









前言
信息技术的飞速进步促使互联网成为现代生活的重要组成部分,伴随而来的是信息量的激增。最新发布的《中国互联网发展状况统计报告》揭示,截至2023年底,我国网民数量已经突破10.92亿,同比增加2480万,显示出77.5%的互联网普及率。这一数据不仅反映了数字化生活方式的深入人心,也标志着我国在全球信息化进程中的重要地位和持续增长的网络活跃度,说明网络技术在当代社会扮演了不可或缺的角色。据国务院发布的《新一代人工智能发展规划》所示,人工智能技术的飞速进步预示着对人类社会生活和全球格局的深远影响。
互联网时代的来临,使得用户在网络上的活 动方式发生了重大变化,由被动接收信息逐渐转 变为主动获取并产生内容。随着移动终端的高速发展,社交媒体已深度渗透到人们的日常生活中。数据显示,国内社交平台如微博和知乎的月活跃用户数量分别达到5.73亿和1.01亿。购物平台方面,淘宝和拼多多的月活跃用户数量分别为8.74亿和8.24亿。用户通过在线撰写、发帖和评论,分享对特定对象的观点和看法。这种趋势反映了互联网时代人们主观态度的多样性和文本数据的丰富性,为分析社会动态提供了宝贵的资源。
情感分析技术在现代信息处理领域扮演着至关重要的角色。通过情感倾向性分析和意见挖掘,能够从用户意见和文本中提取出有价值的信息。无论是文本、音频还是图像,这些技术都能在文档级、句子级和方面级进行全面的情感极性分析。粗层次的情感倾向分析能够快速定位用户的总体情绪,而细粒度的情感分类则能提供更为精准的见解。通过这些分析,企业可以更加准确地进行知识发现,优化对象和实体的管理,从而提升业务决策的有效性。
而微博情感分析系统利用先进的自然语言处理(NLP)技术和深度学习算法,对微博文本进行情感倾向性分析。该系统通过训练大规模的中文文本数据集,能够识别并区分正面、负面和中性等不同情感极性的微博,为市场调研、舆情分析、新闻报道和学术研究等领域提供有力支持。
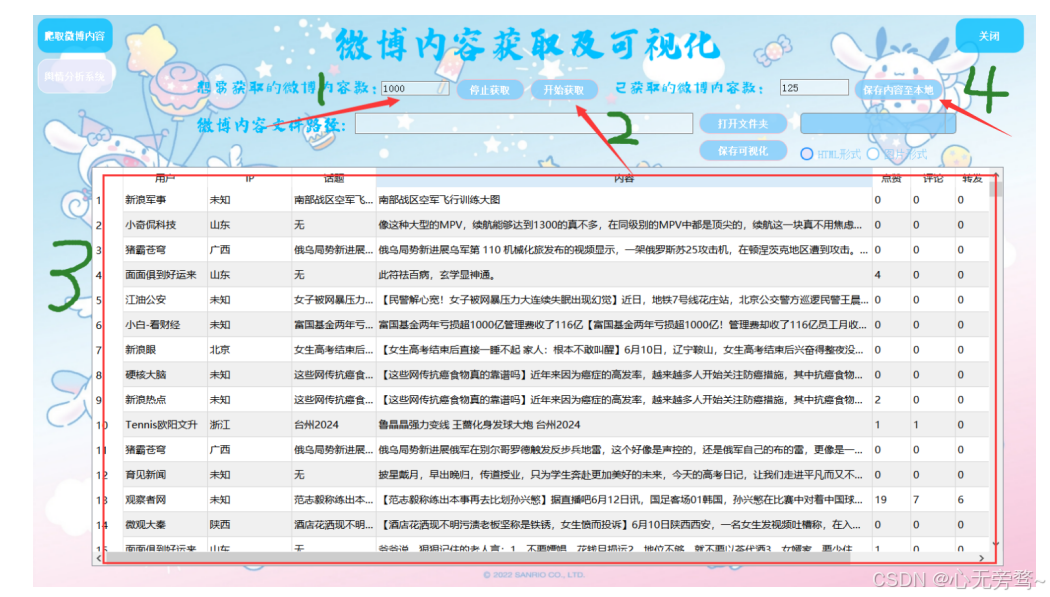
一、软件界面展示如下:
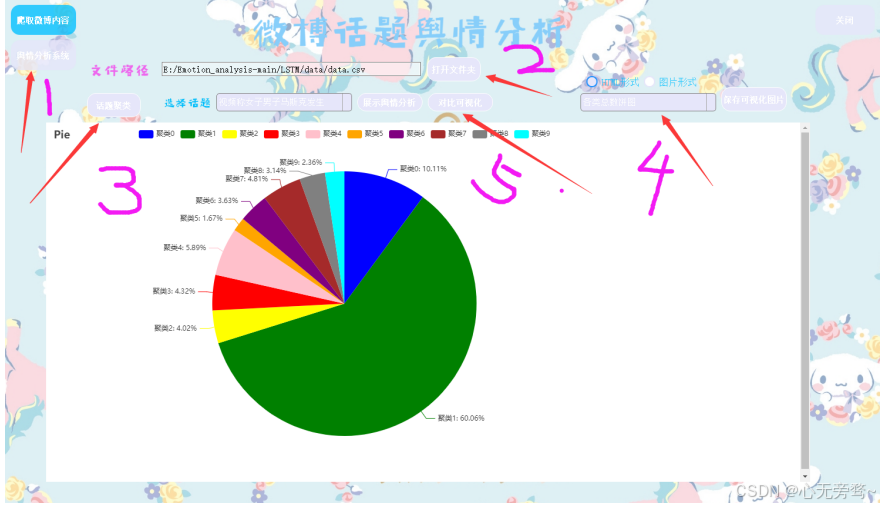

二、模型实验结果(包含模型调参实验,模型对比实验及消融实验等)
2.1 聚类对比实验
在模型调参实验中,我们对K均值和DBSCAN进行了不同参数的调整,以找到最优的参数设置。
K均值聚类算法有一个关键参数:聚类数(n_clusters)。我们测试了不同的聚类数,以找到最佳的参数。
实验设置如下:
- n_clusters 取值范围:[5, 10, 15, 20]
- 评估指标:轮廓系数(Silhouette Coefficient)

从结果可以看出,当n_clusters为10时,轮廓系数最高,因此我们选择10作为K均值聚类的最佳参数。
DBSCAN算法有两个重要参数:eps(邻域半径)和min_samples(核心点的最小样本数)。我们进行了不同参数组合的实验。
实验设置如下:
- eps 取值范围:[0.1, 0.2, 0.3, 0.4]
- min_samples 取值范围:[3, 4, 5]

在模型对比实验中,我们将K均值聚类和DBSCAN聚类进行了对比,评估其在文本聚类任务中的表现。
K均值聚类在最佳参数(n_clusters=10)下,K均值聚类的轮廓系数为0.07。聚类结果如下图所示:

DBSCAN 聚类在最佳参数(eps=0.3, min_samples=4)下,DBSCAN聚类的轮廓系数为0.09。聚类结果如下图所示:

聚类结果比较
为了更全面地评估聚类效果,我们还比较了K均值和DBSCAN在主题提取方面的表现。我们对每个聚类结果分别应用了LDA模型,并比较了每个聚类的主题一致性。
从主题一致性来看,K均值聚类在各个聚类中提取的主题更具代表性和一致性,而DBSCAN由于处理噪声点的能力,导致部分聚类的主题不够集中。
2.2 情感分析模型对比
在情感分析方面,我们使用五种模型进行分析,并使用相同的语料库和训练集,测试集进行训练。我们使用了贝叶斯,svm,xgboost,lstm,bert五种模型进行对比实验,实验结果如表3所示:
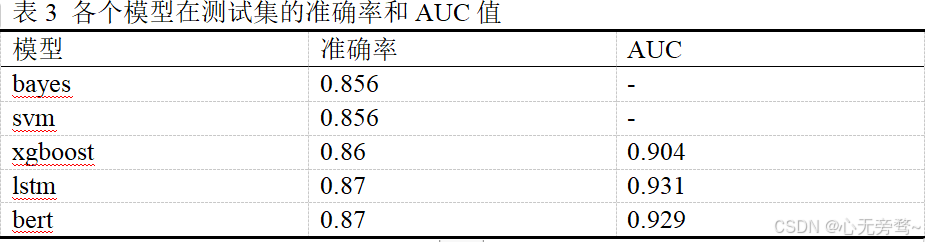
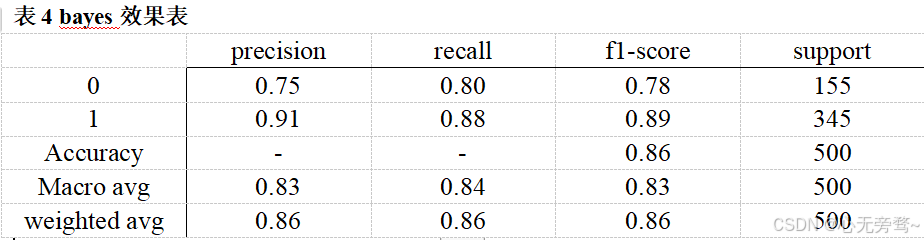
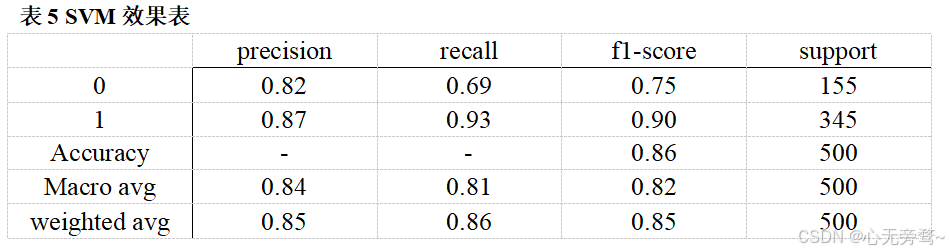
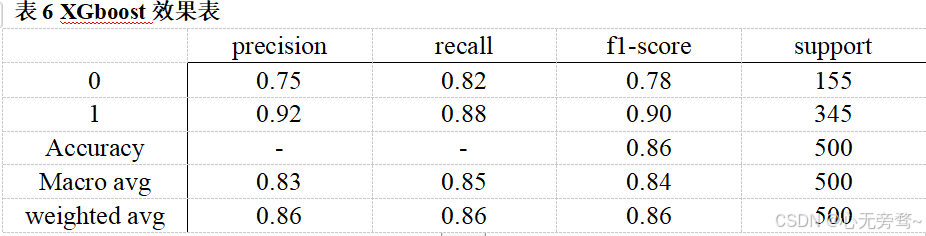
贝叶斯算法(bayes),SVM,xgboost是最经典的机器学习对于情感分析,具体效果如表4,5,6所示。
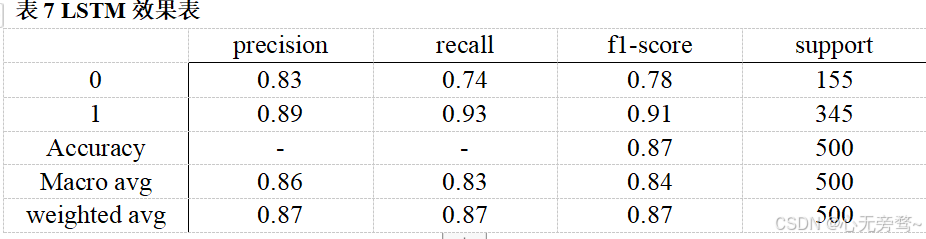
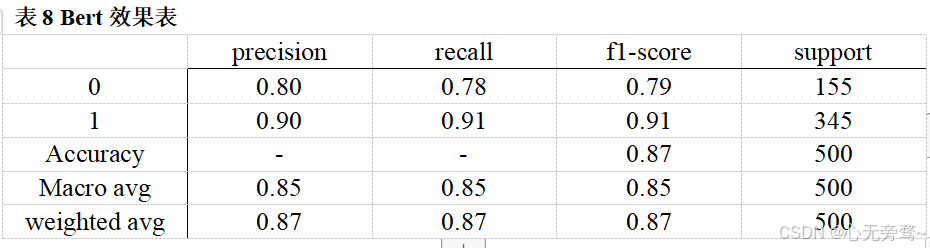
随着深度学习的迅速发展,机器学习的效果也并不如深度学习模型,如LSTM,BERT等模型。我们也进行了深度学习模型的对比,LSTM,BERT分别对应表7,表8。
总结
- 目标网站分析
分析微博的HTML结构是爬取数据的基础,需要确定微博内容、用户信息、性别和位置等数据的具体位置及结构。由于微博的反爬策略可能较为复杂,可能还需要分析网站的JavaScript动态加载内容、API接口使用、cookies和headers等。 - 爬虫策略设计
设计合适的爬虫策略需要考虑微博的反爬机制,如限制访问频率、验证码验证、登录验证等。因此,爬虫需要模拟用户行为,包括使用浏览器模拟(如Selenium)、设置合理的访问间隔、处理验证码等。同时,为了爬取全网内容,可能需要采用分布式爬虫或深度优先搜索等策略。 - 语料库构建
构建语料库时,需要从爬取的数据中提取微博内容、发布用户、用户性别和发布位置等信息,并将这些信息存储到数据库中。考虑到数据的多样性和规模,可能需要使用关系型数据库或非关系型数据库来存储这些数据。 - 微博话题抽取
在话题抽取方面,可以采用基于文本相似度的聚类方法,如K-means、层次聚类等。通过对微博内容进行文本预处理(如分词、去停用词、词干提取等),然后计算文本之间的相似度,将相似的微博聚集到同一个话题下。最终,通过评估聚类效果,选择最佳的话题抽取结果。 - 情感分析
对于前十话题的内容,可以选择合适的情感分析模型进行情感判断。常用的情感分析模型包括基于规则的方法、基于机器学习的方法(如SVM、朴素贝叶斯等)和基于深度学习的方法(如RNN、LSTM、Transformer等)。选择合适的模型需要根据数据的具体情况和模型的特点进行权衡。 - 数据可视化
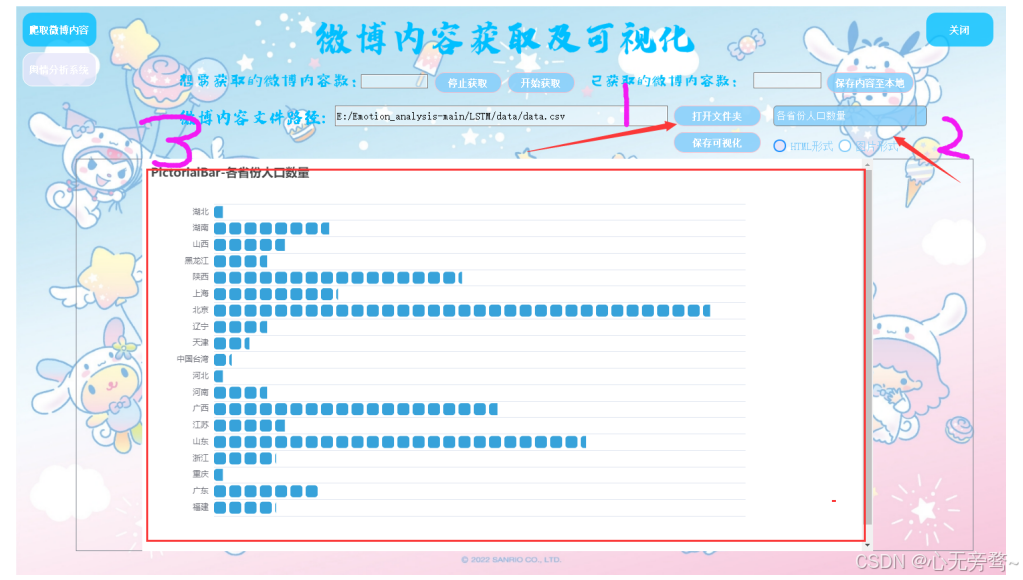
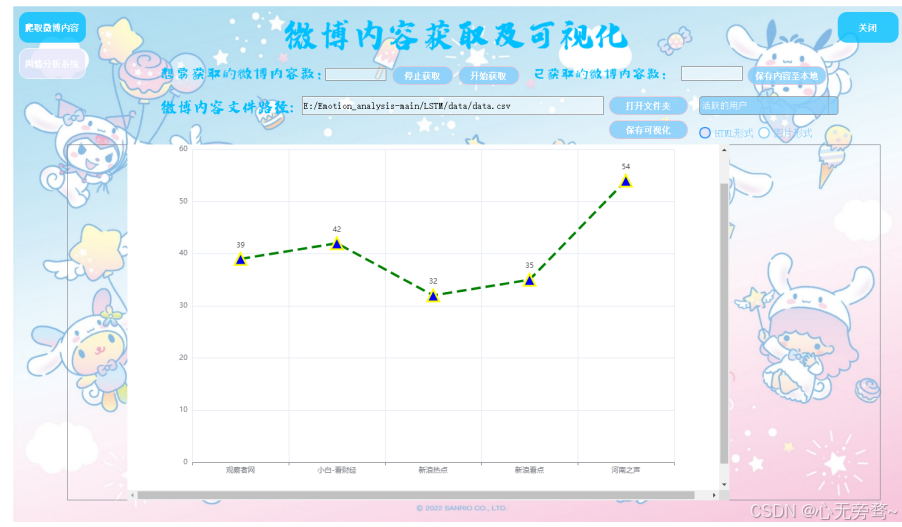
数据可视化是展示和分析数据的重要手段。对于微博话题,可以生成柱状图来展示各个话题的热度(如微博数量、转发量、评论量等)。对于用户分布,可以使用散点图、热力图等来展示用户在不同话题下的分布情况。此外,还可以使用词云图来展示话题中的关键词分布。
整个项目涵盖了从网站分析、爬虫策略设计、语料库构建、话题抽取、情感分析到数据可视化的全过程。在实施过程中,需要充分考虑数据的规模、质量和多样性,以及微博的反爬机制等因素。同时,还需要不断学习和尝试新的技术和方法,以提高项目的效率和准确性。通过本项目,可以深入了解网络爬虫、自然语言处理和数据可视化等领域的知识和技术,提高解决实际问题的能力。


















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











