









文章目录
【前言】
Kaggle竞赛补充内容:特征筛选
【简介】
特征筛选(Feature Selection)是机器学习和数据分析中的一个重要步骤,其主要目的是从原始特征集合中选择最相关、最有价值的特征,以用于构建模型、提高模型性能或减少计算成本。特征选择的核心思想是从所有可用特征中筛选出对于解决问题最有用的特征,从而提高模型的泛化能力和效率。
【正文】
(一)特征筛选的定义
特征筛选是指从原始的特征集合中挑选出一个子集,以在构建机器学习模型时用于训练模型、提高模型性能或减少计算成本。特征选择的目标是选择那些对于解决问题最重要、最相关的特征,同时排除掉无关或冗余的特征,从而改善模型的泛化能力、提高模型的效率或减少模型的复杂性。
1. 关键概念:
- 原始特征集合:原始特征集合是指在机器学习问题中可用的所有特征的集合。这些特征可以是数值型、分类型、文本型等不同类型的数据。
- 特征子集:特征子集是从原始特征集合中选择的一部分特征,用于训练机器学习模型。特征子集包含了原始特征的一个子集,通常是根据某种选择标准或算法挑选出来的。
- 特征选择方法:特征选择方法是用于确定哪些特征应该包括在特征子集中的技术或策略。这些方法可以根据特征与目标变量之间的相关性、信息增益、模型的性能等因素来选择特征。
- 特征重要性:特征重要性是指每个特征对于模型的预测或分类性能的贡献程度。特征选择方法通常会使用特征重要性来衡量特征的价值,并根据其重要性来进行选择。
- 目标变量:目标变量是机器学习问题中需要预测或分类的变量。特征选择的目标通常是找到与目标变量高度相关的特征,以提高模型的预测准确性。
2. 与降维的区别:
- 目标:
- 特征选择的目标是从原始特征集合中选择一部分特征,以保留最相关、最有价值的特征,并且丢弃无关或冗余的特征。其主要目的是提高模型性能、降低过拟合风险或减少计算成本,同时保持原始特征的可解释性。
- 降维的目标是减少数据集的维度,将高维数据映射到低维空间,以减少数据的复杂性。降维的主要目的是缩减数据维度,减少存储和计算成本,并有时可以提高模型的泛化能力。
- 方法:
- 特征选择通过评估每个特征与目标变量之间的相关性、信息增益、特征重要性等方法,来选择最重要的特征子集。这些方法通常不改变特征的原始表示,只是选择性地保留一部分特征。
- 降维方法通过线性或非线性变换将原始高维数据映射到低维空间。常见的降维技术包括主成分分析(PCA)、独立成分分析(ICA)、 t-分布随机邻域嵌入(t-SNE)等,它们可以生成新的特征或维度,通常会改变数据的表示。
- 数据变换:
- 特征选择通常不涉及数据的变换,只是选择性地保留原始特征,因此保留的特征仍然保持原始的可解释性。
- 降维方法会对数据进行变换,生成新的特征或维度,因此通常丧失了原始特征的可解释性,但可以更好地捕获数据中的结构。
- 维度数量:
- 特征选择通常保持原始数据的维度不变或减少特征数量,但不会显著减少维度。
- 降维方法的主要目标是显著减少维度,将高维数据映射到低维空间。
- 适用场景:
- 特征选择通常用于数据集中存在一些重要特征的情况,希望提高模型性能或减少计算成本,同时保持特征的可解释性。
- 降维通常用于高维数据的情况,其中大多数特征都可能包含噪声或冗余信息,降维可以减少数据的复杂性,提高模型的训练速度。
(二)特征选择主要方法
1. 过滤法(Filter)
(1)定义:
在特征选择与模型训练之前进行,独立于任何具体的机器学习算法。通过统计或信息论等技术来评估特征与目标变量之间的相关性,并根据预定义的阈值或标准对特征进行排序或筛选。
(2)步骤:
- 特征评估:首先对每个特征进行评估,以确定它们与目标变量之间的关联程度。常见的特征评估方法包括皮尔逊相关系数、卡方检验、互信息等。这些方法可以用于不同类型的数据,如数值型、分类型或文本型。
- 特征排序:评估后,特征会根据其与目标变量的相关性得分进行排序。得分高的特征被认为更重要,得分低的特征被认为不太重要。
- 特征筛选:基于得分,可以选择保留排名靠前的特征,或者根据预定义的阈值来筛选特征。这个过程可以减少特征数量,提高模型训练效率,同时保持相对较高的预测性能。
- 模型训练:最终的特征子集被用于训练机器学习模型。由于过滤法是在模型训练之前进行的,所以选择的特征子集不会受到后续模型的影响。
- 可解释性:过滤法保留了原始特征的可解释性,因为它们仍然是原始特征,只是根据得分进行排序或筛选。
(3)示例:
以kaggle的Titanic比赛为例,完整流程请参考Kaggle_Titanic比赛
略过前面的数据预处理与特征工程等步骤,假设我们已经获得了处理好的数据train_dict表与test_dict表。
其中trian_dict表和test_dict表经过特征工程处理分别有1428,1427个属性。
(len(train_dict.columns.tolist()), len(test_dict.columns.tolist()))
(1418, 1417)
去除其中无法进行建模的属性,包括唯一索引’PassengerId’、’Name‘,分布不一致的属性’Cabin‘与目标属性’Survived‘。
features = train_dict.columns.tolist()
features.remove('PassengerId')
features.remove('Name')
features.remove('Survived')
features.remove('Cabin')
featureSelect = features[:]
使用基于皮尔逊相关系数的Filter方法进行特征筛选并输出相关系数。
corr = []
for fea in featureSelect:
corr.append(abs(train_dict[[fea, 'Survived']].fillna(0).corr().values[0][1]))
se = pd.Series(corr, index=featureSelect).sort_values(ascending=False)
se
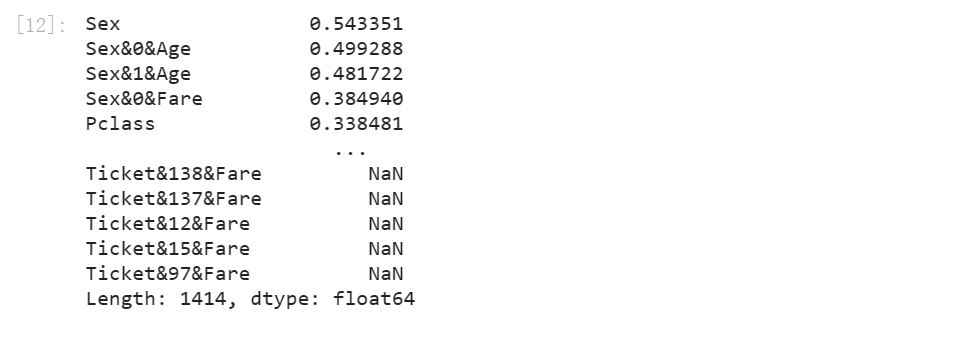
选择相关系数最大的前70个特征进行建模。
feature_select = ['PassengerId'] + se[:70].index.tolist()
查看特征
print(se[:70].index.tolist())

2. 包裹法(Wrapper)
(1)定义:
与过滤法不同,它将特征选择过程嵌套在机器学习模型的训练中,以确定最佳的特征子集。包裹法的核心思想是将特征选择问题视为搜索最佳特征子集的优化问题,通过尝试不同的特征子集来评估模型性能,并选择性能最佳的子集作为最终的特征集合。
(2)步骤:
- 特征子集搜索:包裹法从原始特征集合中开始,创建一个初始的特征子集,可以是包含部分特征或全部特征。然后,它通过不断添加或删除特征的方式来搜索不同的特征子集。
- 模型训练和评估:对于每个特征子集,包裹法训练一个机器学习模型,并使用该模型在训练集上进行性能评估。通常,采用交叉验证来评估模型的性能,以避免过拟合。
- 特征子集评估:根据模型在交叉验证或其他评估方法中的性能指标(如准确度、F1分数、均方误差等),对每个特征子集进行评估,通常是通过交叉验证的平均性能来评估。
- 选择最佳子集:包裹法选择性能最佳的特征子集作为最终的特征集合。这个子集通常包含了模型在验证集上表现最好的特征组合。
- 模型的重新训练:一旦确定了最佳特征子集,包裹法通常会使用这个子集来重新训练最终的机器学习模型,以便在测试集上进行最终性能评估。
(3)示例:
同上,仍以kaggle的Titanic比赛为例
使用LightGBM作为机器学习模型,训练模型来评估特征的重要性,选择排名前70的特征进行筛选。
导入相关包
import lightgbm as lgb
from sklearn.model_selection import KFold
from hyperopt import hp,fmin,tpe
from numpy.random import RandomState
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
通过迭代的方式,在不同划分的数据集里选择feature_importance最大的70个特征。
具体LightGBM的参数设置,可以参考集成学习LightGBM
def feature_select_wrapper(train, test):
print('start selecting features...')
features = train.columns.tolist()
label = 'Survived'
features.remove('PassengerId')
features.remove('Name')
features.remove('Cabin')
features.remove('Survived')
# LightGBM参数空间
params_initial = {
'num_leaves': 10,
'learning_rate': 0.1,
'boosting_type': 'gbdt',
'min_child_samples': 20,
'bagging_seed': 2025,
'bagging_fraction':0.8,
'feature_fraction':0.8,
'bagging_freq':1,
'max_depth':-1,
'metric': 'binary_logloss',
'objective':'binary'
}
ESR = 20
NBR = 1000
VBE = 50
kf = KFold(n_splits=5, random_state=2024, shuffle=True)
# 保存特征重要性
fse = pd.Series(0, index=features)
# 保存损失函数值
all_eval_result = []
for train_index, eval_index in kf.split(train[features], train[label]):
train_part = lgb.Dataset(train[features].loc[train_index],
train[label].loc[train_index])
eval_part = lgb.Dataset(train[features].loc[eval_index],
train[label].loc[eval_index])
eval_result = {}
bst = lgb.train(params_initial,
train_part,
num_boost_round=NBR,
valid_sets=[train_part, eval_part],
valid_names=['train', 'valid'],
early_stopping_rounds=ESR,
verbose_eval=VBE,
evals_result=eval_result)
all_eval_result.append(eval_result)
fse += pd.Series(bst.feature_importance(), features)
# 损失函数曲线
for eval_result in all_eval_result:
plt.figure(figsize=(6, 6))
ax = lgb.plot_metric(eval_result, metric='binary_logloss')
plt.show()
feature_select = fse.sort_values(ascending=False).index.tolist()[:70]
print(feature_select)
print('done')
return feature_select
筛选得到最优70个特征
feature_select = feature_select_wrapper(train_dict.fillna(0), test_dict.fillna(0))
查看特征
print(feature_select)

3. 嵌入法(Embedded)
(1)定义:
在前两种特征选择方法中,特征选择过程和模型训练过程是有明显分别的两个过程。嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择。
(2)步骤:
- 特征重要性评估:嵌入法使用具体的机器学习算法(如决策树、线性回归、支持向量机等)来训练模型,并在训练过程中评估每个特征的重要性。不同的算法使用不同的方式来衡量特征的重要性,例如决策树可以使用特征的信息增益或基尼不纯度来评估。
- 特征选择:基于特征的重要性评估,嵌入法选择最重要的特征子集。通常,可以设置一个阈值或根据重要性排名来选择要保留的特征。
- 模型训练:选定的特征子集被用于训练机器学习模型。由于特征选择是嵌入在模型训练中的,所以模型会考虑这些选择的特征,从而能够更好地捕获数据的模式。
- 模型性能评估:最终训练的模型可以在验证集或交叉验证中进行性能评估,以确保选择的特征子集在模型性能方面达到了预期的效果。
(3)SelectFromModel方法
SelectFromModel 是 scikit-learn 中的一个特征选择工具,用于从机器学习模型中使用Embedded方法选择重要的特征。它的主要思想是基于训练好的模型的特征重要性来筛选出最相关的特征,从而降低维度并提高模型的性能。SelectFromModel 可以与各种不同的监督学习算法一起使用,例如决策树、随机森林、支持向量机等。
SelectFromModel使用步骤:
- 初始化
SelectFromModel:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
# 初始化一个随机森林分类器作为基础模型
clf = RandomForestClassifier(n_estimators=100)
feature_selector = SelectFromModel(clf)
- 拟合模型和选择特征:
使用 fit 方法来拟合 SelectFromModel 对象,并传入特征矩阵 X 和目标向量 y。它会根据模型的特征重要性来选择特征。
feature_selector.fit(X, y)
- 筛选特征:
使用 transform 方法来筛选特征矩阵。
X_selected = feature_selector.transform(X)
- 阈值设置:
可以使用 threshold 参数来指定阈值,只有那些特征重要性超过阈值的特征才会被选择。
feature_selector = SelectFromModel(clf, threshold=0.2) # 仅选择特征重要性大于0.2的特征
(4)示例:
同上,仍以kaggle的Titanic比赛为例
导入必要的包
features = train_dict.columns.tolist()
features.remove('Name')
features.remove('PassengerId')
features.remove('Cabin')
features.remove('Survived')
缺失值填充
train_dict = train_dict.fillna(0)
train_dict.isnull().sum()
特征筛选,其返回的不是特征名称,而是筛选后的数据本身。
train_select = SelectFromModel(GradientBoostingClassifier(), max_features=70).fit_transform(train_dict[features], train_dict['Survived'])
(train_dict.shape,feature_select.shape)
((891, 1418), (891, 70))
数据经过筛选后只剩70个属性。















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









