






目录
介绍
本文研究的领域是半监督语义分割,半监督的意思就是利用少量的有标注数据和大量的无标注据实现语义分割任务。
目前半监督的难点在于网络从有标注数据和无标注数据中学习到的分布不一致,或者说没有学习到共同的语义特征,从下图可以看出。在半监督任务中解决这个问题的一种办法是采用对称的方法来使用两种数据,从而保持两个分布之间的一致性。比如使用Mean Teacher和self-training,这也是本文采用的框架。

CutMix(CP)


CutMix是一种数据增强的手段,如上图展示,把一张图片裁剪下来一块覆盖到另一张图上。
之前的半监督方法使用CutMix的方法仅仅在有标注数据间或者无标注数据间使用,这种分别处理两种数据的方法,没有在两种数据之间建立一致性,所以就还是会导致分布的差异。而本文提出的方法是在两种数据之间使用CutMix,另外本文把CutMix叫做Copy-Paste(CP)。
方法

网络和训练方法
采用了教师和学生两个相同的网络。首先用有标注数据对教师网络预训练,预训练时采用CP数据增强(实验证明这样比不使用数据增强或不预训练效果好)。 然后利用教师网络对无标注数据产生伪标签作为它的标注,和有标注数据一起通过特定的损失函数训练学生网络。 训练时每次迭代还要利用EMA(指数移动平均)更新教师网络的参数,公式如下,期间教师网络不产生梯度,不通过梯度下降更新参数。 训练好之后测试时只使用学生网络。

双向Copy-Paste
这里是本文的核心。在有标注数据和无标注数据之间互相PC,被称作双向的BPC,重在一个双向。
根据网络结构图,首先分别从有标注数据和无标注数据各取两张图片{Xi, Xj}和{Xp, Xq},共四张。
第一组把Xi随机裁剪出一个patch覆盖到Xq上,即把有标注的图片的一部分作为无标注的前景,得到Xout。
第二组把Xp随机裁剪出一个patch覆盖到Xj上,即把无标注的图片的一部分作为有标注的前景,得到Xin。
这里假设裁剪下的patch是图片中的前景,当然这并不对所有样本都成立。
Xout和Xin通过学生网络得到预测Qout和Qin,两张无标注的图片Xp和Xq通过预训练的教师网络得到伪标签Yp和Yq。因为Xin和Xout都由有标注图片和无标注图片两部分构成,所以它的对应的标注图片也由两部分组成,属于无标注的那一部分要从伪标签上裁剪过来,属于有标注的那部分从标注Yi和Yj裁剪过来。 或者说,由{Xi, Xj}和{Xp, Xq}生成的输入Xin和Xout的过程与由标签{Yi, Yj}和伪标签{Yp, Yq}生成Yin和Yout的操作是相同的。公式如下,M是0-1mask,中心是0,四周是1。


损失函数
Lseg损失就是分割的损失函数,同时使用了交叉熵和Dice loss,然后Qin和Qout的损失相加。
在对预测求损失时,由于属于无标注数据的那个区域使用的是教师网络生成的伪标签,并不准确,所以文中降低了这些像素产生的损失的比重,公式如下。

实验
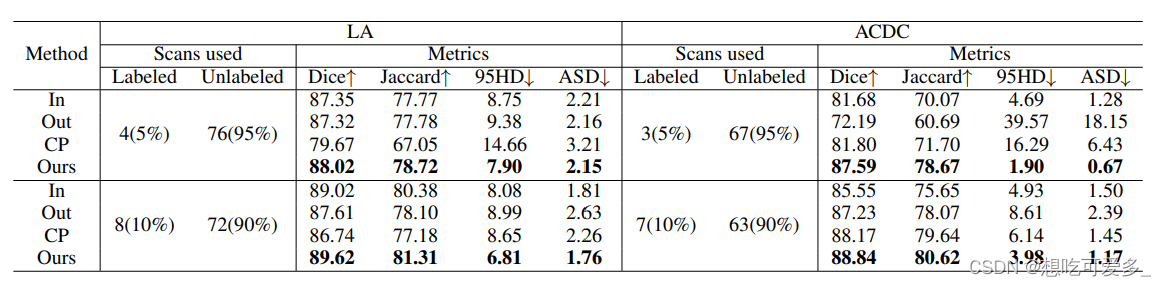
使用了三个数据集LA dataset、Pancreas-NIH和ACDC dataset,不同数据集超参不太一样,且本文的方法对网络没有要求,分割网络根据数据集决定是2D还是3D。
文中做了非常充足的对比试验和消融实验,这里挑几个展示。
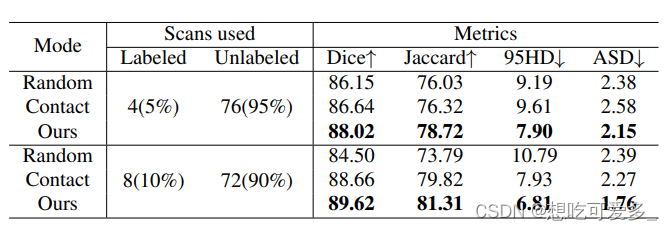
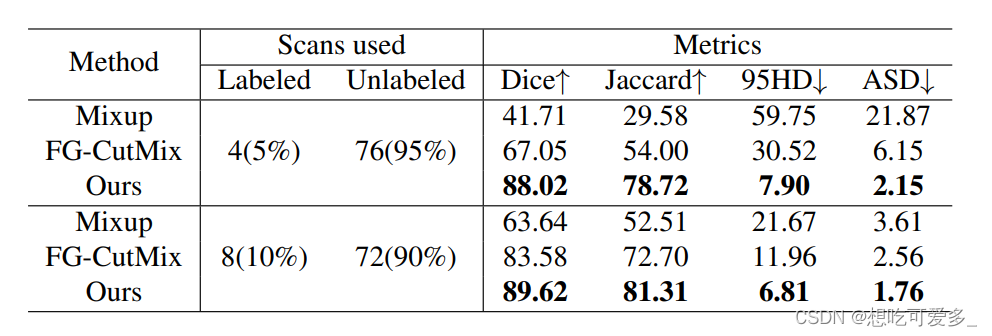
下面图片展示了单向CP(in代表只使用Xin,out代表只使用Xout),CP(Copy-Paste只发生在有标注或无标注数据内部),BCP的效果。
文中说BCP之所以效果好是因为它能够建立有标注和无标注数据间的一致性,能够提取共同的语义,从而减少得到的分布差异。
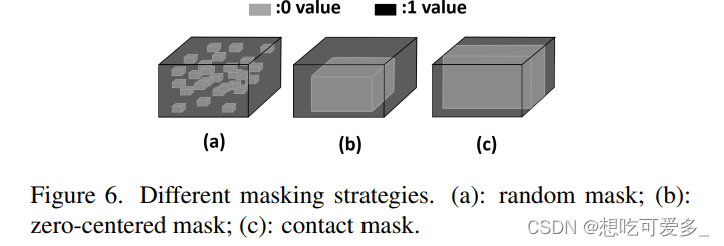
下面展示了三种PC时的不同策略,正如有图,a是裁剪了很多小patch,这样不能获取连续的前景特征所以效果不好;b是文中采用的;c是让patch四个面紧贴着原图,这样做效果不好的原因是前景一般不会接触边缘。
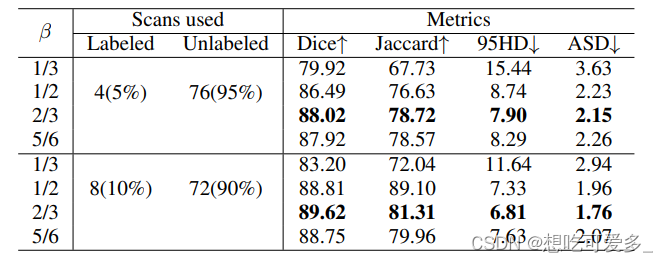
下面的β代表裁剪的patch的大小
三种裁剪拼接策略:第一个是使用GuidedMix-Net,第二个是把整个batch的图像裁剪为4×4个patch然后将它们随机组合以生成输入














 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









