







我接下来主要负责我们项目的数据集的收集与清洗,数据来源研究: 搜集计算机、考公,教资,银行,企业管理行业领域的面试问题、回答、以及相关资料。主要通过搜集相关真题和爬取开源数据和手动收集面试相关问题的答案和解答技巧。
在之前我搜集了计算机领域的数据集,接下来将在考公,教资,银行,企业管理四个行业和领域收集相关数据。
公考问答
我在一些公考平台山搜集到了往年的面试真题,这些是未经过处理的原始数据,在之后的步骤中将对他们进行处理,标准化成符合json的数据集。
中公教资资料
同样,我在这些平台山也搜集到了往年的教资考试面试真题,这些是未经过处理的原始数据,在之后的步骤中将对他们进行处理,标准化成符合json的数据集。
银行面试问答数据爬取
由于银行面试的数据比较难搜集到,我尝试从以下几个网址爬取数据
https://zhuanlan.zhihu.com/p/693244923
银行面试“10个常见问题”怎么回答? - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/693244923
银行面试经典50题,五大行都这么问! - 知乎 (zhihu.com)
爬虫代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 定义要爬取的URL
base_url = "https://zhuanlan.zhihu.com/p/693244923"
# 发起HTTP请求获取网页内容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(base_url, headers=headers)
response.encoding = 'utf-8'
html = response.text
# 解析网页内容
soup = BeautifulSoup(html, 'html.parser')
# 提取面试问答相关内容
questions = []
answers = []
# 这里假设问题和答案的HTML结构如下所示
for item in soup.find_all('div', class_='List-item'):
question = item.find('h2').get_text(strip=True)
answer = item.find('span', class_='RichText').get_text(strip=True)
questions.append(question)
answers.append(answer)
# 存储数据到DataFrame
df = pd.DataFrame({'QuestionID': range(1, len(questions) + 1), 'Question': questions, 'Answer': answers})
# 保存到本地文件
df.to_csv('bank_interview_questions.csv', index=False, encoding='utf-8')
print("数据爬取并保存成功")
处理反爬机制
为了更高效和更安全地爬取数据,考虑使用以下方法:
- 使用User-Agent:模拟浏览器请求。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(base_url, headers=headers)
使用代理IP:避免IP被封。
proxies = {
'http': 'http://your_proxy_ip:port',
'https': 'http://your_proxy_ip:port',
}
response = requests.get(base_url, headers=headers, proxies=proxies)
设置请求间隔:避免频繁请求导致被封禁。
import time
for page in range(1, 10):
url = f"https://www.zhihu.com/search?type=content&q=银行面试%20问答&page={page}"
response = requests.get(url, headers=headers)
# 爬取和处理数据
time.sleep(2) # 等待2秒
数据集结构示例
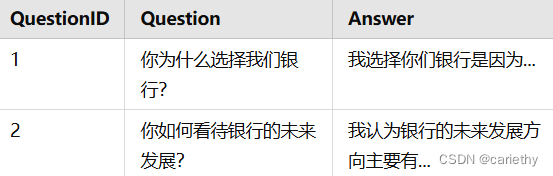
企业管理行业领域的面试问题
我主要从以下几个网址等爬取数据
知乎盐选 | 第 13 章 管理类岗位的面试问题 (zhihu.com)
【关于企业管理-甄选4个面试问题:区分差不多的人】 - 知乎 (zhihu.com)
数据集结构示例
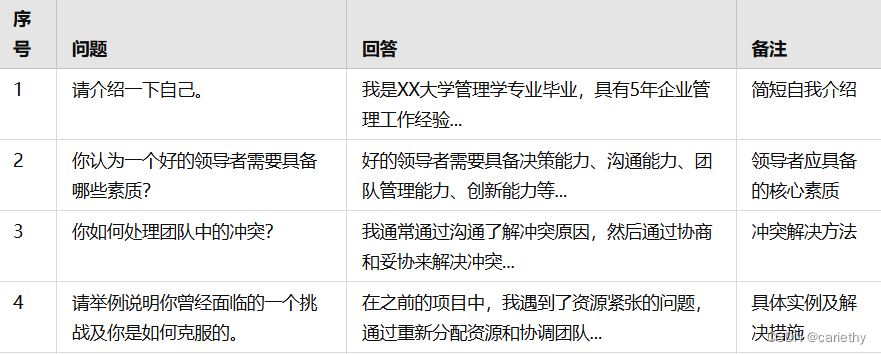
MBTI性格分析数据爬取
我主要从以下几个网址等爬取数据
Myers & Briggs Foundation (myersbriggs.org)
themyersbriggs.com/en-US/Select-Country
Free personality test, type descriptions, relationship and career advice | 16Personalities
等等
数据集结构示例

综上,我得到了一个庞大的数据集















 7196
7196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









