






基于LLaMA-Factory开源项目的模型微调
1 项目介绍

1.1 项目特色
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
1.2 性能指标
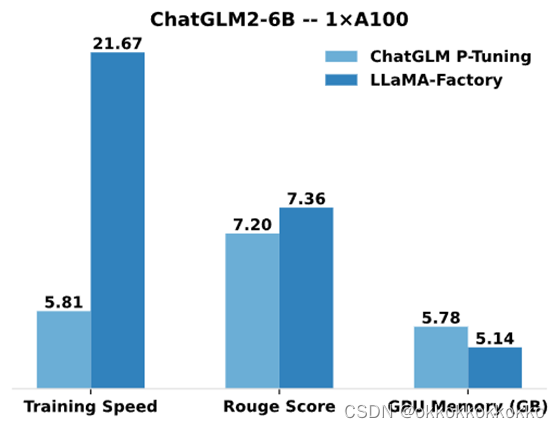
与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA Factory 的 LoRA 微调提供了 3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
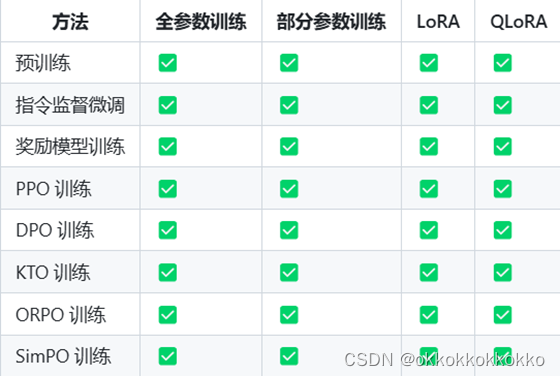
1.3 训练方法
这里特别说一下,本框架不仅支持预训练(Pre-Training)、指令监督微调训练(Supervised Fine-Tuning),还是支持奖励模型训练(Reward Modeling)、PPO、DPO、ORPO等强化学习训练。
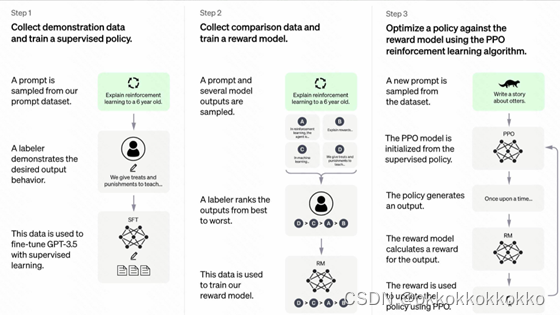
各训练阶段的含义参考此图:
在了解基本使用方法后,我们将部署该工具















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









