







一.安装及查看版本
import seaborn as sns
print(sns.__version__) # 查看版本 0.11.2
升级命令pip install —upgrade seaborn
二.seaborn常用API说明

figure-level是通用接口,对应的axes-level为具体接口。使用具体接口可以实现具体的功能,使用通用接口时通过设置 kind 或 其他参数 来达到具体接口的效果,所以实现同一个功能有多种方法。
三.获取数据集(用于全篇绘图举例)
查看自带数据集:print(sns.get_dataset_names())
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'geyser', 'iris', 'mpg', 'penguins', 'planets', 'taxis', 'tips', 'titanic']
分类问题:企鹅种类
penguins_df = sns.load_dataset('penguins')
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 1 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
回归问题:小费金额
tips_df = sns.load_dataset('tips')
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
四.单变量
1.连续型
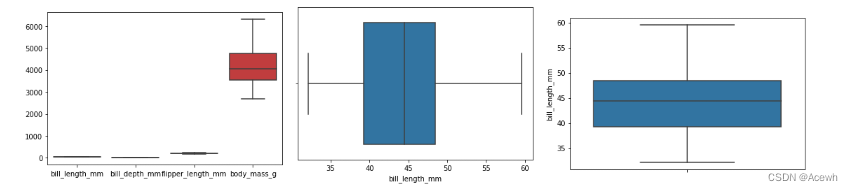
箱线图
查看变量取值范围,是否有异常值(极大或极小值,不包含空值)
sns.boxplot(data=penguins_df) # 绘制数据集中所有连续型变量的箱线图
sns.catplot(data=penguins_df,x='bill_length_mm',kind='box')
sns.boxplot(data=penguins_df ,x='bill_length_mm') # 在x轴上绘制箱型图
sns.boxplot(data=penguins_df ,y='bill_length_mm') # 在y轴上绘制箱型图
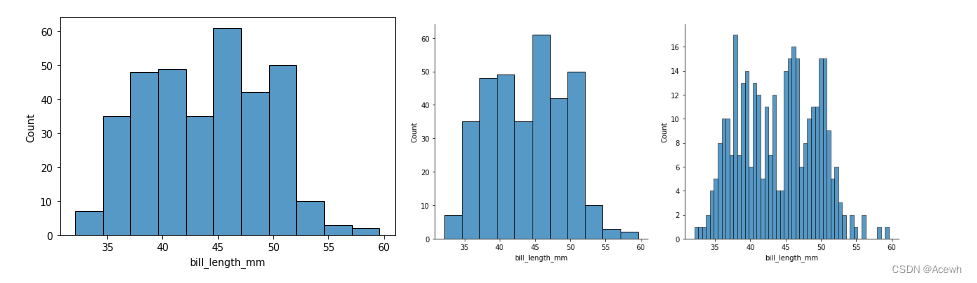
直方图
sns.histplot(data=penguins_df,x='bill_length_mm')
sns.displot(data=penguins_df,x='bill_length_mm') # 默认 kind='hist'
sns.displot(data=penguin_df,x="bill_length_mm",bins=50) # 改变分桶数
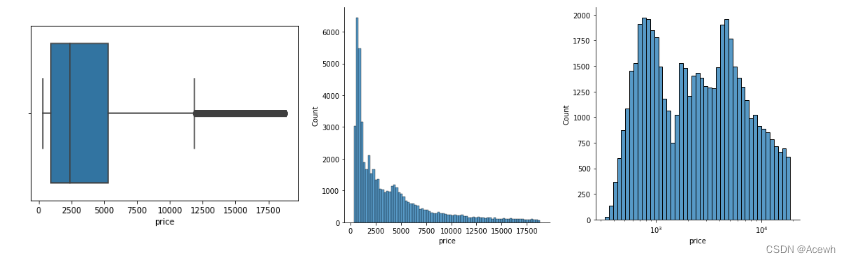
注意:有些数据,比如某产品的价格从几百到几万不等,箱线图可能会将一些正常值判断为异常值,并且对应的直方图效果很差,此时可以将数据进行取对数处理,如果处理后的数据表现良好,可以将原数据进行相应的处理。
sns.boxplot(data=product_df,x="price") # 原始箱线图
sns.displot(data=dia_df,x="price") # 原始直方图
sns.displot(data=dia_df,x="price",log_scale=True) # 取对数处理后直方图
kde密度曲线
sns.displot(x="bill_length_mm",data=penguin_df,kind="kde")
sns.kdeplot(x="bill_length_mm",data=penguin_df)
sns.displot(x="bill_length_mm",data=penguin_df,kind="kde",cut=0) # cut=0 表示只拟合实际的数值范围

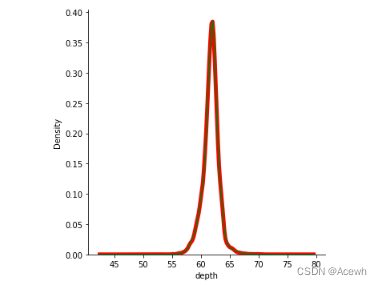
ked曲线验证测试集和训练集的分布是否一致
sns.displot(data=train_df,x="depth",kind="kde",linewidth=5.0,color="r")
sns.kdeplot(data=test_df, x="depth",color="g")
rug地毯样本分布
sns.displot(x="bill_length_mm",data=penguin_df,kind="kde",rug=True)

ked与直方图合并
sns.displot(x="bill_length_mm",data=penguin_df,kde=True)
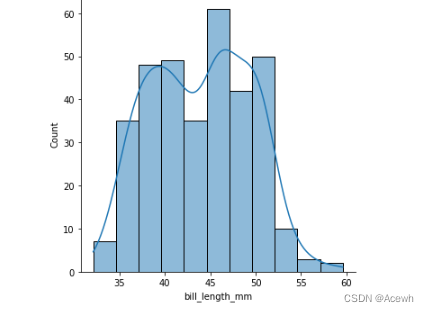
ecdf经验累积分布函数
sns.displot(penguin_df,x="bill_length_mm",kind="ecdf")

2.离散型
直接查看每类分布即可
sns.countplot(data=penguins_df,x='species')
sns.displot(data=penguins_df,x='species',hue='species') # 根据hue指定的类别变量显示标签
sns.displot(data=penguin_df,x="species",hue="species",shrink=.7) # 根据hue指定的类别变量显示标签,shrink指定桶的缩放大小

五.连续型多变量关系分析
1.散点图
sns.scatterplot(data=tip_df,x="total_bill",y="tip")
sns.relplot(data=tip_df,x="total_bill",y="tip") # 默认kind='scatter'
sns.relplot(data=tip_df,x="total_bill",y="tip",hue="time",style="time",markers=["o","^"])
# 按照time分类并设置分类样式
sns.relplot(data=tip_df,x="total_bill",y="tip",hue="size",size="size")
# 按照size分类

2.线形图
sns.lineplot(data=tip_df,x="total_bill",y="tip")
sns.relplot(data=tip_df,x="total_bill",y="tip",kind="line")
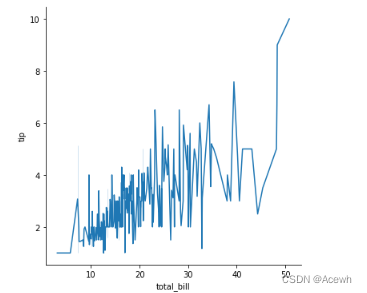
由图可知x和y的线性关系很差
3.线性回归
sns.regplot(data=tip_df,x="total_bill",y="tip")
sns.lmplot(data=tip_df,x="total_bill",y="tip")
sns.lmplot(data=tip_df,x="total_bill",y="tip",hue='time')
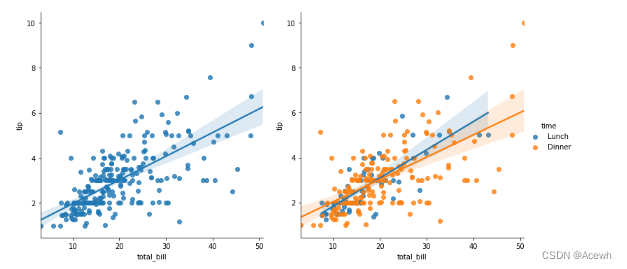
4.残差回归
sns.residplot(data=tip_df,x="total_bill",y="tip")
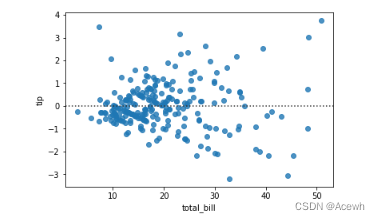
理想情况下残差是随机分布的,图中依然有发散趋势
5.FaceGrid特性(x和y轴即行列参数必须离散型)
FaceGrid绘制的图形将行和列设置为离散类型数据,依据离散变量的不同类别,可以将数据划分为一个个不同的子集,在各个子集上可以分析变量的分布,相当于绘制了变量的条件概率分布。
只有 figure-level水平函数(即displot,relplot,lmplot,catplot)具有FaceGrid特性。
sns.lmplot(data=tip_df,x="total_bill",y="tip",row="smoker",col="time",hue="time")
sns.relplot(data=tip_df,x="total_bill",y="tip",row="smoker",col="time",hue="time")
sns.displot(data=tip_df,x="total_bill",y="tip",row="smoker",col="time",hue="time")
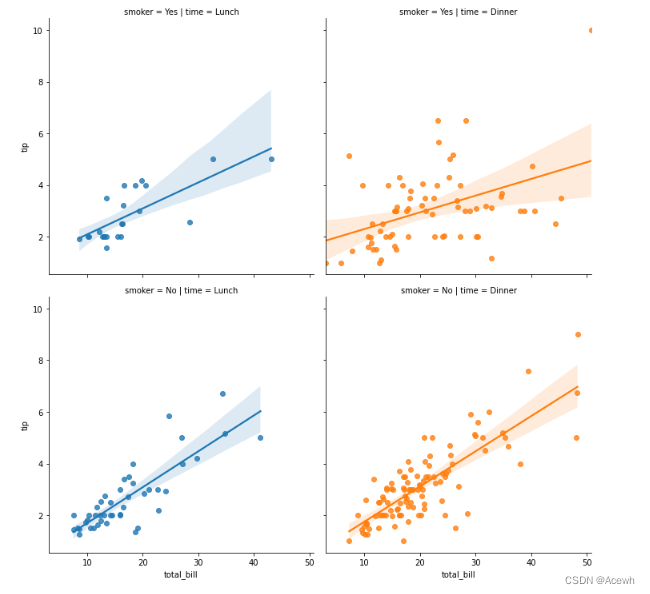
自定义的FaceGrid
g=sns.FacetGrid(data=tip_df,row="smoker",col="time")
g.map(sns.kdeplot,"tip")
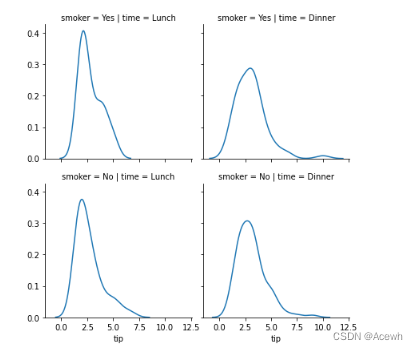
g=sns.FacetGrid(data=tip_df,row="time",col="smoker")
g.map(sns.scatterplot,"total_bill","tip")

6.联合分布
(1).两个变量的联合分布
注意:x和y的数值类型要和kind类型相融,否则报错
sns.displot(data=penguin_df,x="bill_length_mm",y="bill_depth_mm") # 联合直方图
sns.displot(data=penguin_df,x="bill_length_mm",y="bill_depth_mm",kind="kde",rug=True)
# 联合kde曲线
sns.displot(data=penguin_df,x="bill_length_mm",y="bill_depth_mm",kind="kde",thresh=0.2,levels=5)
# 联合kde密度曲线,thresh设置低阈值,levels线的数量
sns.displot(data=dia_df,x="price",y="clarity",log_scale=[True,False]) # 设置是否对数变换

(2).jointplot联合分布以及各自分布
注意:x和y的数值类型要和kind相融,否则报错
# kind : { "scatter" | "kde" | "hist" | "hex" | "reg" | "resid" }
sns.jointplot(data=tip_df,x="total_bill",y="tip") # 默认 kind='scatter'
sns.jointplot(data=tip_df,x="total_bill",y="tip",hue="sex")

JointGrid----自定义的jointplot
# 方式1:
g=sns.JointGrid(data=tip_df,x="total_bill",y="tip")
g.plot(joint_func = sns.histplot, marginal_func = sns.boxplot)

# 方式2:
g=sns.JointGrid(data=tip_df,x="total_bill",y="tip")
g.plot_joint(sns.kdeplot)
g.plot_marginals(sns.histplot,kde=True)

7.pairplot所有连续型变量联合分布
(1).pairplot默认写法
# kind : {'scatter', 'kde', 'hist', 'reg'}
sns.pairplot(data=tip_df) # 绘制所有连续型变量
sns.pairplot(data=car_df,x_vars=["speeding","alcohol"],y_vars=["total"]) # 绘制指定连续型变量
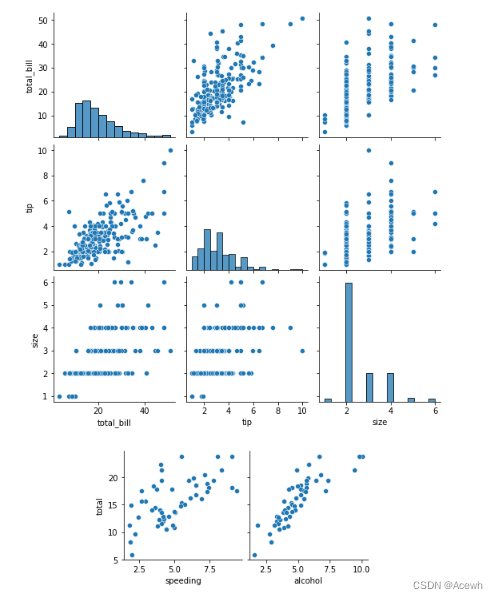
(2).PairGrid----自定义的pairplot
g=sns.PairGrid(data=penguin_df,hue="species")
g.map(sns.scatterplot)

g=sns.PairGrid(data=car_df,x_vars=["total","speeding","alcohol"],y_vars=["total","speeding","alcohol"])
g.map_upper(sns.scatterplot)
g.map_diag(sns.histplot,kde=True)
g.map_lower(sns.regplot)
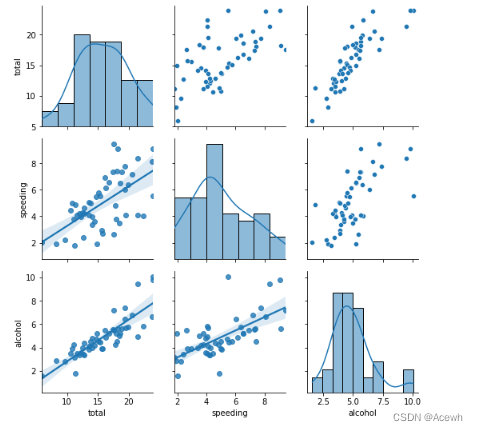
六.离散型多变量关系分析
1.离散型变量的分布
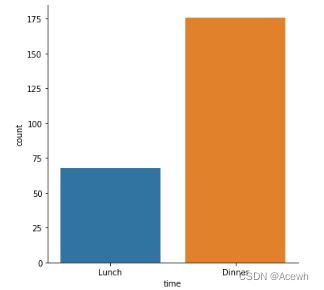
sns.countplot(data=tip_df,x="time")
sns.catplot(data=tip_df,x="time",kind="count")
2.离散型变量和连续型变量的关系
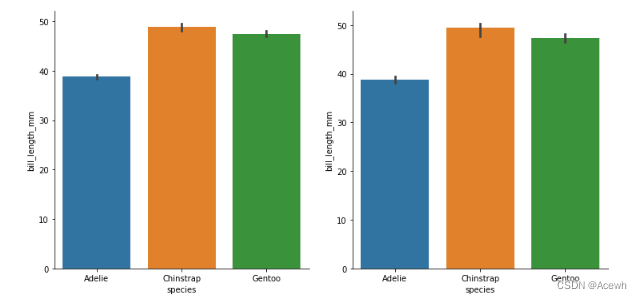
(1).不同类别中数值变量的均值/中值估计:
barplot
# species 每个类别对应 bill_length_mm 的mean和median
sns.barplot(data=penguin_df,x="species",y="bill_length_mm")
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="bar") # 默认estimator=np.mean
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="bar",estimator=np.median)
pointplot
sns.pointplot(data=penguin_df,x="species",y="bill_length_mm",hue="island") # 默认estimator=np.mean
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="point",hue="island")

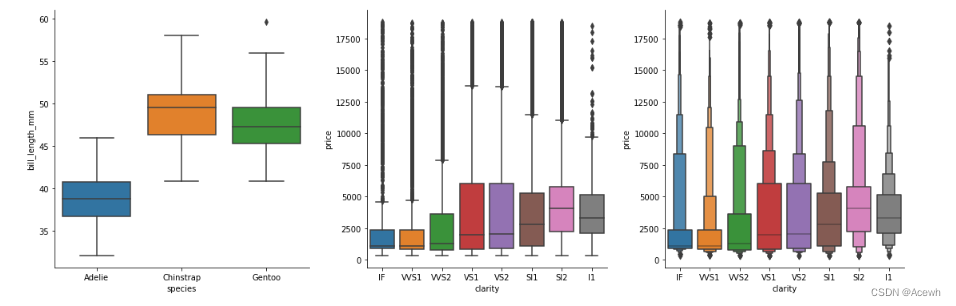
(2).不同类别中数值变量的取值范围:
boxplot适合跨度小的数据,boxenplot适合跨度大的数据
sns.boxplot(data=penguin_df,x="species",y="bill_length_mm")
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="box")
sns.boxen(data=dia_df,x="clarity",y="price")
sns.catplot(data=dia_df,x="clarity",y="price",kind="box")
sns.catplot(data=dia_df,x="clarity",y="price",kind="boxen")
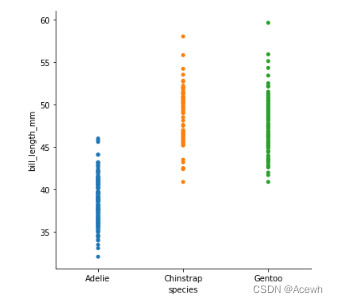
(3).不同类别中数值变量的分布图:
stripplot分布散点图
sns.stripplot(data=penguin_df,x="species",y="bill_length_mm")
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="strip")
# jitter 表示数据重叠部分的重叠度,0或False表示完全重叠
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="strip",jitter=False)
swarmplot分簇散点图
sns.swarmplot(data=penguin_df,x="species",y="bill_length_mm")
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="swarm")
violinplot
sns.violinplot(data=penguin_df,x="species",y="bill_length_mm")
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="violin")
# 绘制violinplot图的同时显示分布,下面两句必须同时使用
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",kind="violin")
sns.swarmplot(data=penguin_df,x="species",y="bill_length_mm",color="w",size=3)
# 分类时左右切分
sns.catplot(data=penguin_df,x="species",y="bill_length_mm",hue="sex",kind="violin",split=True)
















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









