






文章目录
一、分类评估方法
分类问题是机器学习领域最常见的大类问题,有很多场景可以划归到分类问题的解决范畴。下面我们梳理一下分类问题的主要评估指标(Evaluation Metrics)。
1.1 精确率和召回率
1.1.1 混淆矩阵
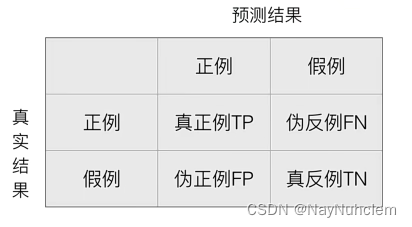
在分类任务中,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类),混淆矩阵(Confusion Matrix)是非常有效的评估模式,特别用于监督学习(在无监督学习中一般叫做匹配矩阵)。典型的混淆矩阵构成如下图所示:
- 每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目。
- 每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
- 准确率 : T P + T N T P + F N + F P + T N \frac{TP+TN}{TP+FN+FP+TN} TP+FN+FP+TNTP+TN
1.1.2 精确率(Precision)与召回率(Recall)
-
精确率:预测结果为正例样本中真实为正例的比例
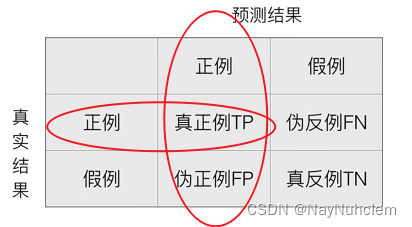
准确率: T P T P + F P \frac{TP}{TP+FP} TP+FPTP -
召回率:真实为正例的样本中预测结果为正例的比例()
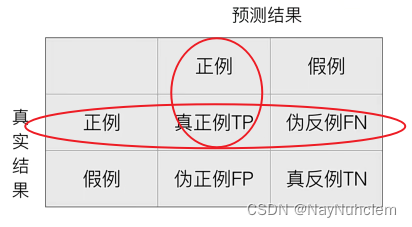
召回率: T P T P + F N \frac{TP}{TP+FN} TP+FNTP
1.2 F1-score
F1-score,用来反应模型的稳健性,同时还有其他的评估标准。
F
1
=
2
T
P
2
T
P
+
F
N
+
F
P
=
2
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F1=\frac{2TP}{2TP+FN+FP}=\frac{2*Precision*Recall}{Precision+Recall}
F1=2TP+FN+FP2TP=Precision+Recall2∗Precision∗Recall
F1-score综合平等考虑 Precision 和 Recall 的评估指标,当
F
1
F1
F1 值较高时则说明模型性能较好。
二、ROC曲线与AUC指标
除了前面介绍的Accuracy、Precision 与 Recall,还有一些其他的度量标准,如使用 True Positive Rate(TPR,真正例率)和False Positive Rate(FPR,假正例率)两个指标来绘制 ROC 曲线。
2.1 TPR与FPR
- TPR=TP/(TP+FN)
- 所有真实类别为1的样本中,预测类别为1的比例
- FPR=FP/(FP+TN)
- 所有真实类别为0的样本中,预测类别为1的比例
2.2 ROC曲线
**ROC通过置信度可以对所有样本进行降序排序,再逐个样本地选择阈值,比如排在某个样本之前的都属于正例,该样本之后的都属于负例。**每一个样本作为划分阈值时,都可以计算对应的 TPR 和 FPR,那么就可以绘制 ROC 曲线。
- ROC曲线的横轴就是FPRate,纵轴是TPRate,当两者相等时,表示的意义是:对于不论真实类别是1还是0的样本中,分类预测为1的概率是相等的,此时AUC为0.5
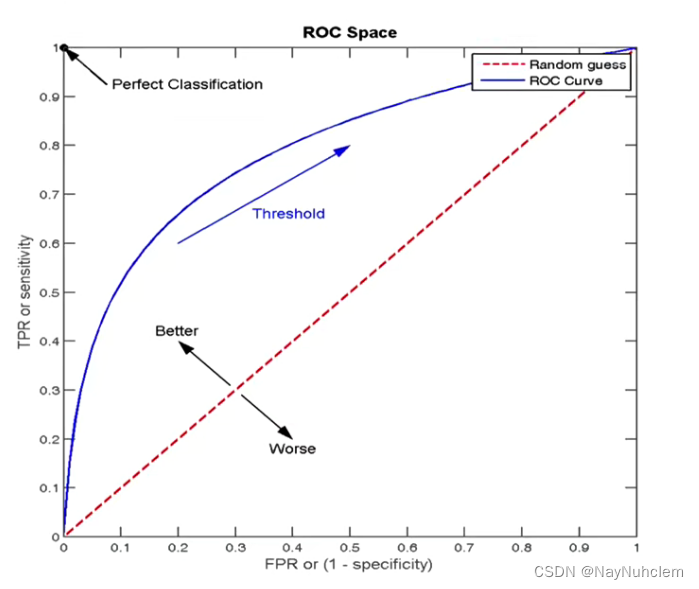
- 点(0,1)即FPR=0,TPR=1意味着FN=0且FP=0,此时将所有的样本都正确分类。
- 点(0,0)即FPR=TPR=0意味着FP=TP=0,此时分类器将每一个实例都预测为负类。
- 点(1,1)即FPR=TPR=0,此时分类器将每一个实例都预测为负类。
- 点(1,0)即FPR=1,TPR=0,最差分类器,避开所有的答案。
ROC曲线越接近左上角,表示该分类器的性能越好。也就是说模型在保证能够尽可能地准确识别小众样本的基础上,还保持一个较低的误判率,即不会因为要找出小众样本而将很多大众样本给误判。 一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting。
2.3 AUC指标
ROC曲线的确能在一定程度上反映模型的性能,但它并不是那么方便,因为曲线靠近左上方这个说法还比较主观,不够定量化,因此还是需要一个定量化的标量指标来反映这个事情。ROC曲线的AUC值恰好就做到了这一点。

AUC(Area Under ROC Curve)是 ROC 曲线下面积,其物理意义是,正样本的预测结果大于负样本的预测结果的概率,本质是AUC反应的是分类器对样本的排序能力。
- AUC的概率意义是随机取一对正负样本,正样本大于负样本得分发概率。
- AUC的范围在[0,1]之间,并且越接近1越好,越接近0.5效果越差。
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得到完美的预测。但是,绝大多数预测场合,不存在完美分类器。
- 0.5<AUC<1
三、PRC
与 ROC 曲线的思想类似,根据 Precision 和 Recall,也提出了一种 Precision-Recall 曲线。
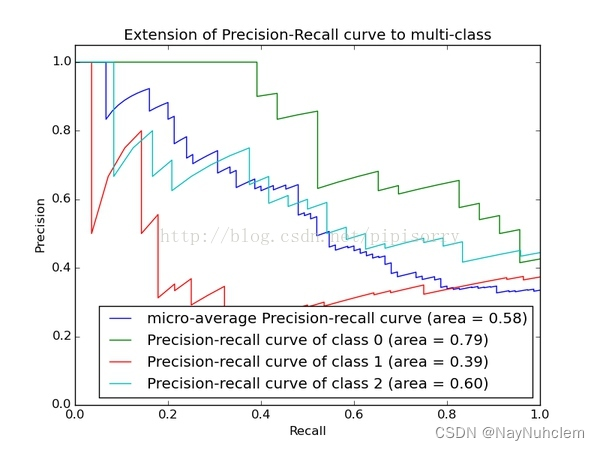
同样是通过置信度就可以对所有样本进行降序排序,再逐个样本地选择阈值,比如排在某个样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的 Precision 和 Recall,那么就可以绘制PR曲线。















 8888
8888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









