






0. 项目背景介绍
文本在日常生活中无处不在,其携带着丰富且精确的信息,文本检测任务是找出图像或视频中的文字位置,根据语义背景不同可以分为自然场景文本检测和电子文档文本检测,如今已广泛应用于自动驾驶、网络安全、地理定位等领域。

中文是承载中国文化的重要工具,本项目使用PaddleOCR对中文数据集进行训练,输入给定的中文文本图像,找出文本的区域位置,包含多个常见的训练模型如:DB、EAST、SAST、PSE,可自行选择任意模型开展深度学习的训练。
目标检测和文本检测同属于“定位”问题。但是文本检测无需对目标分类,并且文本形状复杂多样。其难点在于:
-
自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度的影响;
-
复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;
-
文本密集甚至重叠会影响文字的检测;
-
文字存在局部一致性,文本行的一小部分,也可视为是独立的文本;

1. 准备数据和模型
1.1 安装PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR
#下载PaddleOCR
!git clone https://gitee.com/paddlepaddle/PaddleOCR
#安装配置文件
%cd PaddleOCR
!pip install --upgrade pip
!pip install -r "requirements.txt" -i https://mirror.baidu.com/pypi/simple
#加快评估速度
!pip3 install lanms-nova
1.2 det_data_lesson_demo数据集
det_data_lesson_demo数据集是中文文本检测通用数据集,包含3009张训练图像和3009张测试图像,场景分别为街景图片、商用广告和电子文档,数据集目录如下所示:
|---lsvt
|---train
|---eval
|---mtwi
|---train
|---eval
|---xfun
|---train
|---val
|---zh_det_train.txt
|---zh_det_val.txt
eval.txt
train.txt
数据集下载链接:
https://paddleocr.bj.bcebos.com/dataset/det_data_lesson_demo.tar
截取部分图像
1.2.1 lsvt-街景图片
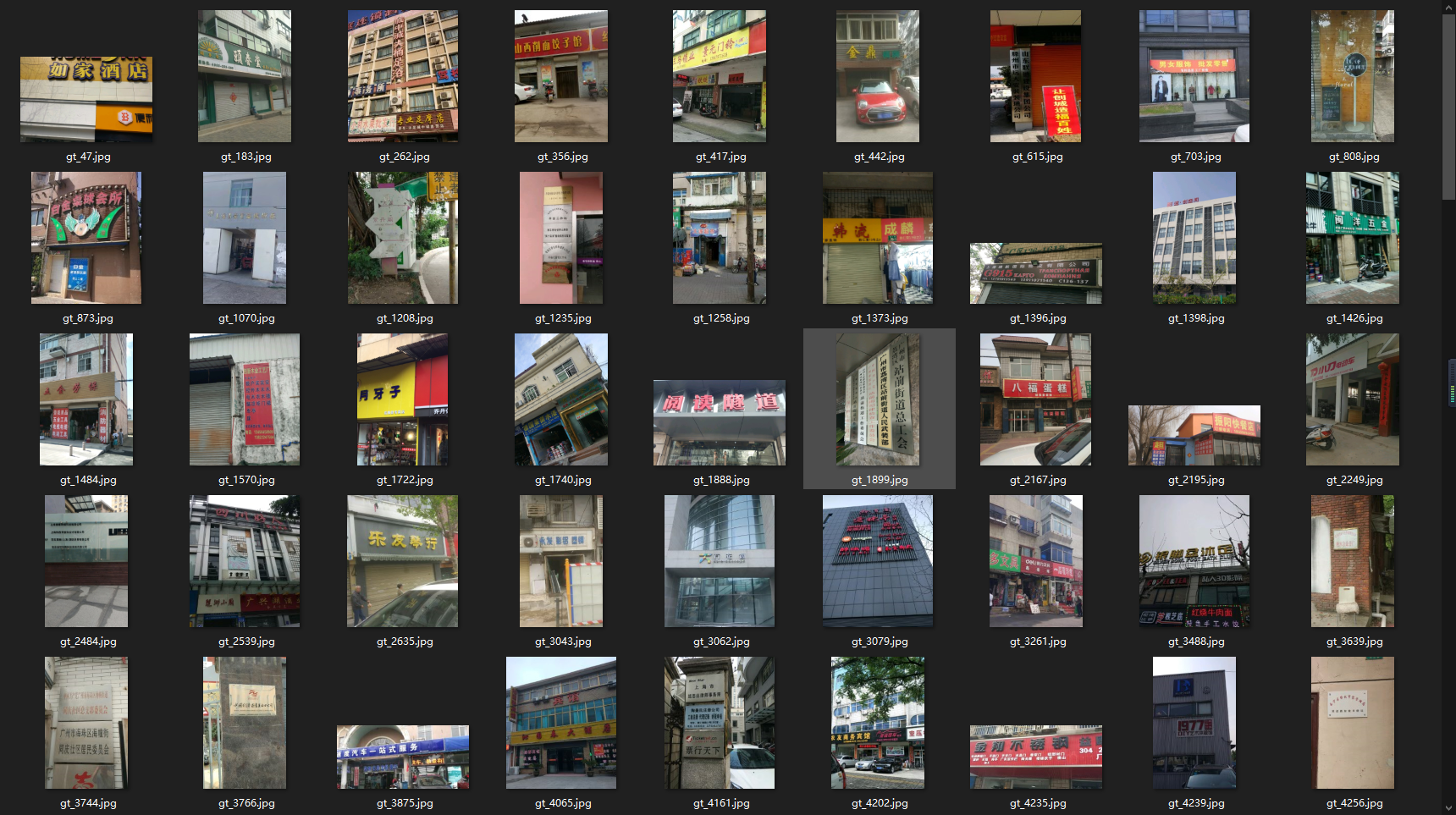
1.2.2 mtwi-商用广告
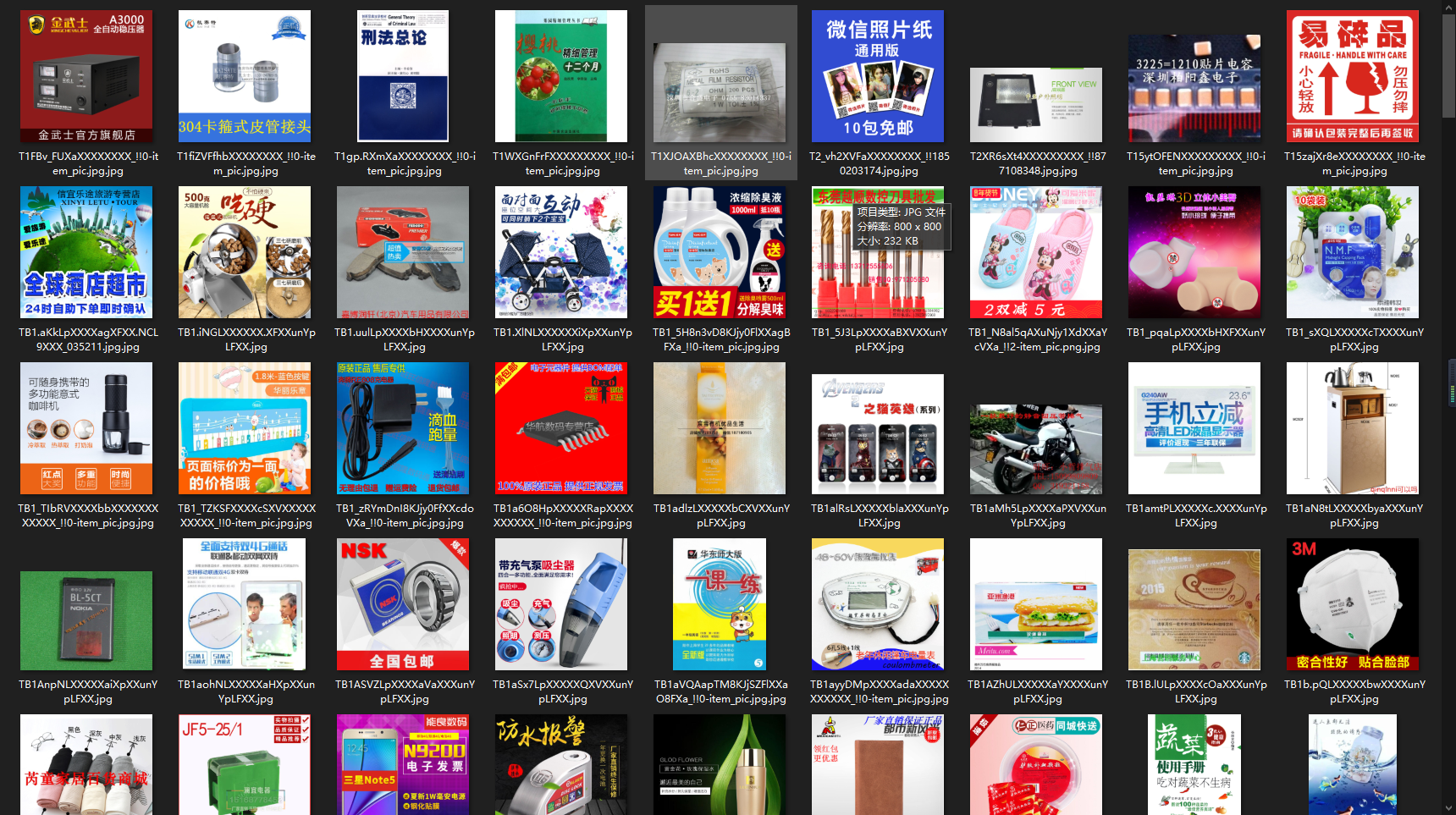
1.2.3 xfun-电子文档

#下载数据集det_data_lesson_demo
!wget https://paddleocr.bj.bcebos.com/dataset/det_data_lesson_demo.tar
!tar -xvf det_data_lesson_demo.tar
!mkdir train_data
!mv det_data_lesson_demo ./train_data/
!rm det_data_lesson_demo.tar
1.3 文本检测预训练模型
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv2_det_slim | 【最新】slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv2_det_cml.yml | 3M | 推理模型 |
| ch_PP-OCRv2_det | 【最新】原始超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv2_det_cml.yml | 3M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_det | slim裁剪版超轻量模型,支持中英文、多语种文本检测 | ch_det_mv3_db_v2.0.yml | 2.6M | 推理模型 |
| ch_ppocr_mobile_v2.0_det | 原始超轻量模型,支持中英文、多语种文本检测 | ch_det_mv3_db_v2.0.yml | 3M | 推理模型 / 训练模型 |
| ch_ppocr_server_v2.0_det | 通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好 | ch_det_res18_db_v2.0.yml | 47M | 推理模型 / 训练模型 |
#下载预训练模型ch_ppocr_server_v2.0_det_train
!wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar
!tar -xvf ch_ppocr_server_v2.0_det_train.tar
!mkdir pretrain_models
!mv ch_ppocr_server_v2.0_det_train ./pretrain_models/ch_ppocr_server_v2.0_det_train
!rm ch_ppocr_server_v2.0_det_train.tar
2.开始启动训练
2.1 启动训练
PaddleOCR有两种配置文件方式
-c指定配置文件路径
-o修改配置文件参数
配置文件参数介绍查询链接

至尊GPU训练环境,Tesla V100显存32GB,效果拉满。
#消除warning报错
import warnings
warnings.filterwarnings('ignore')
#DB
!python tools/train.py -c configs/det/det_r50_vd_db.yml \
-o Global.use_visualdl=True \
Global.epoch_num=100 \
Global.save_epoch_step=10 \
Global.eval_batch_step=[0,200] \
Global.print_batch_step=20 \
Global.pretrained_model='./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy.pdparams' \
Train.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Train.dataset.label_file_list=['./train_data/det_data_lesson_demo/train.txt'] \
Train.loader.batch_size_per_card=16 \
Train.loader.num_workers=0 \
Eval.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Eval.dataset.label_file_list=['./train_data/det_data_lesson_demo/eval.txt'] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=0 \
#EAST
!python tools/train.py -c configs/det/det_r50_vd_east.yml \
-o Global.use_visualdl=True \
Global.epoch_num=100 \
Global.save_epoch_step=10 \
Global.eval_batch_step=[0,200] \
Global.print_batch_step=20 \
Global.pretrained_model='./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy.pdparams' \
Train.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Train.dataset.label_file_list=['./train_data/det_data_lesson_demo/train.txt'] \
Train.loader.batch_size_per_card=16 \
Train.loader.num_workers=0 \
Eval.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Eval.dataset.label_file_list=['./train_data/det_data_lesson_demo/eval.txt'] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=0 \
#SAST
!python tools/train.py -c configs/det/det_r50_vd_sast_icdar15.yml \
-o Global.use_visualdl=True \
Global.epoch_num=100 \
Global.save_epoch_step=10 \
Global.eval_batch_step=[0,200] \
Global.print_batch_step=20 \
Global.pretrained_model='./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy.pdparams' \
Train.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Train.dataset.label_file_list=['./train_data/det_data_lesson_demo/train.txt'] \
Train.dataset.ratio_list=[1.0] \
Train.loader.batch_size_per_card=16 \
Train.loader.num_workers=0 \
Eval.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Eval.dataset.label_file_list=['./train_data/det_data_lesson_demo/eval.txt'] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=0 \
#PSE
!python tools/train.py -c configs/det/det_r50_vd_pse.yml \
-o Global.use_visualdl=True \
Global.epoch_num=100 \
Global.save_epoch_step=10 \
Global.eval_batch_step=[0,200] \
Global.print_batch_step=20 \
Global.pretrained_model='./pretrain_models/ch_ppocr_server_v2.0_det_train/best_accuracy.pdparams' \
Train.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Train.dataset.label_file_list=['./train_data/det_data_lesson_demo/train.txt'] \
Train.loader.batch_size_per_card=16 \
Train.loader.num_workers=0 \
Eval.dataset.data_dir='./train_data/det_data_lesson_demo/' \
Eval.dataset.label_file_list=['./train_data/det_data_lesson_demo/eval.txt'] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=0 \
2.2 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
#需自行修改参数
!python tools/train.py -c config.yml -o Global.checkpoints=./best_accuracy.pdparams
2.3 训练结果
On the ICDAR2015 dataset, the text detection result is as follows:
| Model | Backbone | Precision | Recall | Hmean | Download link |
|---|---|---|---|---|---|
| EAST | ResNet50_vd | 85.80% | 86.71% | 86.25% | trained model |
| EAST | MobileNetV3 | 79.42% | 80.64% | 80.03% | trained model |
| DB | ResNet50_vd | 86.41% | 78.72% | 82.38% | trained model |
| DB | MobileNetV3 | 77.29% | 73.08% | 75.12% | trained model |
| SAST | ResNet50_vd | 91.39% | 83.77% | 87.42% | trained model |
| PSE | ResNet50_vd | 85.81% | 79.53% | 82.55% | trianed model |
| PSE | MobileNetV3 | 82.20% | 70.48% | 75.89% | trianed model |
3. 模型评估与预测
3.1 模型评估
PaddleOCR计算三个OCR检测相关的指标,分别是:Precision、Recall、Hmean(F-Score)。
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。
#DB
!python tools/eval.py -c output/det_r50_vd/config.yml -o Global.checkpoints='output/det_r50_vd/best_accuracy.pdparams'
#EAST
!python tools/eval.py -c output/east_r50_vd/config.yml -o Global.checkpoints='output/east_r50_vd/iter_epoch_50.pdparams'
#SAST
!python tools/eval.py -c output/sast_r50_vd_ic15/config.yml -o Global.checkpoints='output/sast_r50_vd_ic15/best_accuracy.pdparams'
#PSE
!python tools/eval.py -c output/det_r50_vd_pse/config.yml -o Global.checkpoints='output/det_r50_vd_pse/best_accuracy.pdparams'
3.2 模型预测
预测单张图片
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml \
-o Global.infer_img="./doc/imgs_en/img_10.jpg"\
Global.checkpoints="./output/det_db/best_accuracy"
预测文件夹下所有图片
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml \
-o Global.infer_img="./doc/imgs_en/"\
Global.checkpoints="./output/det_db/best_accuracy"
预测结果图片保存在路径’PaddleOCR/output/det_db/det_results/'下:
PaddleOCR/output/det_db/det_results/lsvt.jpg
PaddleOCR/output/det_db/det_results/mtwi.jpg
PaddleOCR/output/det_db/det_results/xfun.jpg
!python3 tools/infer_det.py -c ../parameter/det_mv3_db.yml -o Global.infer_img='../image/' Global.checkpoints='../parameter/det_mv3_db.pdparams'
#原图像
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15, 5))
det_img = cv2.imread('../image/lsvt.jpg')
plt.subplot(1, 3, 1)
plt.imshow(det_img)
plt.title('lsvt')
plt.axis('off')
det_img = cv2.imread('../image/mtwi.jpg')
plt.subplot(1, 3, 2)
plt.imshow(det_img)
plt.title('mtwi')
plt.axis('off')
det_img = cv2.imread('../image/xfun.jpg')
plt.subplot(1, 3, 3)
plt.imshow(det_img)
plt.title('xfun')
plt.axis('off')
(-0.5, 2479.5, 3507.5, -0.5)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-utCgwWHd-1642222782276)(output_28_1.png)]](https://i-blog.csdnimg.cn/blog_migrate/b7d26edba8f7e7edb62a2b253ca9eb7d.png)
3.2.1 lsvt预测结果

3.2.2 mtwi预测结果

3.2.3 xfun预测结果
3.3 模型推理
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
#DB
!python tools/export_model.py -c output/det_r50_vd/config.yml \
-o Global.checkpoints='output/det_r50_vd/best_accuracy.pdparams' \
Global.save_inference_dir='output/det_r50_vd/inference/'
!python tools/eval.py -c output/det_r50_vd/config.yml \
-o Global.checkpoints='output/det_r50_vd/inference/inference.pdiparams'
#EAST
!python tools/export_model.py -c output/east_r50_vd/config.yml \
-o Global.checkpoints='output/east_r50_vd/best_accuracy.pdparams' \
Global.save_inference_dir='output/east_r50_vd/inference/'
!python tools/eval.py -c output/east_r50_vd/config.yml \
-o Global.checkpoints='output/east_r50_vd/inference/inference.pdiparams'
#SAST
!python tools/export_model.py -c output/sast_r50_vd_ic15/config.yml \
-o Global.checkpoints='output/sast_r50_vd_ic15/best_accuracy.pdparams' \
Global.save_inference_dir='output/sast_r50_vd_ic15/inference/'
!python tools/eval.py -c output/sast_r50_vd_ic15/config.yml \
-o Global.checkpoints='output/sast_r50_vd_ic15/inference/inference.pdiparams'
#PSE
!python tools/export_model.py -c output/det_r50_vd_pse/config.yml \
-o Global.checkpoints='output/det_r50_vd_pse/best_accuracy.pdparams' \
Global.save_inference_dir='output/det_r50_vd_pse/inference/'
!python tools/eval.py -c output/det_r50_vd_pse/config.yml \
-o Global.checkpoints='output/det_r50_vd_pse/inference/inference.pdiparams'
4. 总结与提升
本项目使用PaddleOCR对中文文本数据集进行检测,采用预训练加微调的方式进行模型训练,开始阶段评价指标hmean从0开始缓慢提升,训练过程中如果发现评估时间过长,可以在训练轮次到50之后开始评估,hmean基本可以达到[0.4, 0.6]这个区间,想进一步提升精度可以尝试如下配置方式。
Architecture: # 模型结构定义
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3 # 配置骨干网络
scale: 0.5
model_name: large
disable_se: True # 去除SE模块
Neck:
name: DBFPN # 配置DBFPN
out_channels: 96 # 配置 inner_channels
Head:
name: DBHead
k: 50
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine # 配置cosine学习率下降策略
learning_rate: 0.001 # 初始学习率
warmup_epoch: 2 # 配置学习率预热策略
regularizer:
name: 'L2' # 配置L2正则
factor: 0 # 正则项的权重

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









