







一、研究背景和意义
随着房地产市场的快速发展,房价数据成为了人们关注的焦点。了解房价的分布特征、影响因素以及不同区域之间的差异对于购房者、房地产开发商、政府部门等都具有重要的意义。通过对房价数据的聚类分析,可以深入了解房价的内在结构和规律,为相关决策提供科学依据。
研究意义:
- 为购房者提供参考:通过聚类分析,可以将房价数据分为不同的类别,购房者可以根据自己的需求和预算选择适合的房源。
- 帮助房地产开发商制定营销策略:了解不同区域的房价特征和需求,可以帮助房地产开发商制定更有针对性的营销策略,提高销售效率。
- 为政府部门提供决策支持:政府部门可以通过房价数据的聚类分析,了解房地产市场的发展趋势和存在的问题,制定相应的政策措施,促进房地产市场的健康发展。
- 推动房地产市场的研究:房价数据的聚类分析是房地产市场研究的重要内容之一,通过对房价数据的深入分析,可以推动房地产市场的研究不断深入。
二、实证分析
首先导入数据集基本的包
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt然后读取数据集和展示
# 读取文件
file_path = 'df_cleaned2.csv'
data = pd.read_csv(file_path, encoding='utf-8')
# 展示数据的前几行以了解结构
print(data.head())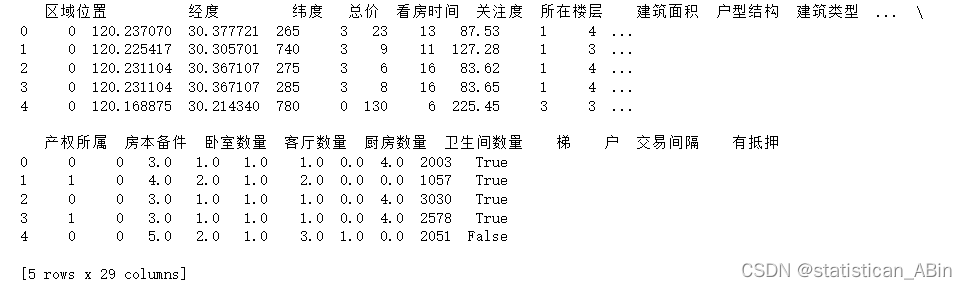
随后查看数据类型

接下来查看缺失值的情况
# 查看缺失值情况
missing_values = data.isnull().sum()
missing_values 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









