







融合零样本学习和小样本学习的弱监督学习方法综述

来源:《系统工程与电子技术》,作者潘崇煜等
摘 要: 深度学习模型严重依赖于大量人工标注的数据,使得其在数据缺乏的特殊领域内应用严重受限。面对数据缺乏等现实挑战,很多学者针对数据依赖小的弱监督学习方法开展研究,出现了小样本学习、零样本学习等典型研究方向。对此,本文主要介绍了弱监督学习方法条件下的小样本学习和零样本学习,包括问题定义、当前主流方法以及实验设计方案,并对典型模型的分类性能进行对比。然后,给出零-小样本学习的问题描述,总结研究现状和实验设计,并对比典型方法的性能。最后,基于当前研究中出现的问题对未来研究方向进行展望,包括多种弱监督学习方法的融合与理论基础的探究,以及在其他领域的应用。
关键词: 弱监督学习; 小样本学习; 零样本学习; 零-小样本学习
0 引 言
近年来,深度学习模型在诸多领域取得了引人瞩目的成就,如图像分类、语音识别、棋类对弈等。然而,包括深度学习在内,以大数据为基础的传统监督学习模型严重依赖于大量人工标注的高质量标签数据,在很多领域内,由于数据缺乏,使得这些模型很难取得应有成效。针对数据缺乏的现实情况,当前很多研究[1-2]关注数据依赖性小的弱监督学习方法,如小样本学习、零样本学习等。
小样本学习试图在有限样本条件下实现对新类别或新概念的有效认知。通过度量学习、样本生成等途径,已有一些方法在少量支持样本情况下实现了新概念识别。尽管取得了一定成效,但每个新类别中的几个支持样本仍然难以准确表征整个类别的特征分布,这使得小样本学习任务仍然充满了挑战性。
相对于小样本学习,零样本学习试图识别训练过程中从未见过的新类别概念。这需要额外的语义特征辅助信息,如训练集和待分类的测试集类别语义特征描述向量,借此实现从训练集向测试集类别的知识迁移。由于其内在固有的域适应及枢纽度问题[3],零样本学习也面临着识别精度不高等问题。
基于零样本学习和小样本学习面临诸多的问题,正如文献[3]指出,在当前小样本学习中融合额外的语义文本信息是一个重要的研究方向,即零-小样本学习。零-小样本学习既包含了小样本学习中若干支持样本特征,同时考虑了语义特征辅助信息,可以有效提高弱监督机器学习的识别性能,同时也更加符合人类对新概念、新事物举一反三、多方融合的认知原理。
本文从小样本学习和零样本学习入手,重点开展了问题描述、典型方法介绍、实验设计以及性能对比。基于小样本学习和零样本学习之间的信息互补,本文介绍了零-小样本学习这一新问题。在此基础上,本文指出了多种弱监督学习方法融合发展、基础理论探索以及多领域上扩展等重要发展方向。
1 小样本学习
小样本学习旨在通过有限样本对新的类别或者概念进行识别,本节首先给出明确问题描述,之后回顾目前主流方法和模型,最后介绍具体的实验设计和部分基准结果。
1.1 问题描述
给定由Ns个训练样本构成的训练集
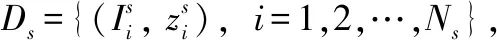
其中是第i个样本图像;是其类别标签,Cs是训练集标签集合;Ds通常由大量训练样本构成。
在测试阶段,对于新的类别Ct (测试类别与训练集类别不同,即Cs∩ Ct=∅),每个类别给定几个支持样本
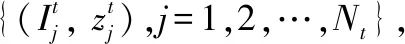
小样本识别的任务是对新的测试样本图像进行识别,确定其对应的类别标签
1.2 当前主流模型
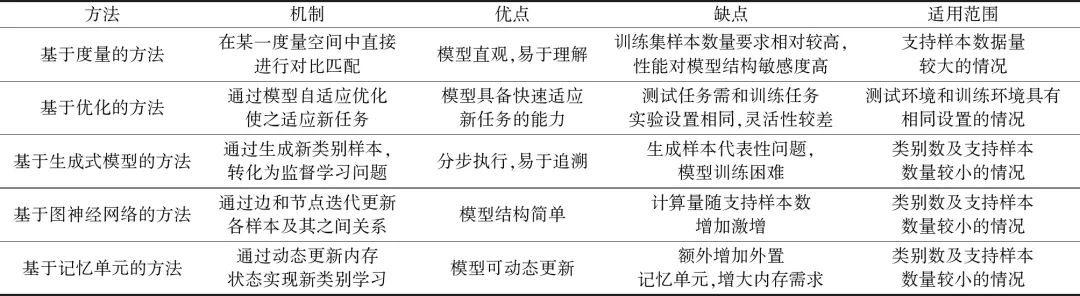
小样本学习领域目前已经出现很多方法和模型,这些方法可以概括为基于度量的方法、基于优化的方法、基于生成式模型的方法、基于图神经网络的方法以及基于记忆单元的方法。表1对这几种主流方法进行了简要列举和分析。
表1 不同的小样本学习方法对比分析
Table 1 Comparision analysis of the different methods for few-shot learning
(1) 基于度量的方法
基于度量的方法核心思想是学习样本之间的相似度。孪生网络[4]是最早的基于度量学习的小样本学习模型,该模型通过卷积神经网络(convolutional neural network, CNN)直接学习两个样本之间的相似度。之后,文献[5]提出了基于元学习的匹配网络,元学习是一种训练策略,具体算法流程如表2所示。
表2 元学习训练范式
Table 2 Training paradigm of the meta-learning

匹配网络利用了双向长短时记忆(long short-term memory, LSTM)网络模型以及注意力机制来学习样本之间的度量函数。原型网络[6]也是一种典型的度量学习模型,将图像特征映射到一度量空间中,在该空间中,将同类多个样本均值作为代表该类别的原型样本点,对于待识别的样本,通过在多类的原型样本点之间进行最近邻距离实现分类,该方法直接用欧氏距离作为距离度量,仅学习图像编码网络。值得一提的是,文献[7-8]提出了包含图像编码模块及关系度量模块的关系网络,原始图像经过CNN编码模块形成图像特征向量,之后待测试样本与支持样本连接形成图像对,经过关系网络度量每一图像对的相似度。如图1所示[7],该模型同时学习编码网络和度量函数,与以往使用某一固定度量函数不同,该模型通过训练学习了一个非线性的度量函数,提高了模型的适应性。
基于度量的小样本学习方法模型通常较为直观,易于理解,具备较强的可解释性,但往往需要大量训练数据,对于训练集样本数量要求较高,且最终性能对模型结构敏感度较高,模型细节设计对性能影响较大。
(2) 基于优化的方法
基于优化的方法依据元学习的思想,旨在学习一组元分类器,这些分类器可以在新的任务上通过参数微调实现较好的分类性能。最典型的优化方法是模型无关元学习(model-agnostic meta-learning, MAML)算法[9],如图2所示,该方法通过大量训练数据学习到一组好的初始化参数,在新任务测试时,仅通过很少的参数迭代步数,模型即可自适应到该新任务上。基于元学习思想,之后又出现了很多基于优化的小样本学习方法,包括meta network[10]、meta-SGD[11]、meta-learner LSTM[12]以及其他变种[13]。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









