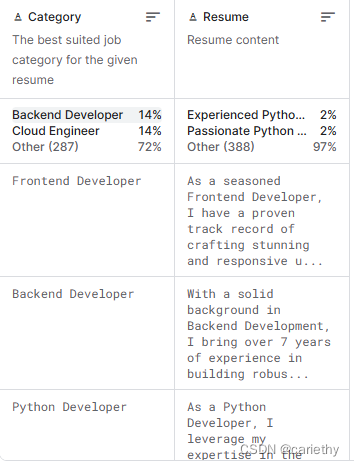
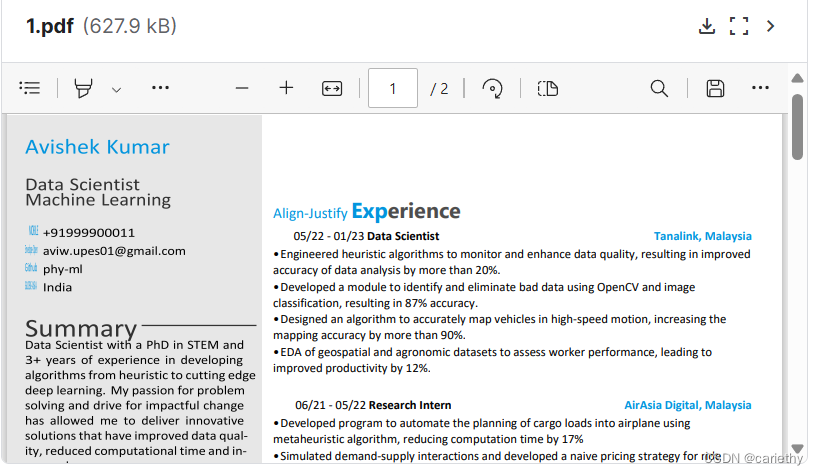
六个数据集中,两个简历模板(pdf),四个简历问题,其中一个带回答,详情如下:
数据预处理
数据预处理是指在进行数据分析和建模之前,对原始数据进行清洗、转换、集成和规约等操作的过程。数据预处理的目的是提高数据的质量,使数据更加适合进行分析和建模。
数据预处理包括以下几个方面:
数据清洗:去除重复数据、处理缺失值、去除异常值等。
数据转换:将数据从一种格式转换为另一种格式,例如将文本数据转换为数值型数据。
数据集成:将来自不同数据源的数据进行整合,例如将不同表格中的数据进行合并。
数据规约:对数据进行压缩、抽样等处理,以便于存储和处理。
数据预处理的重要性在于,原始数据往往存在各种问题,例如缺失值、异常值、重复值等,这些问题会影响到后续的分析和建模。因此,在进行数据分析和建模之前,需要对原始数据进行预处理,以提高数据质量和分析效果。
处理缺失值
处理缺失值的方法主要有以下几种:
删除缺失值:如果缺失值的数量很少,可以考虑直接删除包含缺失值的记录。但是,如果缺失值的数量占比较大,直接删除可能会导致数据量减少,影响建模效果。
填充缺失值:另一种方法是填充缺失值。填充的方法包括均值填充、中位数填充、众数填充等。这种方法可以保留原始数据,但是可能会对数据分布产生影响。
插值法:插值法是一种更加精细的填充方法,它可以根据数据的分布特征来预测缺失值。常见的插值方法包括线性插值、多项式插值、样条插值等。
模型预测:如果缺失值较多,可以考虑使用模型来预测缺失值。例如,可以使用回归模型、决策树模型等来预测缺失值。
需要注意的是,不同的处理方法对数据的影响不同,选择合适的方法需要根据具体情况进行评估。同时,需要注意处理缺失值可能会对数据分布产生影响,因此需要对数据进行分析和建模之前进行充分的预处理。
import pandas as pd
import numpy as np
data=pd.DataFrame([[8.3,6,],[9.3,4,],[6,8,8],[5,6],[3,1,8]],columns=('a','b','c'))
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(data.isnull()))
print(data)
# 删除法之变量删除
data.drop(["c"],axis =1 ,inplace=True)
print(data)# 删除法之记录删除
data=data.dropna(axis=0,how='any')处理异常值
处理异常值的方法主要有以下几种:
删除异常值:如果异常值的数量很少,可以考虑直接删除包含异常值的记录。但是,如果异常值的数量占比较大,直接删除可能会导致数据量减少,影响建模效果。
替换异常值:另一种方法是替换异常值。替换的方法包括中位数替换、均值替换、分位数替换等。这种方法可以保留原始数据,但是可能会对数据分布产生影响。
分箱处理:将数据分成若干个箱子(bin),对每个箱子进行统计分析,可以有效地处理一些离群点。
使用模型:如果异常值较多,可以考虑使用模型来预测异常值。例如,可以使用回归模型、决策树模型等来预测异常值。
需要注意的是,不同的处理方法对数据的影响不同,选择合适的方法需要根据具体情况进行评估。同时,需要注意处理异常值可能会对数据分布产生影响,因此需要对数据进行分析和建模之前进行充分的预处理。
归一化
数值的归一,丢失数据的分布信息,对数据之间的距离没有得到较好的保留,但保留了权重。
1.小数据/固定数据的使用;2.不涉及距离度量、协方差计算、数据不符合正态分布的时候;3.进行多指标综合评价的时候。
将数值规约到(0,1)或(-1,1)区间。
import pandas as pd
import numpy as np
data=pd.DataFrame([[8.3,6],[9.3,4],[6,8],[3,1]])
print(data)
data[0]=(data[0]-data[0].min())/(data[0].max()-data[0].min())
data[1]=(data[1]-data[1].min())/(data[1].max()-data[1].min())
print(data)标准化
import numpy as np
from sklearn.preprocessing import StandardScaler
data=np.array([[2,2,3],[1,2,5]])
print(data)
print()
scaler=StandardScaler()
# fit函数就是要计算这两个值
scaler.fit(data)
# 查看均值和方差
print(scaler.mean_)
print(scaler.var_)
# transform函数则是利用这两个值来标准化(转换)
X=scaler.transform(data)
print()
print(X)














 7196
7196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









