









纯点云kitti格式数据集制作,参考官网的格式
kitti数据集官网:https://www.cvlibs.net/datasets/kitti/
kitti格式内容如下:(由于是纯点云的数据集,所有有关图像的部分我都设置的默认值,截断程度、遮挡率这些也都设置的0)

数据文件结构如下
my_kitti
├── ImageSets
│ ├── val.txt
│ ├── train.txt
├── testing
│ ├── label_2
│ ├── velodyne
├── training
│ ├── label_2
│ ├── velodyne
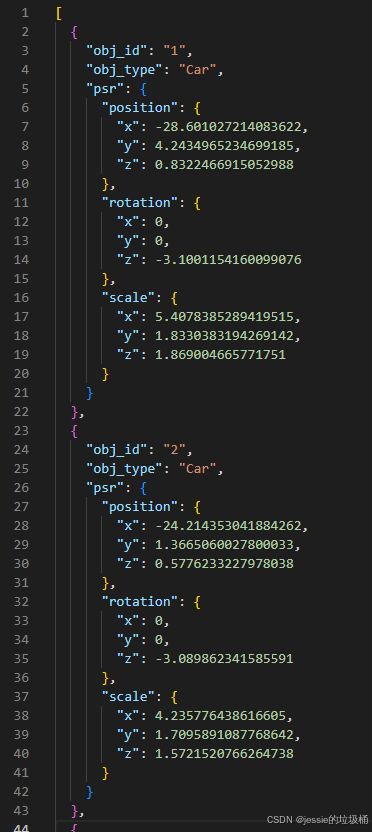
数据标注是通过SUSTechPOINTS进行的,关于如何使用SUSTechPOINTS进行标注,请参考我的另一篇文章https://blog.csdn.net/m0_64293675/article/details/144189633?spm=1001.2014.3001.5502。生成的json标注文件部分内容如下:
制作数据集的python脚本如下:
import os
import numpy as np
import json
import shutil
import random
from tqdm import tqdm
import open3d as o3d
namesclass={
'Car': 'Car',
'Pedestrian': 'Pedestrian',
'Bicycle': 'Cyclist',
'ScooterRider':'Cyclist',
'Truck':'Car',
'Motorcycle':'Cyclist',
'Van':'Car',
'Bus':'Car',
'TourCar':'Car',
'Scooter':'Cyclist',
'Cyclist':'Cyclist'
}
def pcd2bin(pcdfolder, binfolder):
current_path = os.getcwd()
ori_path = os.path.join(current_path, pcdfolder)
file_list = os.listdir(ori_path)
des_path = os.path.join(current_path, binfolder)
os.makedirs(des_path, exist_ok=True)
for file in tqdm(file_list):
(filename,extension) = os.path.splitext(file)
velodyne_file = os.path.join(ori_path, filename) + '.pcd'
pcd = o3d.io.read_point_cloud(velodyne_file)
# 获取点云数据的NumPy数组
points = np.asarray(pcd.points)
# 反射强度默认设置成0,训练中基本也不会用到
intensities = np.zeros(points.shape[0])
# intensities = np.asarray(pcd.colors)[:, 0] if pcd.has_colors() else np.zeros(points.shape[0])
# 合并点云坐标和强度信息到一个数组中
point_cloud_data = np.column_stack((points, intensities))
# print("points shape: ",point_cloud_data.shape)
point_cloud_data = point_cloud_data.astype(np.float32)
velodyne_file_new = os.path.join(des_path, filename) + '.bin'
point_cloud_data.tofile(velodyne_file_new)
def json2txt(json_paths,txt_paths):
json_path_list = os.listdir(json_paths)
os.makedirs(json_paths, exist_ok=True)
os.makedirs(txt_paths, exist_ok=True)
for json_path in json_path_list:
# print(json_path)
(filename,extension) = os.path.splitext(json_path)
json_path_new = json_paths + "/" +json_path
txt_file_new = os.path.join(txt_paths, filename) + '.txt'
print(txt_file_new)
with open(json_path_new,'r',encoding='utf8')as fp:
json_data = json.load(fp)
for i in range(len(json_data)):
obj_id = json_data[i]["obj_id"]
obj_type = json_data[i]["obj_type"]
obj_type_final = namesclass[obj_type]
position_x = json_data[i]["psr"]["position"]["x"]
position_y = json_data[i]["psr"]["position"]["y"]
position_z = json_data[i]["psr"]["position"]["z"]
# scale_x y z 分别表示长宽高
# 数据集要求依次输入高宽长
scale_x = json_data[i]["psr"]["scale"]["x"]
scale_y = json_data[i]["psr"]["scale"]["y"]
scale_z = json_data[i]["psr"]["scale"]["z"]
# 标注文件中偶尔会有长宽高为负数的情况,需要取绝对值
if scale_x<0 or scale_y<0 or scale_z<0:
scale_x = abs(scale_x)
scale_y = abs(scale_y)
scale_z = abs(scale_z)
# sustechoint软件标注的坐标是3D-BOX的中心坐标,kitti数据集的格式要求的是底面中心坐标
position_z_new = position_z - 0.5*scale_z
rotation_x = json_data[i]["psr"]["rotation"]["x"]
rotation_y = json_data[i]["psr"]["rotation"]["y"]
rotation_z = json_data[i]["psr"]["rotation"]["z"]
line = obj_type_final + " " + "0"+ " " + "0" + " " + "0" + " " "100" +" " +"100"+ " " +"200"+" " +"200" +" " + str(scale_z) + " " + str(scale_y) + " " + str(scale_x) +" " + str(position_x) + " " + str(position_y) + " " + str(position_z_new) + " " + str(rotation_z) +"\n"
with open(txt_file_new,"a") as f:
f.write(line)
def gen_kitti_data(SrcbinPath,SrctxtPath,kitti_data_path,test_ratio):
files = os.listdir(SrctxtPath)
# print(files)
# 随机打乱文件顺序
random.shuffle(files)
# 计算划分数据集的索引
total_files = len(files)
train_split = int((1-test_ratio) * total_files)
val_split = int(test_ratio * total_files)
for file in tqdm(files[:train_split], desc=f'Copying train data'):
# 复制bin
src_bin = os.path.join(SrcbinPath, file[:-4] + '.bin')
dst_bin = os.path.join(kitti_data_path, 'training','velodyne')
# 复制txt和bin
src_txt = os.path.join(SrctxtPath, file)
dst_txt = os.path.join(kitti_data_path, 'training','label_2')
os.makedirs(dst_bin, exist_ok=True)
shutil.copy(src_bin, os.path.join(dst_bin, file[:-4] + '.bin'))
os.makedirs(dst_txt, exist_ok=True)
shutil.copy(src_txt, os.path.join(dst_txt, file))
os.makedirs(kitti_data_path + "/ImageSets", exist_ok=True)
train_path = kitti_data_path + "/ImageSets" + "/train.txt"
file_list = os.listdir(dst_bin)
data = []
for file in file_list:
(filename,extension) = os.path.splitext(file)
data.append(filename)
for i in data:
with open(train_path,"a") as f:
f.write(str(i) + "\n")
for file in tqdm(files[train_split:train_split + val_split], desc=f'Copying validation data'):
# 复制bin
src_bin = os.path.join(SrcbinPath, file[:-4] + '.bin')
dst_bin = os.path.join(kitti_data_path, 'testing','velodyne')
os.makedirs(dst_bin, exist_ok=True)
shutil.copy(src_bin, os.path.join(dst_bin, file[:-4] + '.bin'))
# 同时复制txt
src_txt = os.path.join(SrctxtPath, file)
dst_txt = os.path.join(kitti_data_path, 'testing','label_2')
os.makedirs(dst_txt, exist_ok=True)
shutil.copy(src_txt, os.path.join(dst_txt, file))
os.makedirs(kitti_data_path + "/ImageSets", exist_ok=True)
train_path = kitti_data_path + "/ImageSets" + "/val.txt"
file_list = os.listdir(dst_bin)
data = []
for file in file_list:
(filename,extension) = os.path.splitext(file)
data.append(filename)
for i in data:
with open(train_path,"a") as f:
f.write(str(i) + "\n")
print("数据集划分完成!")
# 1、pcd转bin
pcd2bin("lidar","velodyne")
# 2、json格式的标注文件转txt
json2txt("label_json","label_txt")
# 3、生成数据集
gen_kitti_data("velodyne","label_txt","kitti_dataset",0.1)


















 3420
3420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









