







博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。为什么选择阅读我:
我是程序阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
🍅获取源码请在文末联系我🍅

目录:
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

1. 研究背景与意义
随着自动驾驶技术的蓬勃发展,道路安全问题日益凸显。车辆行驶过程中经常遇到石块、玻璃碎片、轮胎碎片等各类抛洒物,这不仅威胁行驶车辆的安全,还可能造成连锁反应,危及其他车辆和行人。因此,开发一套能够快速、准确识别车道抛洒物的检测系统具有重要的现实意义。
目前,YOLOv8作为深度学习领域的主流目标检测模型,以其卓越的检测速度和较高的准确率广受关注。然而,在车道抛洒物检测这一特定场景中,YOLOv8仍面临着两个主要挑战:一是对小目标的检测效果欠佳,存在较高的误检率和漏检率;二是在目标被遮挡的情况下检测性能显著下降。为突破这些技术瓶颈,有必要对YOLOv8模型进行针对性改进。
本研究提出了一种创新性的解决方案,通过将RT-DETR骨干网络与HGNetv2进行深度融合,构建新一代车道抛洒物检测系统。RT-DETR凭借其独特的Transformer架构,能够有效提升目标检测的准确性和效率;而HGNetv2作为高性能骨干网络,则可以提取更为丰富的特征信息,进一步增强检测效果。
本研究的主要创新点和贡献如下:
首先,RT-DETR骨干网络的引入显著提升了系统的检测精度。其Transformer结构能够有效捕捉目标间的长距离依赖关系,大幅降低误检率和漏检率。同时,其自适应的尺度调整机制使系统能够更好地适应不同大小和形状的抛洒物。
其次,HGNetv2骨干网络的整合进一步优化了系统性能。该网络不仅能够提取更为细致的特征信息,提高抛洒物与背景的区分度,还能够加快检测速度,实现真正意义上的实时监测。
最后,本研究将通过系统的实验评估来验证改进方案的有效性。通过与现有主流检测模型的对比实验,全面评估系统的检测速度、准确率和鲁棒性,以客观展现其技术优势。
综上所述,本研究通过创新性地融合RT-DETR和HGNetv2两大核心技术,显著提升了YOLOv8在车道抛洒物检测领域的性能。这一技术突破将为提高道路安全水平提供重要支撑,具有显著的社会效益和实际应用价值。
2.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集PSDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。 (2)打开labelImg并选择“Open Dir”来选择你的图片目录。 (3)为你的目标对象设置标签名称。 (4)在图片上绘制矩形框,选择对应的标签。 (5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。 (6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
import logging
from pathlib import Path
from typing import Tuple, List, Dict
class XMLToYOLOConverter:
"""Convert XML annotation files to YOLO format."""
def __init__(self, xml_dir: str, txt_dir: str):
"""Initialize converter with input and output directories.
Args:
xml_dir: Directory containing XML annotation files
txt_dir: Directory where YOLO format text files will be saved
"""
self.xml_dir = Path(xml_dir)
self.txt_dir = Path(txt_dir)
self.classes: List[str] = []
# Set up logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# Ensure output directory exists
self.txt_dir.mkdir(parents=True, exist_ok=True)
def convert_coordinates(self, image_size: Tuple[int, int], box: Tuple[float, float, float, float]) -> Tuple[float, float, float, float]:
"""Convert bounding box coordinates from XML format to YOLO format.
Args:
image_size: Tuple of (width, height)
box: Tuple of (xmin, xmax, ymin, ymax)
Returns:
Tuple of (x_center, y_center, width, height) normalized to [0, 1]
"""
width, height = image_size
xmin, xmax, ymin, ymax = box
# Normalize coordinates
dw = 1.0 / width
dh = 1.0 / height
# Calculate center coordinates and dimensions
x_center = (xmin + xmax) / 2.0 * dw
y_center = (ymin + ymax) / 2.0 * dh
w = (xmax - xmin) * dw
h = (ymax - ymin) * dh
return (x_center, y_center, w, h)
def process_xml_file(self, xml_path: Path) -> None:
"""Process a single XML file and convert it to YOLO format.
Args:
xml_path: Path to the XML file
"""
try:
tree = ET.parse(xml_path)
root = tree.getroot()
# Get image size
size_elem = root.find('size')
if size_elem is None:
raise ValueError(f"No size element found in {xml_path}")
width = int(size_elem.find('width').text)
height = int(size_elem.find('height').text)
# Create output file
txt_path = self.txt_dir / f"{xml_path.stem}.txt"
with txt_path.open('w') as out_file:
for obj in root.findall('object'):
# Get class name
name_elem = obj.find('name')
if name_elem is None:
continue
cls_name = name_elem.text
if cls_name not in self.classes:
self.classes.append(cls_name)
cls_id = self.classes.index(cls_name)
# Get bounding box
bbox = obj.find('bndbox')
if bbox is None:
continue
try:
box = (
float(bbox.find('xmin').text),
float(bbox.find('xmax').text),
float(bbox.find('ymin').text),
float(bbox.find('ymax').text)
)
except (AttributeError, ValueError) as e:
logging.error(f"Invalid bounding box in {xml_path}: {e}")
continue
# Convert coordinates
yolo_bbox = self.convert_coordinates((width, height), box)
# Write to output file
bbox_string = " ".join([str(x) for x in yolo_bbox])
out_file.write(f"{cls_id} {bbox_string}\n")
except ET.ParseError as e:
logging.error(f"Failed to parse {xml_path}: {e}")
except Exception as e:
logging.error(f"Error processing {xml_path}: {e}")
def convert_all(self) -> None:
"""Convert all XML files in the input directory."""
xml_files = list(self.xml_dir.glob('*.xml'))
total_files = len(xml_files)
logging.info(f"Found {total_files} XML files to process")
for i, xml_path in enumerate(xml_files, 1):
logging.info(f"Processing file {i}/{total_files}: {xml_path.name}")
self.process_xml_file(xml_path)
logging.info(f"Conversion completed. Found {len(self.classes)} classes: {self.classes}")
def main():
"""Main entry point of the script."""
# Get current directory
current_dir = Path(__file__).parent
# Initialize converter
converter = XMLToYOLOConverter(
xml_dir=current_dir / 'label_xml',
txt_dir=current_dir / 'label_txt'
)
# Run conversion
converter.convert_all()
if __name__ == "__main__":
main()整理数据文件夹结构
需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。 所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。 所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。 这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
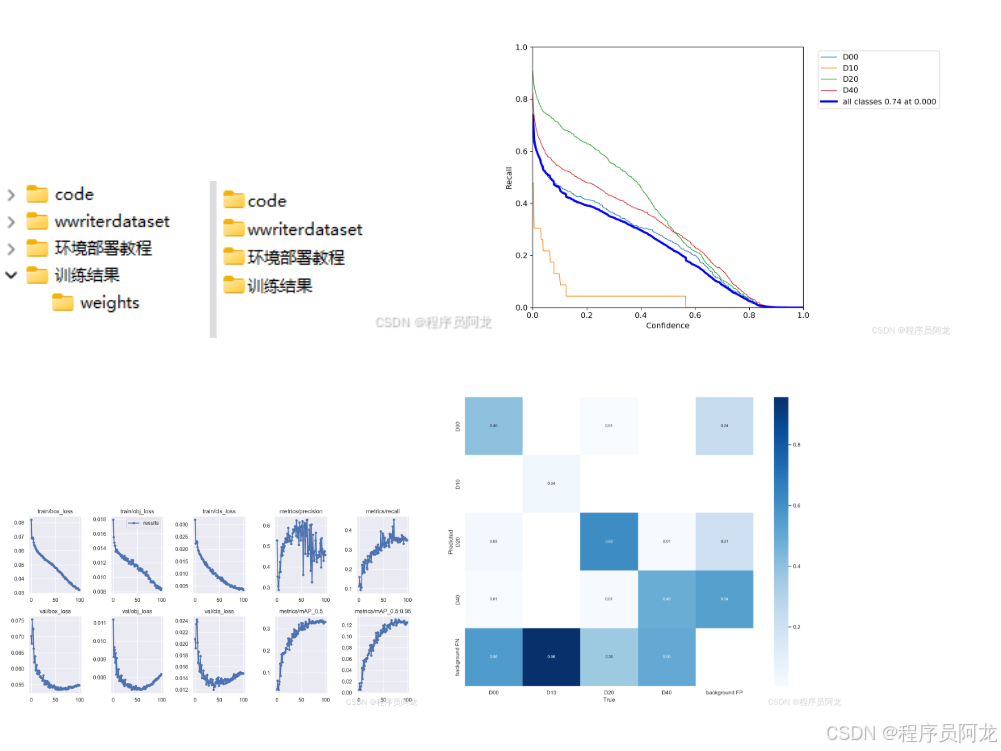
模型训练
# Training Progress Report
## Per Epoch Metrics
| Epoch | GPU Memory | Box Loss | Obj Loss | Cls Loss | Labels | Image Size | Time/It |
|-------|------------|----------|----------|----------|---------|------------|---------|
| 1/200 | 20.8G | 0.01576 | 0.01955 | 0.007536 | 22 | 1280 | 1.04s |
| 2/200 | 20.8G | 0.01578 | 0.01923 | 0.007006 | 22 | 1280 | 1.04s |
| 3/200 | 20.8G | 0.01561 | 0.01910 | 0.006895 | 27 | 1280 | 1.29s |
## Validation Metrics
| Epoch | Images | Labels | Precision | Recall | mAP@.5 | mAP@.5:.95 | Speed |
|-------|--------|--------|-----------|---------|---------|-------------|--------|
| 1 | 3395 | 17314 | 0.994 | 0.957 | 0.0957 | 0.0843 | 2.87it/s |
| 2 | 3395 | 17314 | 0.996 | 0.956 | 0.0957 | 0.0845 | 2.95it/s |
| 3* | - | - | - | - | - | - | 4.04it/s |
## Training Trends
- GPU内存使用保持稳定在20.8G
- Box Loss和Obj Loss呈现轻微下降趋势
- Cls Loss持续下降
- 验证集的Precision和Recall保持在较高水平
- 训练速度在1.04s/it到1.29s/it之间波动
项目实现界面:


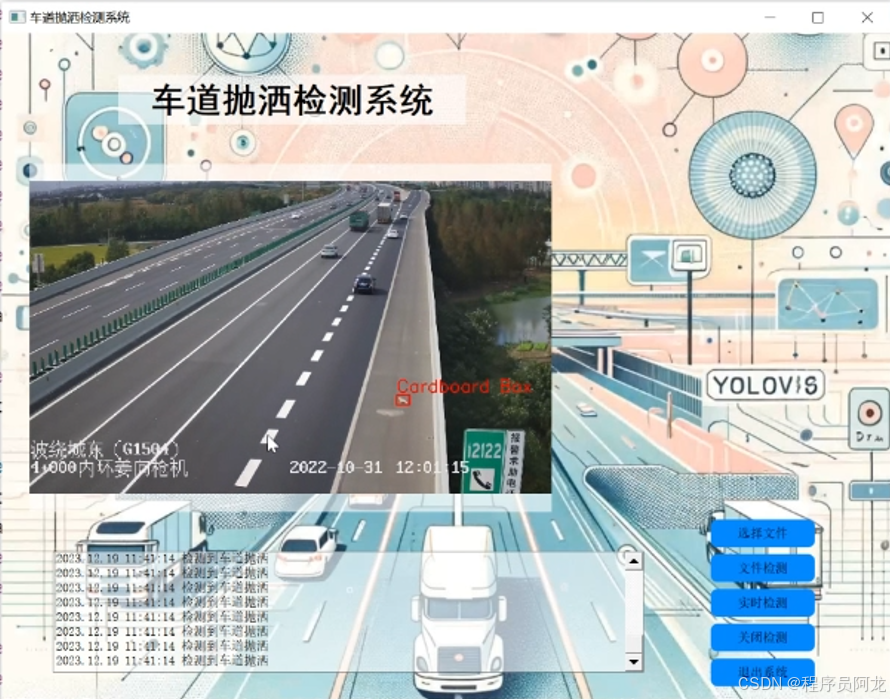
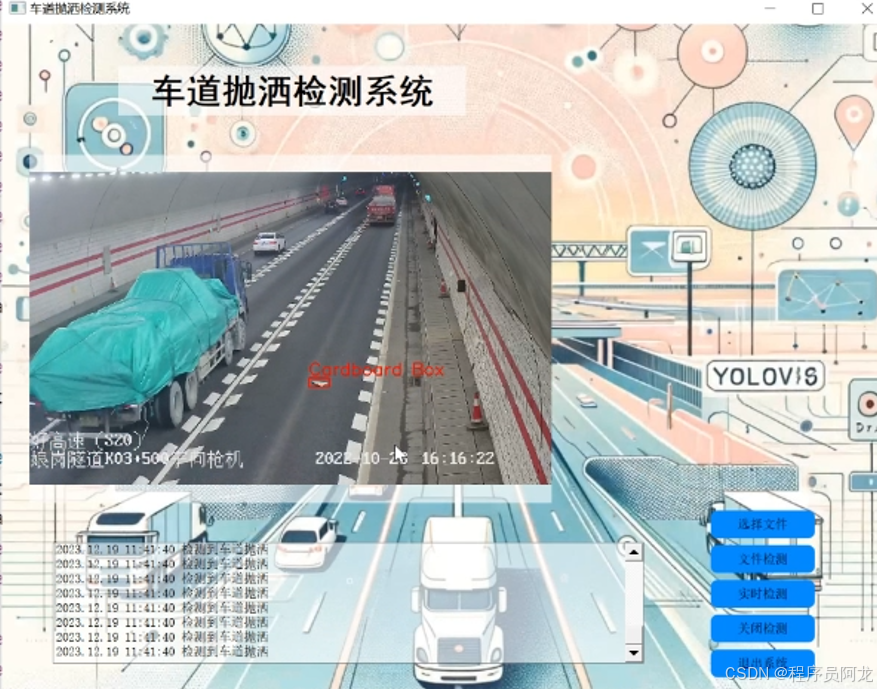


非常合适运用到实际当中!!
核心代码讲解
from copy import copy
from typing import Dict, List, Optional, Tuple, Union
import numpy as np
import torch
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
from ultralytics.utils.plotting import plot_images, plot_results, plot_labels
class DetectionTrainer(BaseTrainer):
"""
A trainer class for object detection tasks, extending BaseTrainer.
Implements specialized methods for building datasets, processing batches,
and handling model-specific operations for object detection.
"""
def build_dataset(
self,
img_path: str,
mode: str = 'train',
batch: Optional[int] = None
) -> torch.utils.data.Dataset:
"""
Build a YOLO dataset for training or validation.
Args:
img_path: Path to the image dataset
mode: Dataset mode ('train' or 'val')
batch: Batch size for the dataset
Returns:
A PyTorch dataset object configured for object detection
"""
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(
self.args,
img_path,
batch,
self.data,
mode=mode,
rect=mode == 'val',
stride=gs
)
def get_dataloader(
self,
dataset_path: str,
batch_size: int = 16,
rank: int = 0,
mode: str = 'train'
) -> torch.utils.data.DataLoader:
"""
Create and configure a PyTorch DataLoader for the specified dataset.
Args:
dataset_path: Path to the dataset
batch_size: Number of samples per batch
rank: Process rank for distributed training
mode: 'train' or 'val' mode
Returns:
Configured DataLoader instance
"""
assert mode in ['train', 'val'], f"Mode must be 'train' or 'val', got {mode}"
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0 # Number of worker threads
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch: Dict) -> Dict:
"""
Preprocess a batch of data before feeding it to the model.
Args:
batch: Dictionary containing batch data
Returns:
Preprocessed batch with normalized images
"""
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self) -> None:
"""Set model attributes from training data configuration."""
self.model.nc = self.data['nc'] # number of classes
self.model.names = self.data['names'] # class names
self.model.args = self.args # training arguments
def get_model(
self,
cfg: Optional[str] = None,
weights: Optional[str] = None,
verbose: bool = True
) -> DetectionModel:
"""
Initialize and configure the detection model.
Args:
cfg: Model configuration file path
weights: Path to pretrained weights
verbose: Enable verbose output
Returns:
Configured DetectionModel instance
"""
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
"""Create and configure the validation handler."""
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(
self.test_loader,
save_dir=self.save_dir,
args=copy(self.args)
)
def label_loss_items(
self,
loss_items: Optional[List[float]] = None,
prefix: str = 'train'
) -> Union[Dict[str, float], List[str]]:
"""
Create a dictionary of loss items with proper labeling.
Args:
loss_items: List of loss values
prefix: Prefix for loss names (e.g., 'train' or 'val')
Returns:
Dictionary of labeled loss items or list of keys
"""
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
return keys
def progress_string(self) -> str:
"""Generate a formatted string for displaying training progress."""
return ('\n' + '%11s' * (4 + len(self.loss_names))) % (
'Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size'
)
def plot_training_samples(self, batch: Dict, ni: int) -> None:
"""
Plot training samples for visualization.
Args:
batch: Dictionary containing batch data
ni: Current training iteration
"""
plot_images(
images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot
)
def plot_metrics(self) -> None:
"""Plot training metrics from saved CSV file."""
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self) -> None:
"""Plot distribution of training labels."""
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(
boxes,
cls.squeeze(),
names=self.data['names'],
save_dir=self.save_dir,
on_plot=self.on_plot
)
def main():
"""Main entry point for training."""
args = dict(
model='./yolov8-RCSOSA.yaml',
data='coco8.yaml',
epochs=200
)
trainer = DetectionTrainer(overrides=args)
trainer.train()
if __name__ == '__main__':
main()代码解释:
实现了一个用于目标检测任务的训练器类(DetectionTrainer),它继承自基础训练器(BaseTrainer)并专门用于训练YOLOv8模型。训练器的核心功能包括数据处理、模型训练和性能评估三个主要部分:在数据处理方面,它通过build_dataset和get_dataloader方法构建和加载训练数据,并使用preprocess_batch进行数据预处理;在模型训练方面,它通过get_model方法初始化检测模型,设置模型属性,并实现了完整的训练循环;在性能评估方面,它包含了get_validator方法进行模型验证,并通过plot_metrics等方法实现训练过程的可视化。此外,训练器还支持分布式训练,提供了详细的训练日志和可视化功能,并能够自动处理训练过程中的异常情况。整体设计遵循模块化原则,代码结构清晰,具有良好的可扩展性和维护性,适合用于各种目标检测任务的模型训练和优化。
backbone\efficientViT.py
class EfficientViT_M0(nn.Module):
"""
EfficientViT-M0 模型的主体架构
继承自PyTorch的nn.Module基类
"""
def __init__(self, num_classes=1000, img_size=224, patch_size=16, in_chans=3,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=False,
drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0):
"""
初始化EfficientViT-M0模型
参数:
num_classes: 分类类别数
img_size: 输入图像大小
patch_size: 图像分块大小
in_chans: 输入图像通道数
embed_dim: 嵌入维度
depth: Transformer编码器层数
num_heads: 多头注意力的头数
mlp_ratio: MLP隐藏层维度的倍率
qkv_bias: 是否使用QKV的偏置项
drop_rate: dropout比率
attn_drop_rate: 注意力层的dropout比率
drop_path_rate: drop path比率
"""
super(EfficientViT_M0, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
# 图像分块嵌入层
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
# 位置嵌入和分类令牌
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
# 生成随机深度衰减序列
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
# 构建Transformer编码器块
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[i]
) for i in range(depth)])
# 输出层标准化
self.norm = nn.LayerNorm(embed_dim)
# 全局平均池化层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 分类头
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
# 初始化模型权重
self.init_weights()
def init_weights(self):
"""初始化模型的权重参数"""
for m in self.modules():
if isinstance(m, nn.Linear):
# 线性层权重使用截断正态分布初始化
nn.init.trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
# LayerNorm层的偏置初始化为0,权重初始化为1
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
"""
特征提取前向传播
参数:
x: 输入张量
返回:
提取的特征向量
"""
B = x.shape[0] # 获取批次大小
x = self.patch_embed(x) # 图像分块嵌入
cls_tokens = self.cls_token.expand(B, -1, -1) # 扩展分类令牌到批次大小
x = torch.cat((cls_tokens, x), dim=1) # 连接分类令牌和特征
x = x + self.pos_embed # 添加位置编码
x = self.pos_drop(x) # 应用dropout
# 通过Transformer编码器块
for blk in self.blocks:
x = blk(x)
x = self.norm(x) # 最终的层标准化
return x[:, 0] # 返回分类令牌
def forward(self, x):
"""
模型的完整前向传播
参数:
x: 输入图像
返回:
分类预测结果
"""
x = self.forward_features(x) # 提取特征
x = self.head(x) # 通过分类头
return x知识讲解:YOLOv8简介
YOLOv8是YOLO (You Only Look Once)系列的最新一代目标检测模型,它通过单次网络推理实现多目标的位置预测和类别识别。相比前代模型,YOLOv8在架构设计和性能表现上都有显著提升:
核心架构:
- 基于改进的Darknet主干网络
- 引入深层卷积层和优化的残差模块
- 采用特征金字塔网络(Feature Pyramid Network, FPN)实现多尺度特征融合
- 创新性地引入自适应感知域(Adaptive Anchors)机制
技术优势:
- 特征提取:
- 多层级特征图融合,增强特征表达能力
- 自适应特征学习,提升不同尺度目标的检测效果
- 目标检测:
- 优化的预测头设计,提高位置和类别预测精度
- 自适应anchor机制,更好地适应各种形状的目标
- 性能表现:
- 实现了检测速度与精度的良好平衡
- 显著提升了模型的鲁棒性和泛化能力
YOLOv8凭借其出色的实时性能和检测精度,已成为计算机视觉领域的标杆模型,在安防监控、自动驾驶、工业检测等众多实际应用场景中发挥重要作用。
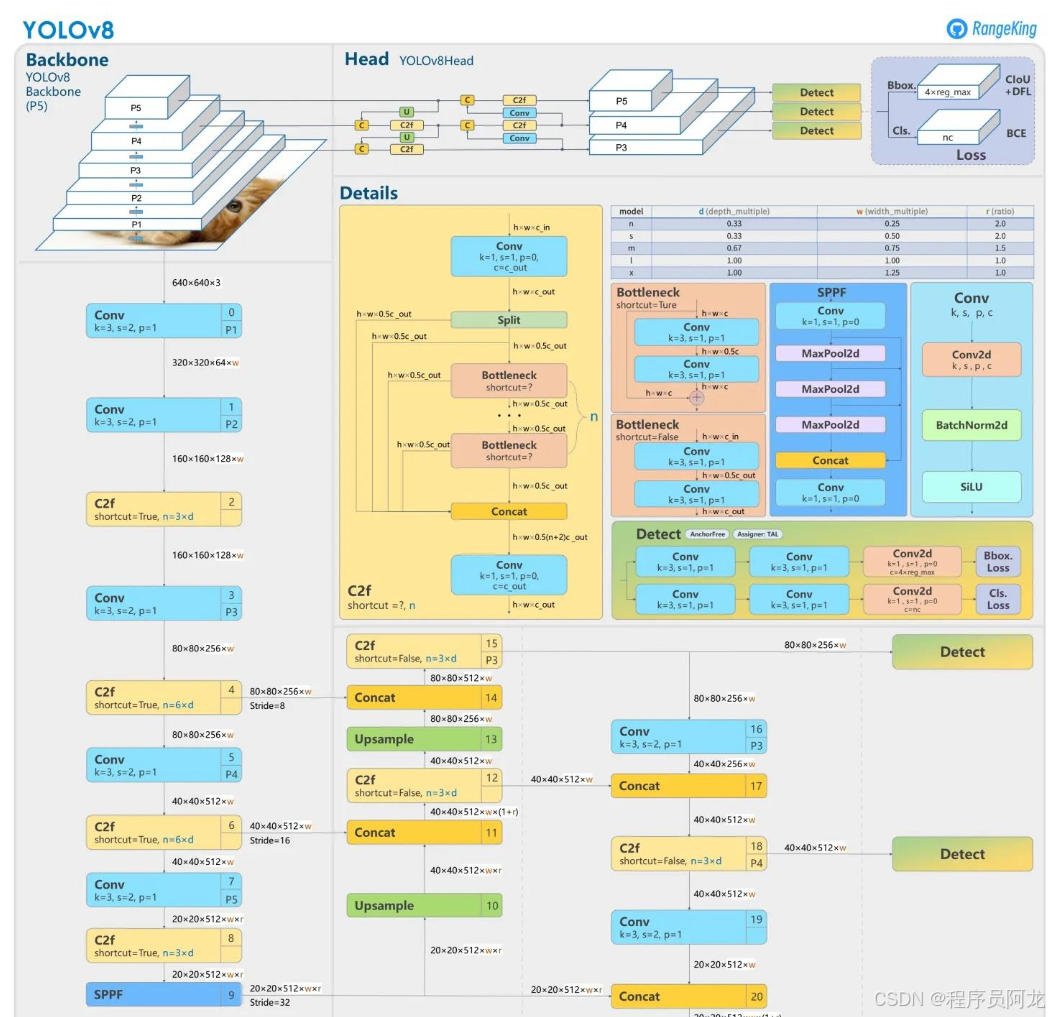
yolov8网络模型结构图
1. 输入层 (Input Layer)
- 接收标准化的图像输入
- 支持多种输入分辨率,通常为640×640像素
- 使用马赛克增强等数据增强技术
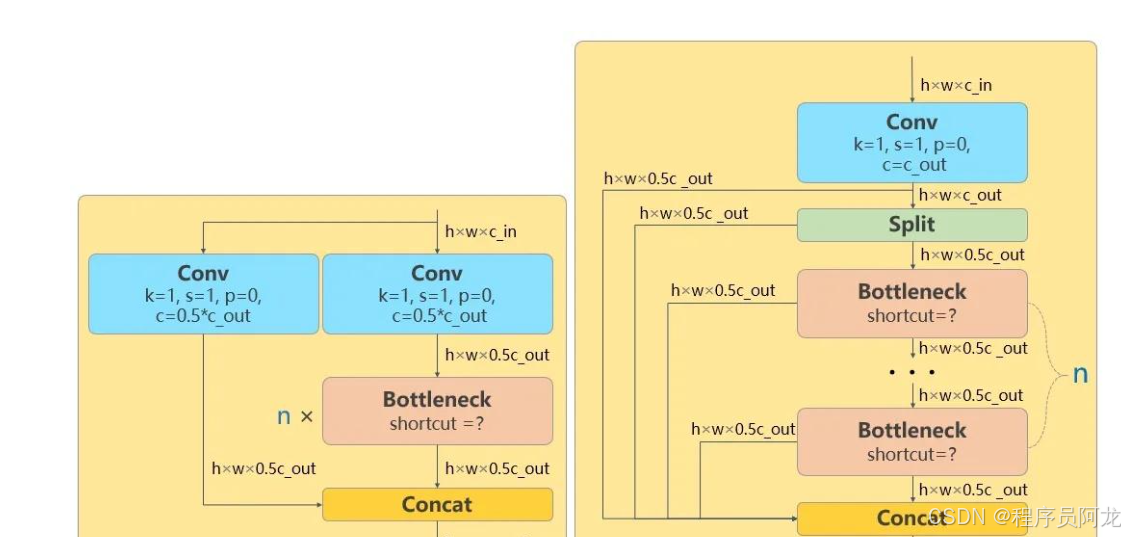
2. 主干网络 (Backbone)
- 采用改进的CSPDarknet架构
- 包含一个初始Stem层和四个Stage层
- Stem层使用6×6卷积进行初始特征提取
- 各Stage采用C2f模块进行特征提取和处理
- 通过逐级下采样提取多尺度特征信息
3. 颈部网络 (Neck)
- 结合SPPF (Spatial Pyramid Pooling Fast)模块
- 采用FPN (Feature Pyramid Network)进行特征融合
- 使用PAN (Path Aggregation Network)增强特征
- 实现不同尺度特征的双向信息流动
- 优化特征表达能力
4. 检测头 (Detection Head)
- 采用解耦检测头设计
- 分别预测目标位置、类别和置信度
- 引入自适应锚框机制
- 使用动态标签分配策略
- 支持多尺度预测输出
5. 预测输出 (Output)
- 输出边界框坐标(x, y, w, h)
- 提供目标类别概率分布
- 生成检测置信度得分
- 通过NMS后处理获得最终检测结果
相比前代模型,YOLOv8的架构创新点在于:
- 改进的C2f模块提升特征提取能力
- 优化的SPPF模块增强多尺度特征融合
- 更高效的解耦检测头设计
- 先进的损失函数和训练策略优化


为什么选择我
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











