







目录
2.1 绘制散点图分析产品开发部已离职的员工的评分与平均工作时间
2.3 基于人员离职数据,绘制IT部部门员工工龄、年度评分折线图
2.5 基于波士顿房价数据绘制犯罪率、一氧化氮含量、房间数与房屋价格两两之间的相关性
2.6 基于人员离职率数据,对销售部已离职的员工数据绘制不同颜色的数据子集
2.7 根据销售部已离职的员工数据,通过relplot函数绘制单构面散点图
2.8 根据部门为IT部的数据,传入分类变量薪资和工作事故到col和row中,绘制网格图
3.1基于离职率数据,使用barplot函数绘制各部门人员总数条形图
3.4 基于人员离职率数据,绘制简单水平分布散点图分析销售部已离职的员工每月平均工作小时
3.5 基于人员离职率数据,根据高薪在职的员工数据,使用swarmplot函数绘制简单的分布密度散点图
3.7 基于波士顿房价数据,通过pairplot函数绘制多变量之间的关系图
4.1 基于波士顿房价数据,利用regplot函数绘制修改置信区间ci参数前后的线性回归拟合图
4.2 基于波士顿房价数据,以河流穿行为类别绘制低收入人群与房屋价格两个变量的回归网格组合图
人的一生可能根本没有分明的四季,一直在光影斑驳的林子下走走停停。
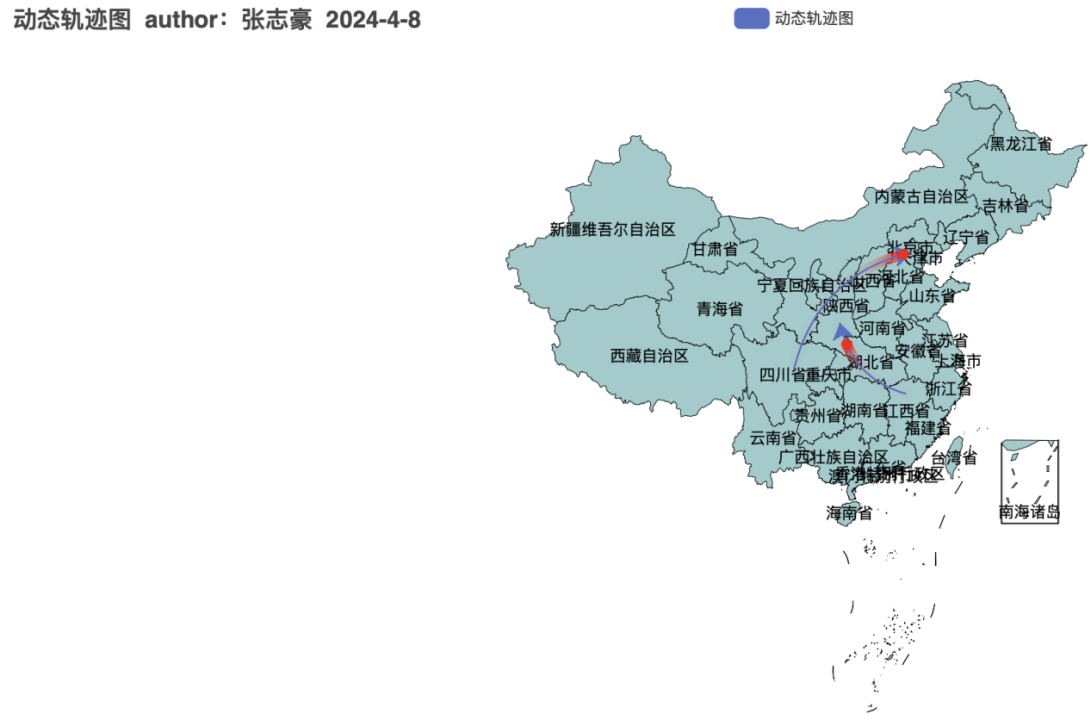
一、绘制动态轨迹图
1.1 代码实现
# 导入必要库
from pyecharts.charts import Geo
from pyecharts.globals import ChartType
from pyecharts import options as opts
# 修改已有的数据
z1 = [
("四川省", "北京市"),
("江西省", "西安市"),
]
geo = (
# 设置图形大小
Geo(init_opts=opts.InitOpts(width="1200px", height="600px"))
.add_schema(
# 地图类型为中国地图
maptype="china",
itemstyle_opts=opts.ItemStyleOpts(color="#99CCCC", border_color="black"),
label_opts=opts.LabelOpts(is_show=True),
)
.add(
"动态轨迹图 ",
z1,
# 参数设计
label_opts=opts.LabelOpts(is_show=False),
type_=ChartType.LINES,
effect_opts=opts.EffectOpts(symbol_size=8, color="red"),
linestyle_opts=opts.LineStyleOpts(curve=0.3),
)
.set_global_opts(title_opts=opts.TitleOpts(title="动态轨迹图 author:张志豪 2024-4-8"))
)
# 保存为图片
geo.render("geo_dynamic_trajectory.png")1.2 绘制结果
二、使用seaborn绘制关系图
2.1 绘制散点图分析产品开发部已离职的员工的评分与平均工作时间
2.1.1 代码实现
from matplotlib import pyplot as plt
import pandas as pd
import seaborn as sns
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 使用seaborn库绘图
sns.set_style('whitegrid', {'font.sans-serif':['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 提取部门为产品开发部、离职为1的数据
product = hr.iloc[(hr['部门'].values == '产品开发部') & (hr['离职'].values == 1), :]
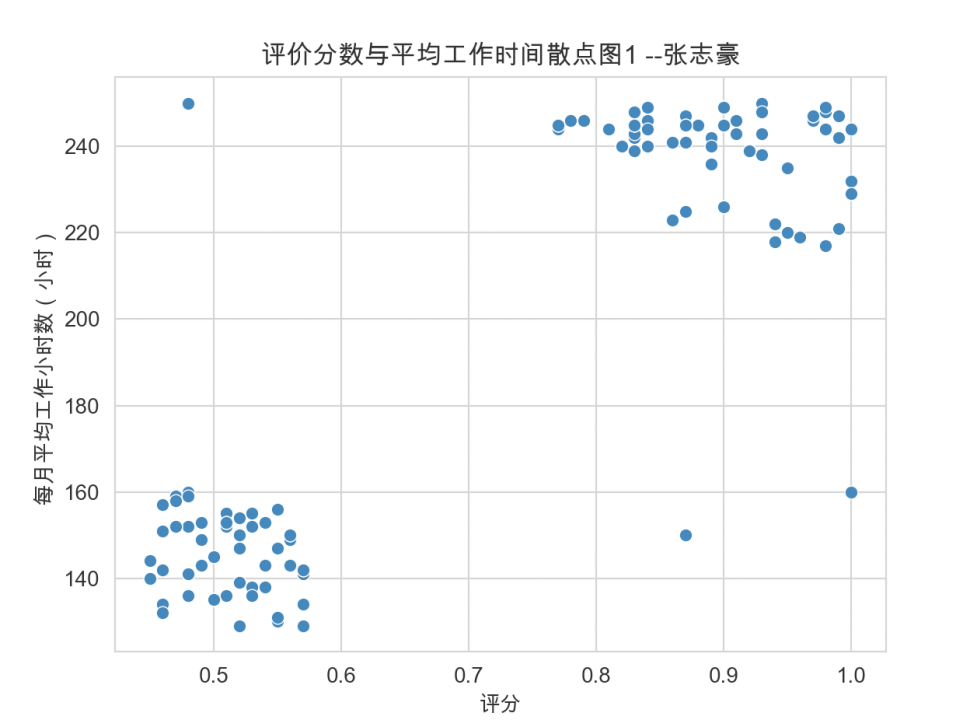
# 绘制评价分数与平均工作时间的散点图
ax = sns.scatterplot(x='评分', y='每月平均工作小时数(小时)', data=product)
# 设置图表标题
plt.title('评价分数与平均工作时间散点图1 --张志豪')
# 显示图表1
plt.show()
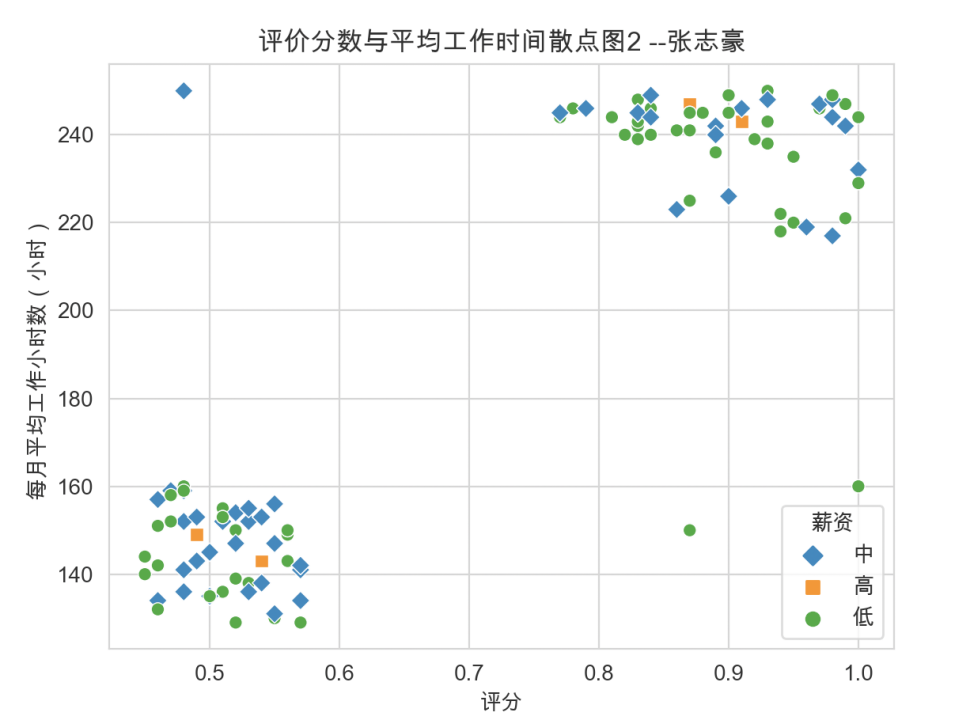
markers = {'低': 'o', '中': 'D', '高': 's'}
# 绘制评价分数与平均工作时间的散点图,并根据薪资水平使用不同的标记
sns.scatterplot(x='评分', y='每月平均工作小时数(小时)', hue='薪资', style='薪资', markers=markers, data=product)
# 设置图表标题
plt.title('评价分数与平均工作时间散点图2 --张志豪')
# 显示图表2
plt.show()2.1.2 绘制结果
注:散点图2是在散点图1的基础上添加了第三个分类变量,可以通过对点着色(故称色调语义)和改变标记来显示分类变量,以突显每个类别。
2.2 基于波士顿房价数据,绘制房间数和房屋价格的折线图
2.2.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
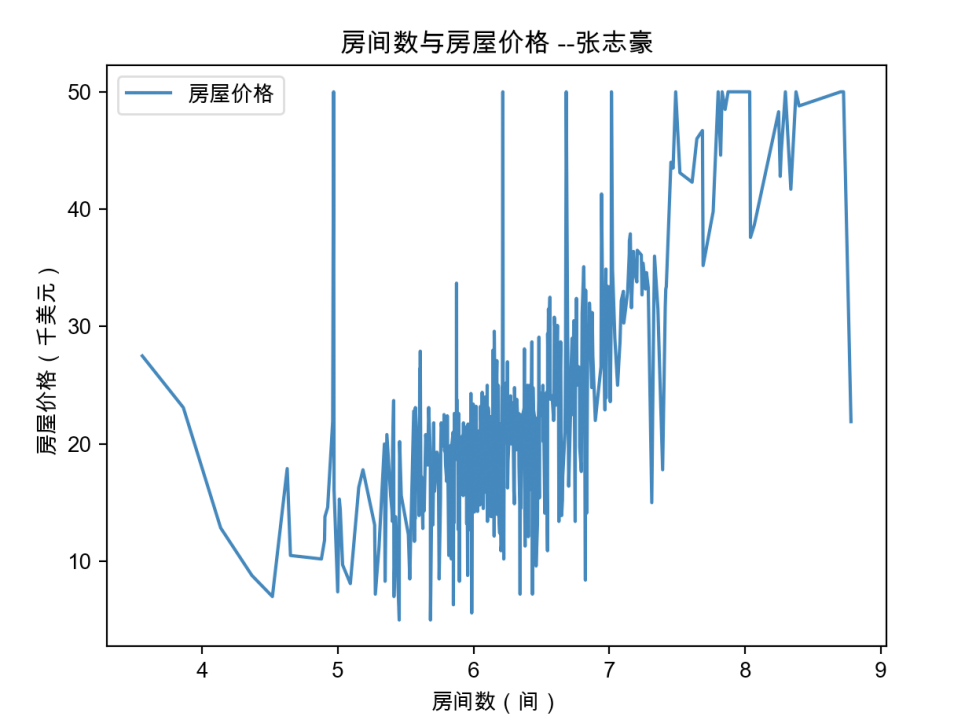
# 绘制折线图
sns.lineplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ci=0)
# 添加标题和坐标轴标签
plt.title('房间数与房屋价格')
plt.xlabel('房间数(间)')
plt.ylabel('房屋价格(千美元)')
# 显示图例
plt.legend(['房屋价格'], loc='upper left')
# 显示图形
plt.show()2.2.2 绘制结果
由下图可知,折线具有较大的波动性,但整体呈现向上的趋势,可以大致认为当房间数相对较少时,房屋价格也相对较低;当房间数相对较多时,房屋价格逐渐升高。
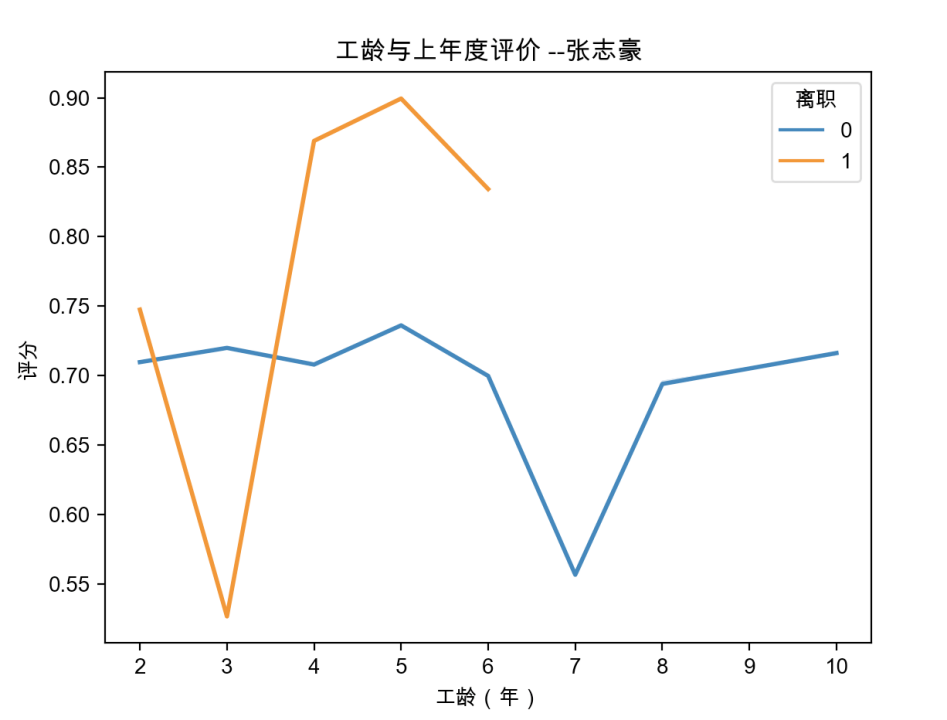
2.3 基于人员离职数据,绘制IT部部门员工工龄、年度评分折线图
2.3.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 提取IT部门的数据
IT = hr[hr['部门'] == 'IT部']
# 绘制折线图,修改线的颜色
sns.lineplot(x='工龄(年)', y='评分', hue='离职', data=IT, ci=0,
color=['red', 'blue'], linewidth=2)
# 添加标题和坐标轴标签
plt.title('工龄与上年度评价 --张志豪')
plt.xlabel('工龄(年)')
plt.ylabel('评分')
# 显示图例
plt.legend(title='离职', loc='upper right')
# 显示图形
plt.show()2.3.2 绘制结果
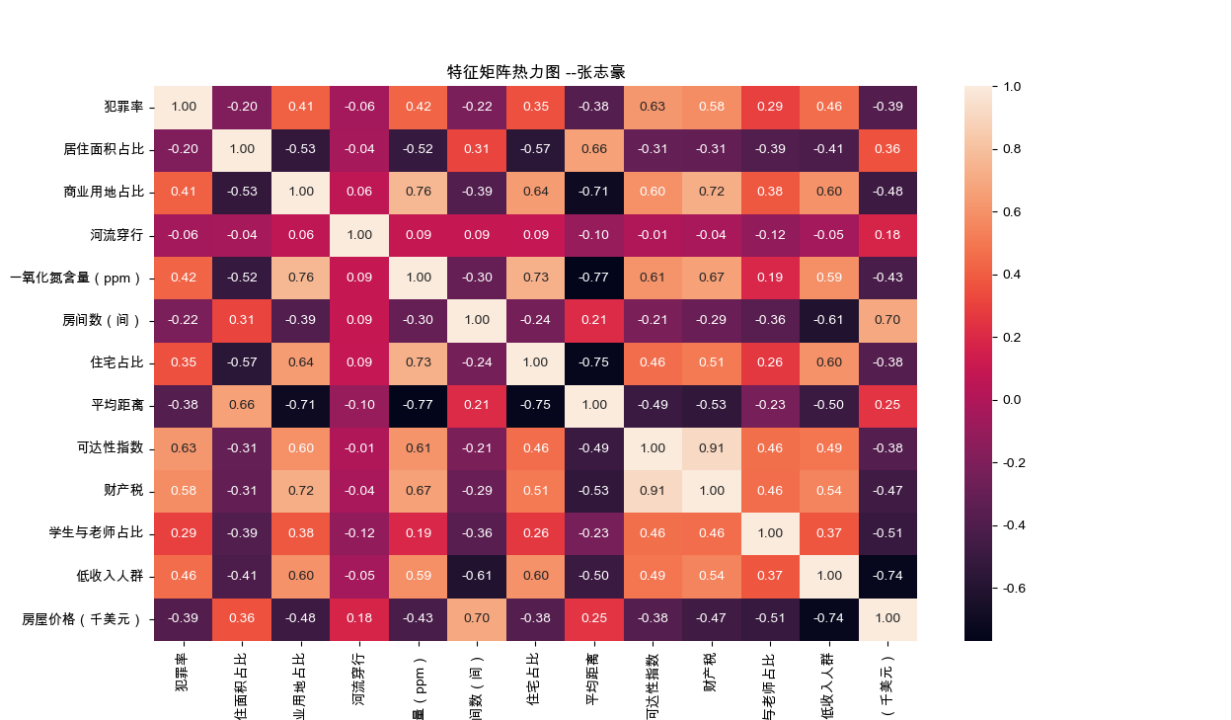
2.4 基于波士顿房价数据绘制热力图
2.4.1 代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 加载波士顿房价数据集
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 设置负号显示正常
plt.rcParams['axes.unicode_minus'] = False
# 计算特征相关系数矩阵
corr = boston.corr()
# 绘制热力图,添加数据标记
plt.figure(figsize=(4, 4)) # 设置合适的大小
sns.heatmap(corr, annot=True, fmt='.2f')
# 添加标题
plt.title('特征矩阵热力图 --张志豪')
# 显示图形
plt.show()2.4.2 绘制结果
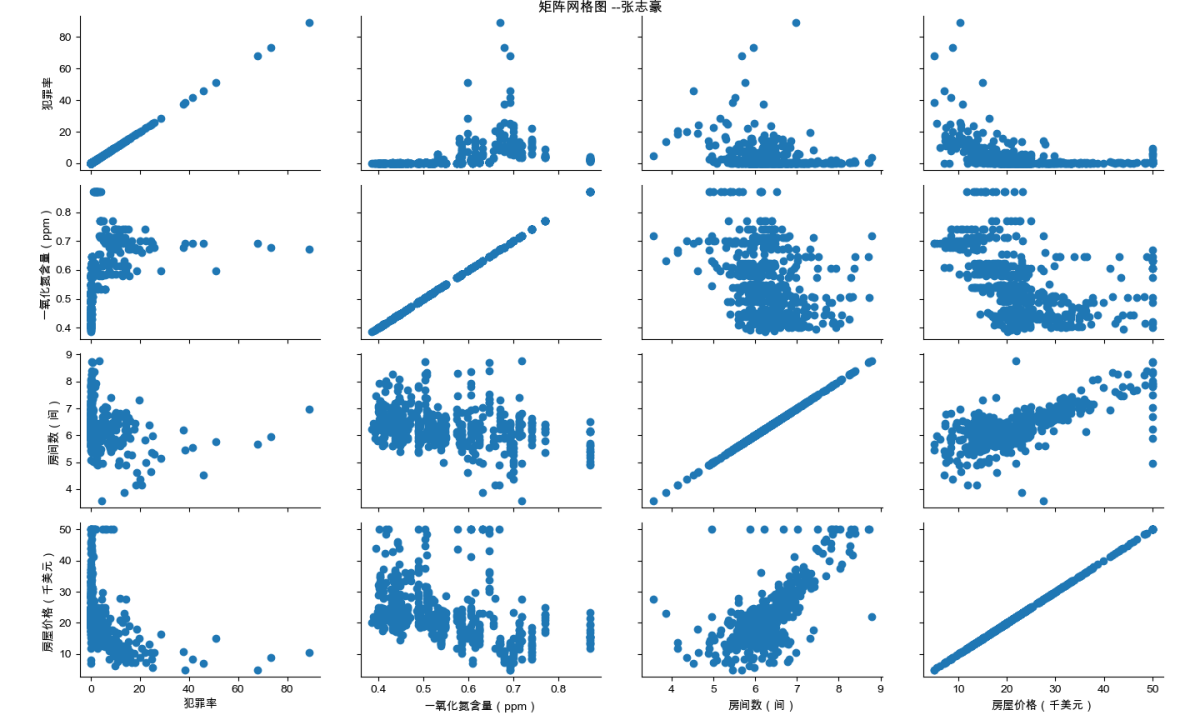
2.5 基于波士顿房价数据绘制犯罪率、一氧化氮含量、房间数与房屋价格两两之间的相关性
2.5.1 代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
# 绘制两两变量之间的相关性矩阵图
g = sns.PairGrid(boston, vars=['犯罪率', '一氧化氮含量(ppm)', '房间数(间)', '房屋价格(千美元)'])
g = g.map(plt.scatter)
# 添加总标题
plt.suptitle('矩阵网格图 --张志豪', verticalalignment='bottom', y=0.98)
# 显示图形
plt.show()2.5.2绘制结果
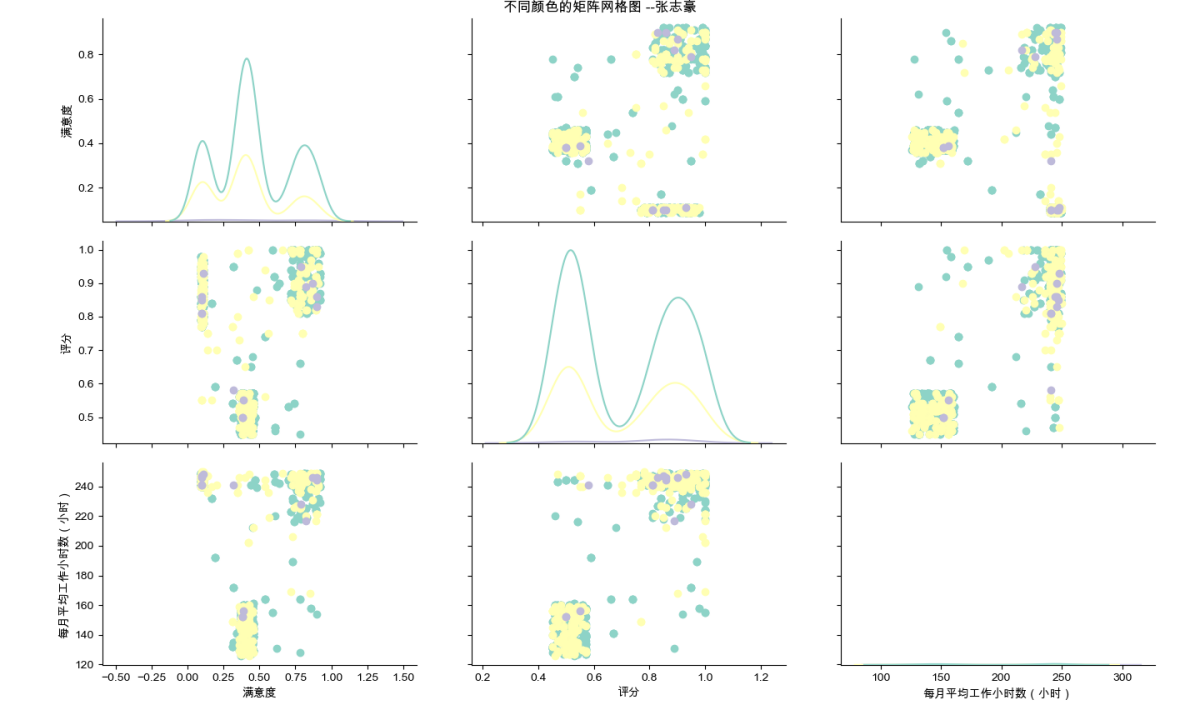
2.6 基于人员离职率数据,对销售部已离职的员工数据绘制不同颜色的数据子集
2.6.1 代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 提取部门为销售部,离职为1的数据
sell = hr.loc[(hr['部门'].values == '销售部') & (hr['离职'].values == 1), :]
# 设置图形大小
plt.figure(figsize=(10, 6))
# 绘制矩阵网格图
g = sns.PairGrid(sell,
vars=['满意度', '评分', '每月平均工作小时数(小时)'],
hue='薪资', palette='Set3')
g = g.map_diag(sns.kdeplot)
g = g.map_offdiag(plt.scatter)
# 添加总标题
plt.suptitle('不同颜色的矩阵网格图 --张志豪', verticalalignment='bottom', y=0.98)
# 显示图形
plt.show()2.6.2 绘制结果
2.7 根据销售部已离职的员工数据,通过relplot函数绘制单构面散点图
2.7.1 代码实现
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 提取部门为销售部,离职为1的数据
sell = hr.loc[(hr['部门'].values == '销售部') & (hr['离职'].values == 1), :]
# 绘制单构面散点图
sns.relplot(x='满意度', y='评分', hue='薪资', data=sell)
# 添加标题
plt.title('满意度水平与上年度评价',loc='center')
# 显示图形
plt.show()2.7.2 绘制结果
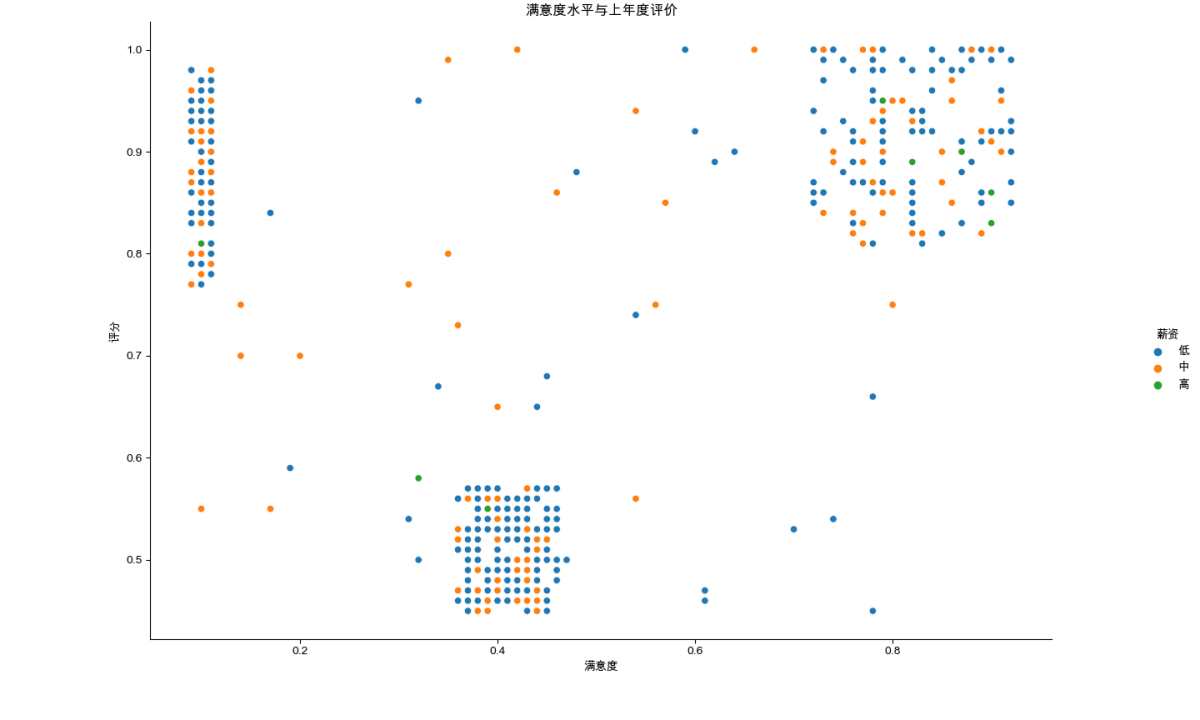
由图可知,在销售部部门且已经离职的员工中,人员评估分数越高,员工对公司的满意度越高。
2.8 根据部门为IT部的数据,传入分类变量薪资和工作事故到col和row中,绘制网格图
2.8.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 提取部门为IT部的数据
IT = hr[hr['部门'] == 'IT部']
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 绘制第一个网格图
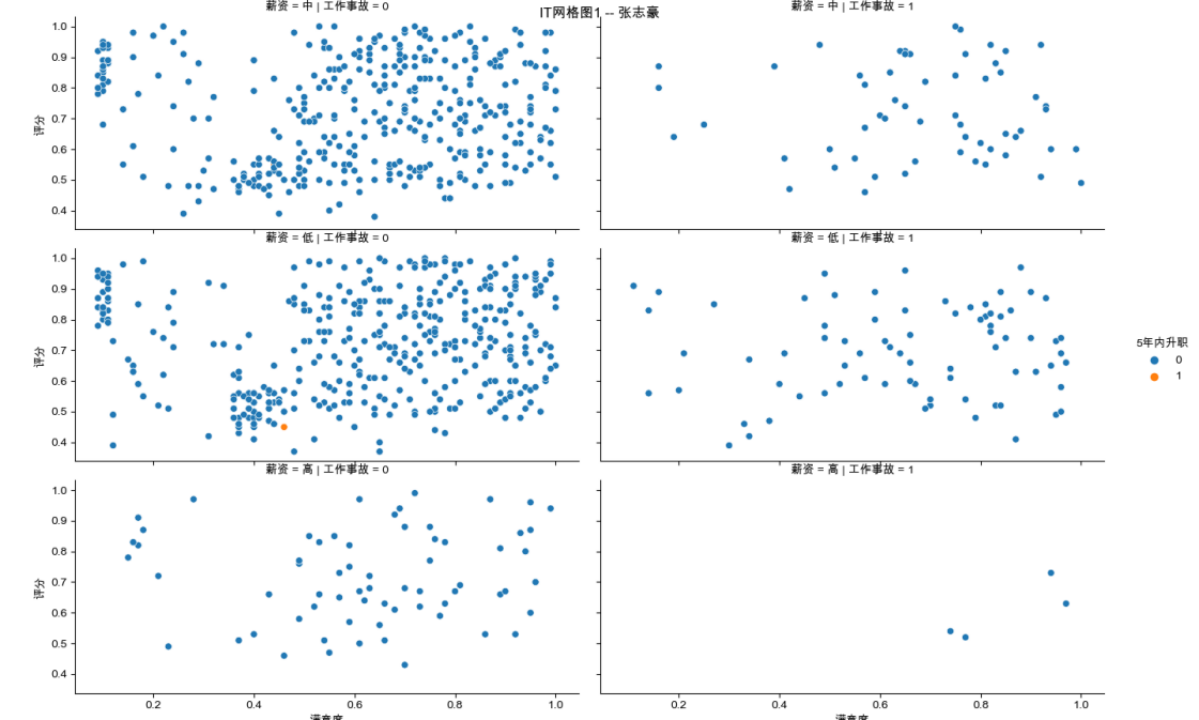
sns.relplot(x='满意度', y='评分', hue='5年内升职', row='薪资', col='工作事故', data=IT)
# 设置主标题
plt.suptitle('IT网格图1 -- 张志豪', y=0.99)
plt.show()
# 绘制第二个网格图
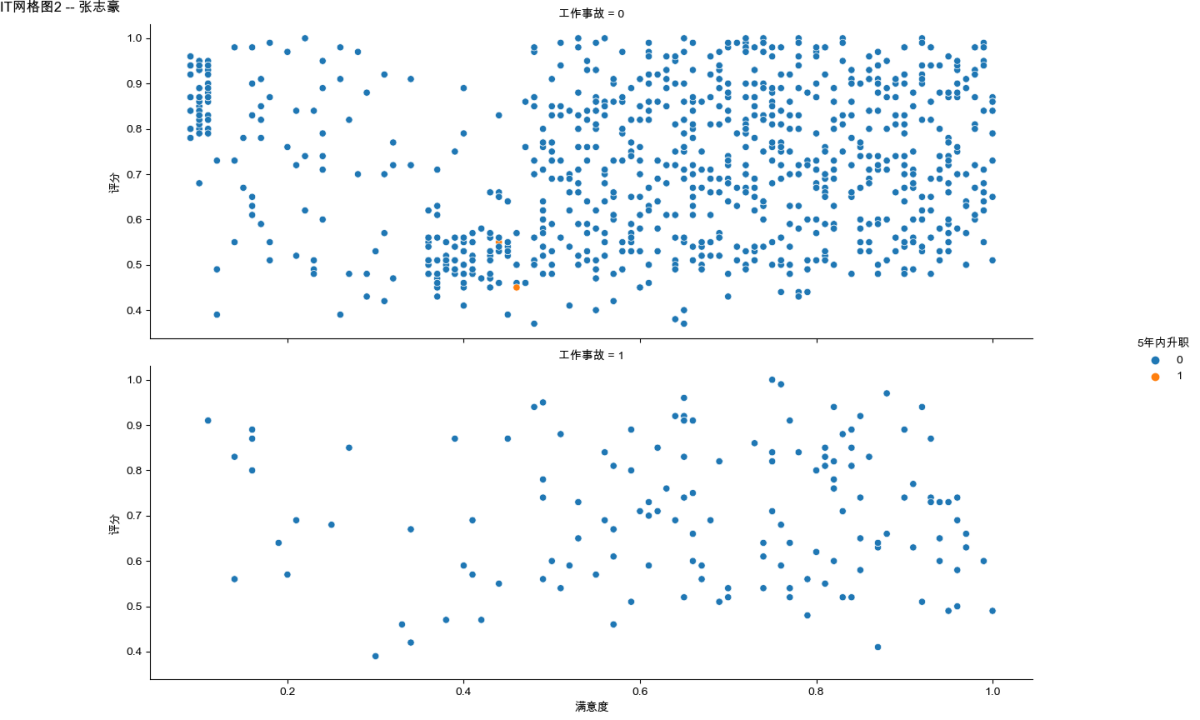
sns.relplot(x='满意度', y='评分', hue='5年内升职', col='工作事故', col_wrap=1, data=IT)
# 设置主标题
plt.suptitle('IT网格图2 -- 张志豪', horizontalalignment='left', verticalalignment='bottom', x=0, y=0.98)
# 显示图形
plt.show()
# 显示图形
plt.show()
plt.show()2.8.2 绘制结果
注:这两个图的title设置花了较多时间,包括一些参数的设置
三、使用seaborn绘制分类图
3.1基于离职率数据,使用barplot函数绘制各部门人员总数条形图
3.1.1 代码实现
from matplotlib import pyplot as plt
import pandas as pd
import seaborn as sns
import math
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
hr = pd.read_csv('hr.csv', encoding='gbk')
# 使用seaborn库绘图
sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 计算各部门的人数并获取部门名称
count = hr['部门'].value_counts()
index = count.index
# 绘制各部门人数的条形图
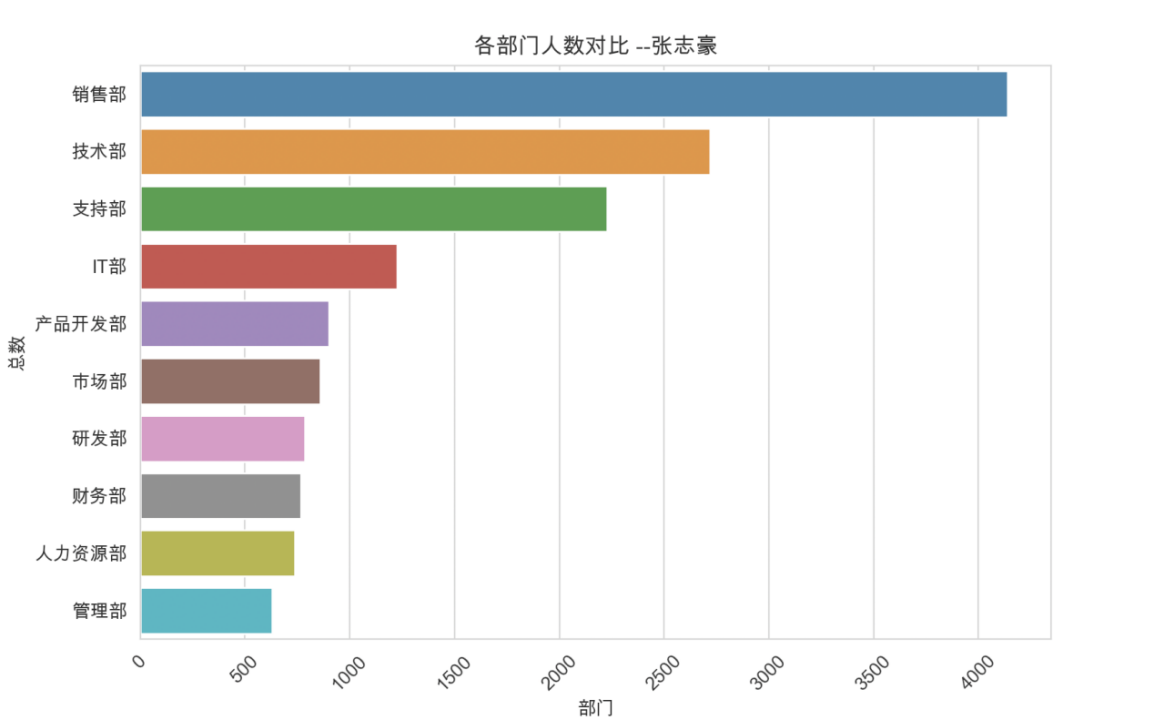
sns.barplot(x=count, y=index)
# 设置x轴标签旋转角度
plt.xticks(rotation=45)
# 设置x轴和y轴的标签
plt.xlabel('部门')
plt.ylabel('总数')
# 设置图表标题
plt.title('各部门人数对比')
# 显示图表
plt.show()3.1.2 绘制结果
3.2 基于人员离职率数据绘制x轴与y轴显示数据的计数图
3.2.1 代码实现
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 设置中文字体和绘图风格
sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'Arial']})
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 创建一个新的图形窗口,并设置大小为宽8英寸,高4英寸
plt.figure(figsize=(8, 4))
# 创建第一个子图(1行2列中的第1个)
plt.subplot(1, 2, 1) # 子图参数为(行数, 列数, 子图索引)
# 绘制工龄(年)的计数图,并设置x轴标签
sns.countplot(x=hr['工龄(年)']) # 使用列索引来引用数据
plt.title('x轴显示数据的计数图 --张志豪') # 设置子图标题
plt.ylabel('计数') # 设置y轴标签
# 创建第二个子图(1行2列中的第2个)
plt.subplot(1, 2, 2) # 子图参数为(行数, 列数, 子图索引)
# 绘制工龄(年)的计数图,并设置y轴标签
sns.countplot(y=hr['工龄(年)']) # 使用列索引来引用数据
plt.title('y轴显示数据的计数图 --张志豪') # 设置子图标题
plt.xlabel('计数') # 设置x轴标签
# 显示图表
plt.show()3.2.2 绘制结果
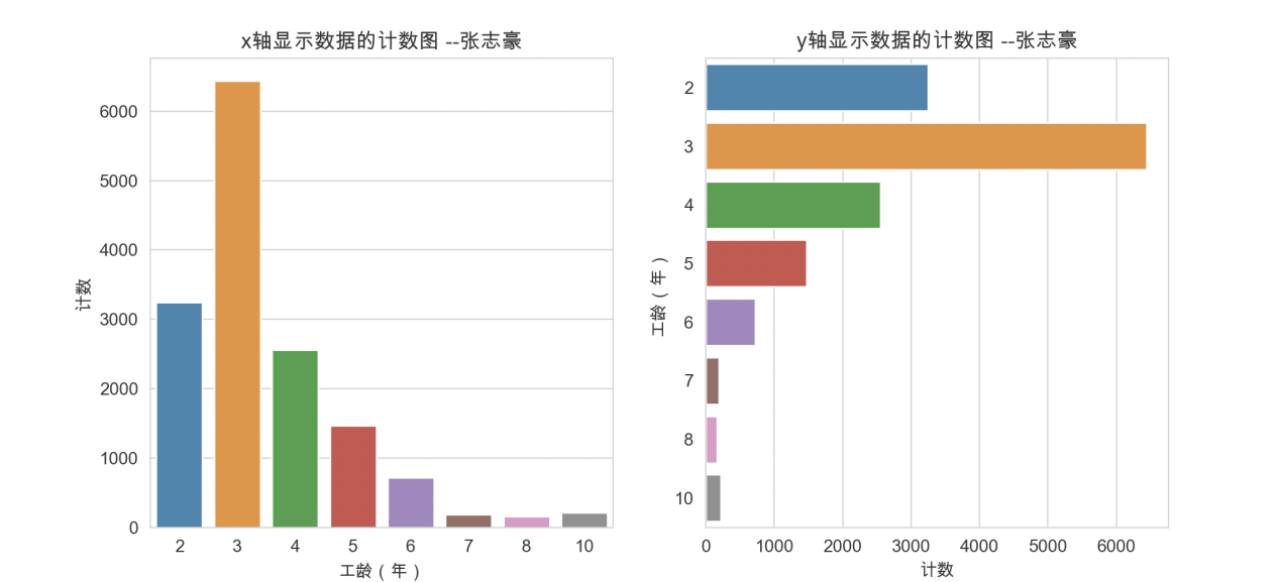
由图可知,不同工龄的员工数量,其中工龄为3的员工数量最多,其次是工龄为2和4的,工龄为7、8、10的员工数量都相对较少,说明了公司员工在工作到一定时间后有离职的情况。
3.3 基于波士顿房价数据绘制单变量分布图
3.3.1 代码实现
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
# 使用seaborn库绘制单变量的分布图
sns.distplot(boston['财产税'], kde=False)
# 设置图表标题
plt.title('单变量的分布图 --张志豪')
# 设置y轴标签
plt.ylabel('数量')
# 添加网格线
plt.grid(True)
# 显示图表
plt.show()3.3.2 绘制结果
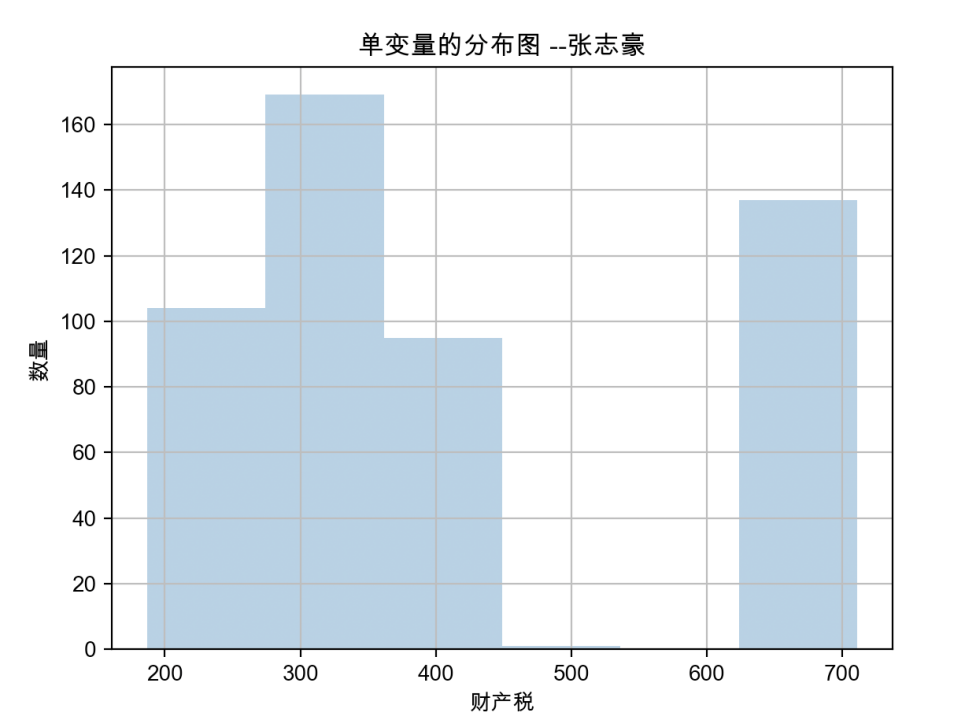
由图可知,每1万美元的全额物业税率,即财产税,主要集中在200~400和600~700区间,且在200~400区间的数量相关较大。
3.4 基于人员离职率数据,绘制简单水平分布散点图分析销售部已离职的员工每月平均工作小时
3.4.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 提取部门为销售部、离职为1的数据
sale = hr.iloc[(hr['部门'].values == '销售部') & (hr['离职'].values == 1), :]
# 使用seaborn库绘制简单水平分布散点图
sns.stripplot(x='每月平均工作小时数(小时)', data=sale)
# 设置图表标题
plt.title('简单水平分布散点图 --张志豪')
# 显示图表
plt.show()3.4.2 绘制结果
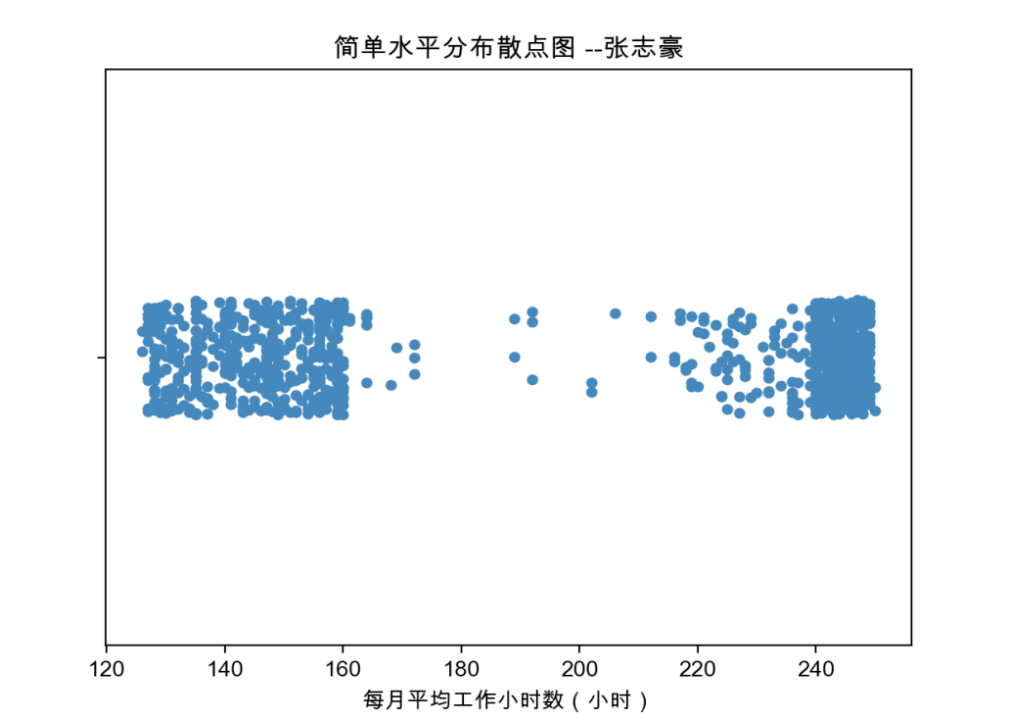
3.5 基于人员离职率数据,根据高薪在职的员工数据,使用swarmplot函数绘制简单的分布密度散点图
3.5.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 加载数据
hr = pd.read_csv('hr.csv', encoding='gbk')
# 创建一个新的图形窗口,并设置大小为宽10英寸,高13英寸
plt.figure(figsize=(10, 13))
# 创建第一个子图(2行1列中的第1个)
plt.subplot(2, 1, 1) # 子图参数为(行数, 列数, 子图索引)
# 设置x轴标签旋转角度
plt.xticks(rotation=70)
# 设置图表标题
plt.title('不同部门的平均每月工作时长 --张志豪')
# 使用seaborn库绘制带hue的简单水平分布散点图
sns.stripplot(x='部门', y='每月平均工作小时数(小时)', hue='5年内升职', data=hr)
# 创建第二个子图(2行1列中的第2个)
plt.subplot(2, 1, 2) # 子图参数为(行数, 列数, 子图索引)
# 设置x轴标签旋转角度
plt.xticks(rotation=70)
# 使用seaborn库绘制带hue和dodge的简单水平分布散点图
sns.stripplot(x='部门', y='每月平均工作小时数(小时)', hue='5年内升职', data=hr, dodge=True)
# 显示图表
plt.show()3.5.2 绘制结果
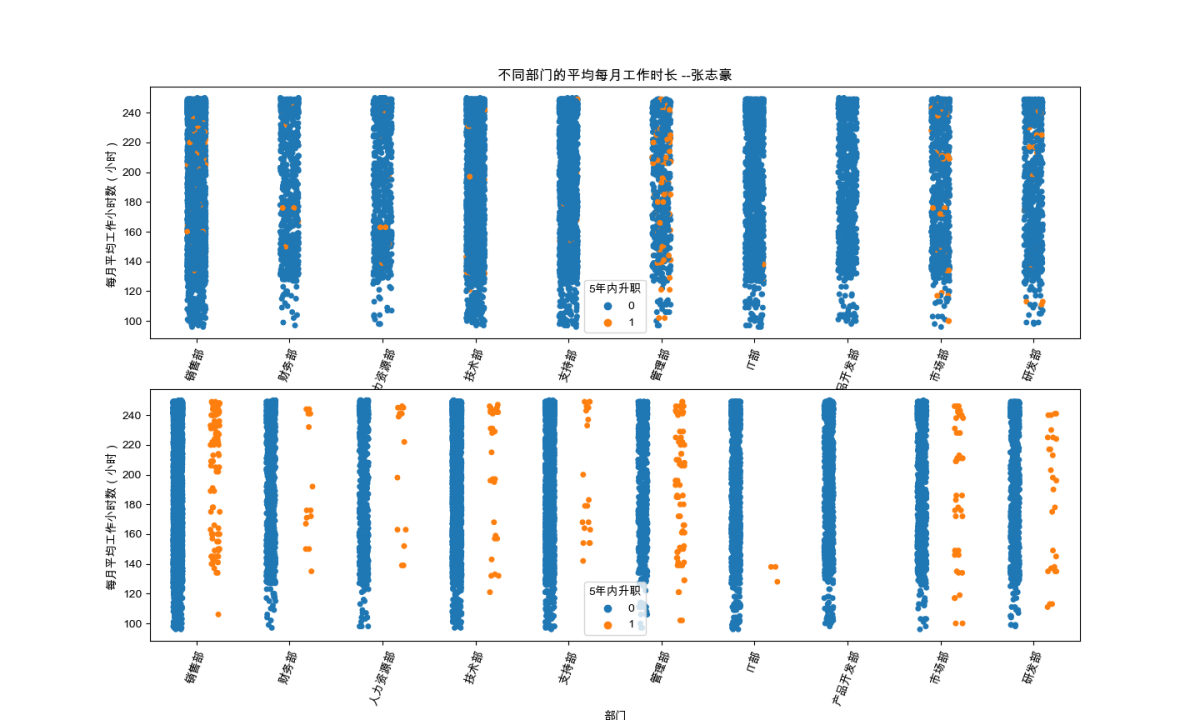
由图可知,在高薪在职的员工数据中,不同部门每个月平均工作时长和近五年是否得到提升。其中,销售部部门、管理部部门、市场部部门和财务部部门有少数员工提升,其他部门基本没有得到提升。
3.6 波士顿房价数据绘制普通箱线图与增强箱线图
3.6.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import math
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode MS']
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
# 对房间数取整
boston['房间数(取整)'] = boston['房间数(间)'].map(math.floor)
# 创建一个包含两个子图的图形窗口,设置大小为宽8英寸,高4英寸
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
# 第一个子图,绘制普通箱线图
axes[0].set_title('普通箱线图 --张志豪') # 设置子图标题
sns.boxplot(x='房间数(取整)', y='房屋价格(千美元)', data=boston, orient='v', ax=axes[0]) # 绘制箱线图
# 第二个子图,绘制增强箱线图
axes[1].set_title('增强箱线图 --张志豪') # 设置子图标题
sns.boxenplot(x='房间数(取整)', y='房屋价格(千美元)', data=boston, orient='v', ax=axes[1]) # 绘制增强箱线图
# 显示图表
plt.show()3.6.2 绘制结果
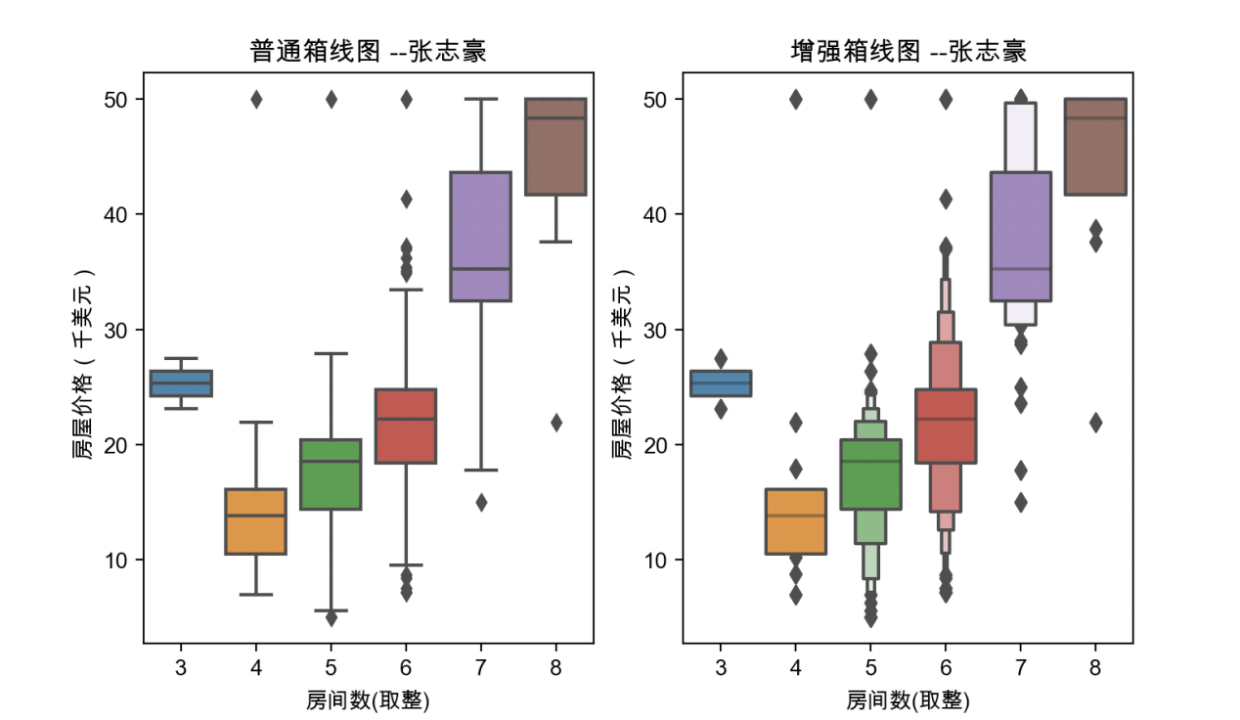
由图可知,房间数目与房价有密切关系,房间数目少,房价低;房间数目多,则房价就明显升高。增强箱线图显示更广的分位数,并通过宽度展示出对应的分布,从而接纳了更多的异常值信息,减少了信息损失。
3.7 基于波士顿房价数据,通过pairplot函数绘制多变量之间的关系图
3.7.1 代码实现
1.import seaborn as sns
2.import matplotlib.pyplot as plt
3.import pandas as pd
4.
5.# 设置中文字体
6.plt.rcParams['font.family'] = ['Arial Unicode Ms']
7.
8.# 加载数据
9.boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
10.
11.# 使用seaborn库绘制多变量散点图
12.sns.pairplot(boston[['犯罪率', '一氧化氮含量(ppm)', '房间数(间)', '低收入人群', '房屋价格(千美元)']])
13.
14.# 设置图表标题
15.plt.suptitle('多变量散点图 --张志豪', verticalalignment='bottom', y=0.98)
16.
17.# 显示图表
18.plt.show()3.7.2 绘制结果
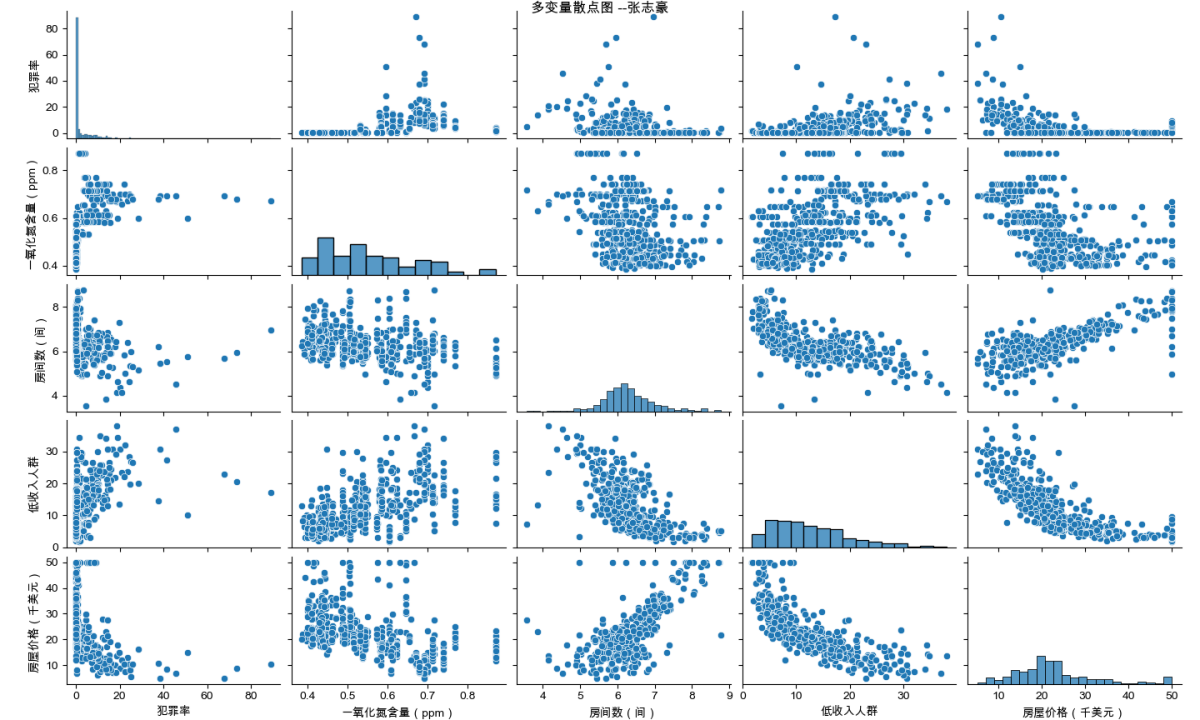
由图可知,犯罪率、一氧化氮含量、房间数、低收入人群、房屋价格几个字段的两两之间的相关关系,以及在对角线上显示了犯罪率、一氧化氮含量、房间数、低收入人群、房屋价格的分布情况。
四、使用seaborn绘制回归图
4.1 基于波士顿房价数据,利用regplot函数绘制修改置信区间ci参数前后的线性回归拟合图
4.1.1 代码实现
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
import warnings
# 设置中文字体
sns.set_style('whitegrid', {'font.sans-serif': ['SimHei', 'Arial']})
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 忽略警告
warnings.filterwarnings('ignore')
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# 设置主标题
plt.suptitle('线性拟合图 -张志豪', y=0.99)
axes[0].set_title('修改前的线性回归拟合图')
axes[1].set_title('修改后的线性回归拟合图')
sns.regplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ax=axes[0])
sns.regplot(x='房间数(间)', y='房屋价格(千美元)', data=boston, ci=50, ax=axes[1])
plt.show()
4.1.2 绘制结果
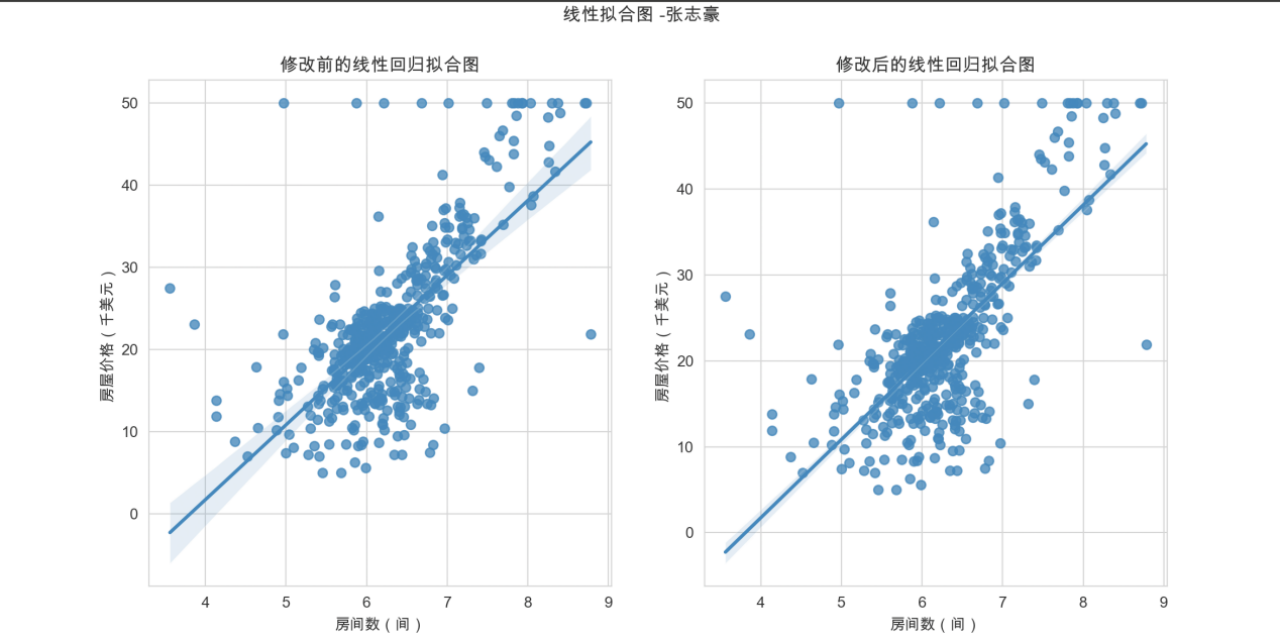
由图可知,房间数和房屋价格成线性相关关系。其中,修改置信区间ci参数前后得到的线性回归拟合图一致,准确度也不相同。
4.2 基于波士顿房价数据,以河流穿行为类别绘制低收入人群与房屋价格两个变量的回归网格组合图
4.2.1 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
boston = pd.read_csv('boston_house_prices.csv', encoding='gbk')
# 设置中文字体
plt.rcParams['font.family'] = ['Arial Unicode Ms']
# 绘制回归网格组合图
sns.lmplot(x='低收入人群', y='房屋价格(千美元)', hue='河流穿行', data=boston, aspect=1.5)
plt.title('低收入人群与房屋价格回归网格组合图 --张志豪')
plt.xlabel('低收入人群')
plt.ylabel('房屋价格(千美元)')
plt.show()4.2.2 绘制结果
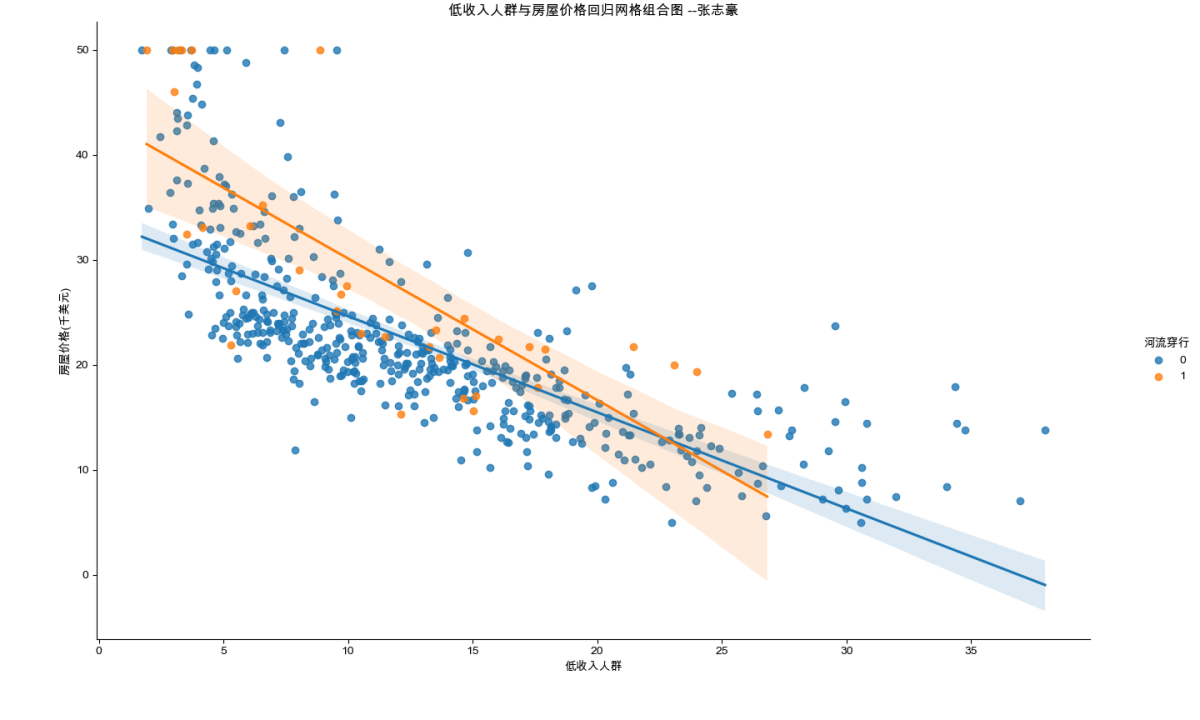
由图可知,无论是否被河流穿过,变量低收入人群与变量房屋价格呈现较密切的线性拟合趋势,且绝大部分都是分布在未被河流穿过的情况下。
end~



















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











