







引言:
在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。
一、算法介绍
回归树是决策树的一种,用于处理回归问题,即预测连续值的任务。与分类树相比,回归树的目标是预测一个数量的输出。回归树模型通过将特征空间划分为一系列的简单区域来工作。为了做出预测,它使用每个区域内目标变量的平均值。这种方法是决策树理论的一部分,通过递归地将数据集分割成越来越小的子集来构建树。
二、算法原理
构建回归树的过程包括以下几个步骤:
-
选择最佳分割特征与点:
回归树通过选择最佳分割特征和分割点来递归地划分数据集。分割的选择基于最小化某种度量标准,通常是均方误差(MSE)。均方误差可以定义为:
M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 MSE = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2 MSE=N1i=1∑N(yi−y^i)2
其中, y i y_i yi 是样本点的真实值, y ^ i \hat{y}_i y^i 是区域内样本点的平均响应值。
-
递归分割:
选择最优分割后,数据集被分为两个子节点。接下来,同样的分割过程应用于每个子节点,递归进行,直到满足停止条件(如达到指定的树的最大深度,或者每个节点的最小样本数)。 -
剪枝:
为防止过拟合,需要对生成的树进行剪枝。剪枝通过移除树的部分分支来实现,这些分支对于模型的泛化能力提升没有帮助。常用的剪枝技术包括成本复杂度剪枝。
三、案例分析
此部分还是使用加利福尼亚房屋数据集,该数据集包含20640个样本,每个样本有8个特征,这些特征描述了加利福尼亚地区的房屋和人口统计特点,目标值是房屋的中位数价格。
首先,我们需要加载数据,划分训练集和测试集,然后训练一个回归树模型,并且可视化。最后,我们将评估回归树在测试集上的表现。在评估完模型后,我们可以通过绘制实际房价与预测房价的散点图来直观地展示模型的预测性能。
完整代码如下:
数据准备和回归树模型:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn import tree
from sklearn.metrics import mean_squared_error
# 加载数据
data = fetch_california_housing()
X = data.data
y = data.target
features = data.feature_names
data_df = pd.DataFrame(X, columns=features)
data_df['Target'] = y
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建回归树模型
regressor = DecisionTreeRegressor(max_depth=5, random_state=42)
regressor.fit(X_train, y_train)

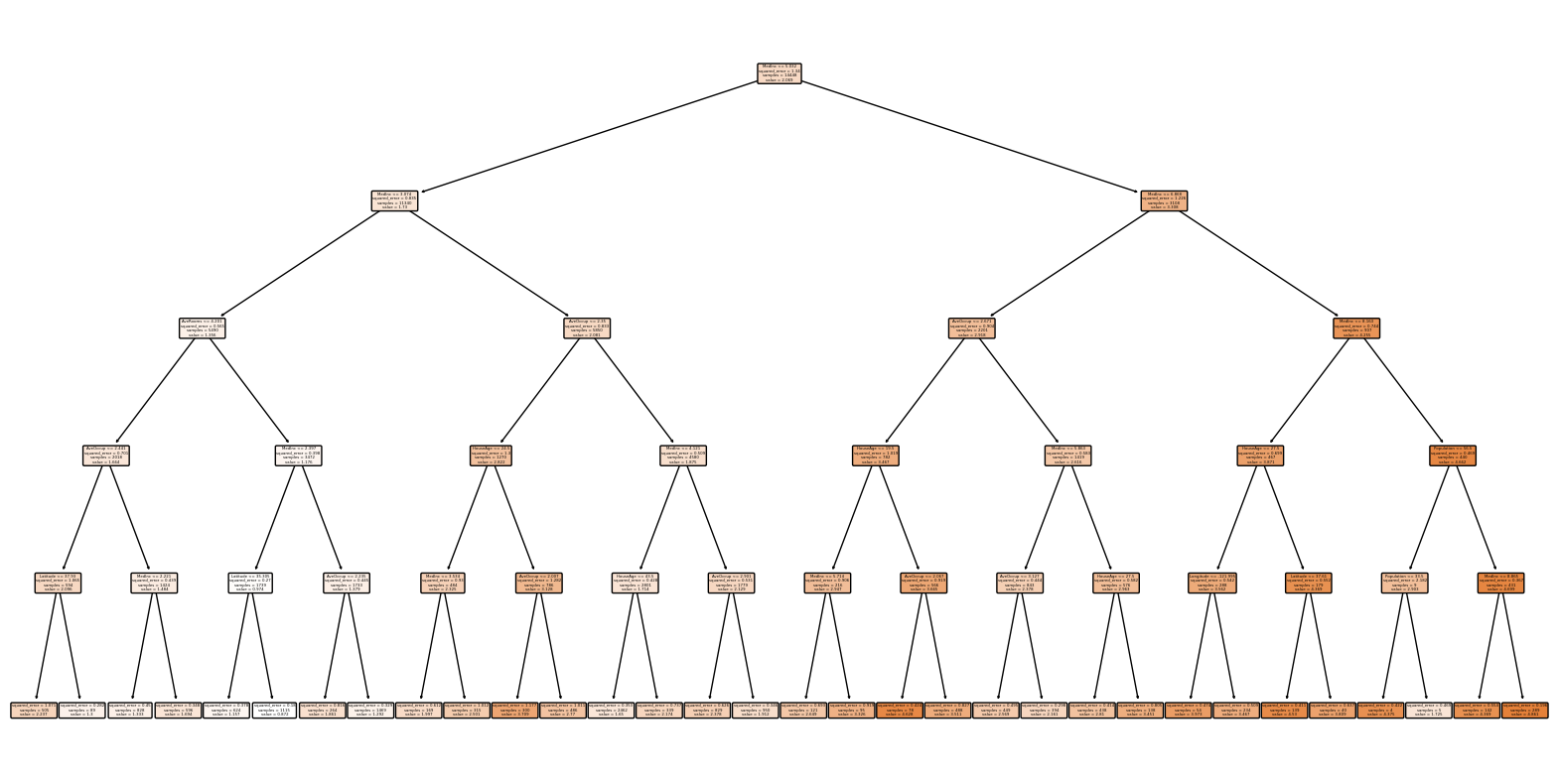
模型可视化:
plt.figure(figsize=(20,10))
tree.plot_tree(regressor, filled=True, feature_names=data.feature_names, rounded=True)
plt.show()
模型评估:
# 在测试集上进行预测
y_pred = regressor.predict(X_test)
# 计算并打印MSE
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
均方误差(MSE): 0.52。
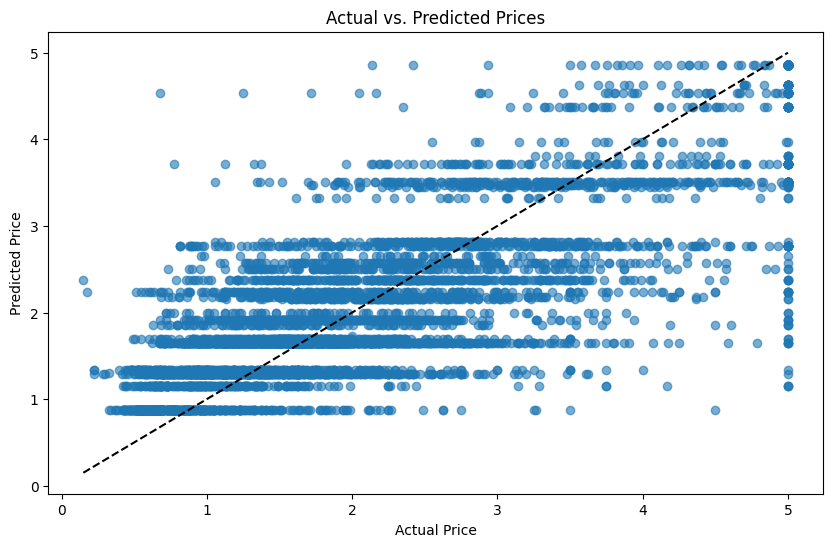
预测结果可视化:
# 绘制实际值与预测值
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'k--') # 绘制y=x参考线
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('Actual vs. Predicted Prices')
plt.show()
















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











