







OpenPcedt下实现自定义纯点云kitti格式数据集的训练—centerpoint
本文的训练过程参考以下两篇文章,感谢这两位作者!
- https://blog.csdn.net/Shawn_1223/article/details/129883355?spm=1001.2014.3001.5506
- https://blog.csdn.net/weixin_53776054/article/details/130050400?spm=1001.2014.3001.5506
自定义纯点云kitti格式数据集的制作参考我的这篇文章:
https://blog.csdn.net/m0_64293675/article/details/144188916?spm=1001.2014.3001.5501
OpenPcdet源码的拉取和安装参考我的这篇文章:
https://blog.csdn.net/m0_64293675/article/details/144192805?spm=1001.2014.3001.5501
OpenPcdet源码下的tools/cfgs/kitti_models里没有centerpoint.yaml,于是我从tools/cfgs/waymo_models里复制了一份过来,放心,一样能用。
由于是纯点云的训练,源码中涉及到图像相关的部分都需要处理,以下是需要修改的部分:
- pcdet/datasets/kitti/kitti_dataset.py
1、KittiDataset类中的get_calib函数
# def get_calib(self, idx):
def get_calib(self, loc):
# old
# calib_file = self.root_split_path / 'calib' / ('%s.txt' % idx)
# assert calib_file.exists()
# return calibration_kitti.Calibration(calib_file)
# new
loc_lidar = np.concatenate([np.array((float(loc_obj[0]),float(loc_obj[1]),float(loc_obj[2])),dtype=np.float32).reshape(1,3) for loc_obj in loc])
return loc_lidar
2、KittiDataset类中get_infos函数中的process_single_scene函数
def process_single_scene(sample_idx):
print('%s sample_idx: %s' % (self.split, sample_idx))
info = {}
pc_info = {'num_features': 4, 'lidar_idx': sample_idx}
info['point_cloud'] = pc_info
# # image信息和calib信息都不需要
# image_info = {'image_idx': sample_idx, 'image_shape': self.get_image_shape(sample_idx)}
# info['image'] = image_info
# calib = self.get_calib(sample_idx)
# P2 = np.concatenate([calib.P2, np.array([[0., 0., 0., 1.]])], axis=0)
# R0_4x4 = np.zeros([4, 4], dtype=calib.R0.dtype)
# R0_4x4[3, 3] = 1.
# R0_4x4[:3, :3] = calib.R0
# V2C_4x4 = np.concatenate([calib.V2C, np.array([[0., 0., 0., 1.]])], axis=0)
# calib_info = {'P2': P2, 'R0_rect': R0_4x4, 'Tr_velo_to_cam': V2C_4x4}
# info['calib'] = calib_info
if has_label:
obj_list = self.get_label(sample_idx)
annotations = {}
annotations['name'] = np.array([obj.cls_type for obj in obj_list])
# annotations['truncated'] = np.array([obj.truncation for obj in obj_list])
# annotations['occluded'] = np.array([obj.occlusion for obj in obj_list])
# annotations['alpha'] = np.array([obj.alpha for obj in obj_list])
# annotations['bbox'] = np.concatenate([obj.box2d.reshape(1, 4) for obj in obj_list], axis=0)
annotations['dimensions'] = np.array([[obj.l, obj.w, obj.h] for obj in obj_list]) # lhw(camera) format
annotations['location'] = np.concatenate([obj.loc.reshape(1, 3) for obj in obj_list], axis=0)
annotations['rotation_y'] = np.array([obj.ry for obj in obj_list])
annotations['score'] = np.array([obj.score for obj in obj_list])
# annotations['difficulty'] = np.array([obj.level for obj in obj_list], np.int32)
num_objects = len([obj.cls_type for obj in obj_list if obj.cls_type != 'DontCare'])
num_gt = len(annotations['name'])
index = list(range(num_objects)) + [-1] * (num_gt - num_objects)
annotations['index'] = np.array(index, dtype=np.int32)
loc = annotations['location'][:num_objects]
# 这里dims是 l、w、h
dims = annotations['dimensions'][:num_objects]
rots = annotations['rotation_y'][:num_objects]
# 无需坐标转换
# loc_lidar = calib.rect_to_lidar(loc)
loc_lidar = self.get_calib(loc)
l, w, h = dims[:, 0:1], dims[:, 1:2], dims[:, 2:3]
# 默认标注数据是底部的中心坐标,需要变成box中心坐标
# 如果标注的是中心坐标,这里不用做任何改变
# loc_lidar[:, 2] += h[:, 0] / 2
# gt_boxes_lidar = np.concatenate([loc_lidar, l, w, h, -(np.pi / 2 + rots[..., np.newaxis])], axis=1)
gt_boxes_lidar = np.concatenate([loc_lidar, l, w, h, rots[..., np.newaxis]], axis=1)
annotations['gt_boxes_lidar'] = gt_boxes_lidar
info['annos'] = annotations
# 后续没有calib信息和image信息,直接注释
if count_inside_pts:
points = self.get_lidar(sample_idx)
# calib = self.get_calib(sample_idx)
# pts_rect = calib.lidar_to_rect(points[:, 0:3])
# fov_flag = self.get_fov_flag(pts_rect, info['image']['image_shape'], calib)
# pts_fov = points[fov_flag]
corners_lidar = box_utils.boxes_to_corners_3d(gt_boxes_lidar)
num_points_in_gt = -np.ones(num_gt, dtype=np.int32)
for k in range(num_objects):
# flag = box_utils.in_hull(pts_fov[:, 0:3], corners_lidar[k])
flag = box_utils.in_hull(points[:, 0:3], corners_lidar[k])
num_points_in_gt[k] = flag.sum()
annotations['num_points_in_gt'] = num_points_in_gt
return info
3、KittiDataset类中的create_groundtruth_database函数
def create_groundtruth_database(self, info_path=None, used_classes=None, split='train'):
import torch
database_save_path = Path(self.root_path) / ('gt_database' if split == 'train' else ('gt_database_%s' % split))
db_info_save_path = Path(self.root_path) / ('kitti_dbinfos_%s.pkl' % split)
database_save_path.mkdir(parents=True, exist_ok=True)
all_db_infos = {}
with open(info_path, 'rb') as f:
infos = pickle.load(f)
for k in range(len(infos)):
print('gt_database sample: %d/%d' % (k + 1, len(infos)))
info = infos[k]
sample_idx = info['point_cloud']['lidar_idx']
points = self.get_lidar(sample_idx)
annos = info['annos']
names = annos['name']
# 不需要
# difficulty = annos['difficulty']
# bbox = annos['bbox']
gt_boxes = annos['gt_boxes_lidar']
num_obj = gt_boxes.shape[0]
point_indices = roiaware_pool3d_utils.points_in_boxes_cpu(
torch.from_numpy(points[:, 0:3]), torch.from_numpy(gt_boxes)
).numpy() # (nboxes, npoints)
for i in range(num_obj):
filename = '%s_%s_%d.bin' % (sample_idx, names[i], i)
filepath = database_save_path / filename
gt_points = points[point_indices[i] > 0]
gt_points[:, :3] -= gt_boxes[i, :3]
with open(filepath, 'w') as f:
gt_points.tofile(f)
if (used_classes is None) or names[i] in used_classes:
db_path = str(filepath.relative_to(self.root_path)) # gt_database/xxxxx.bin
# 修改db_info的内容
# db_info = {'name': names[i], 'path': db_path, 'image_idx': sample_idx, 'gt_idx': i,
# 'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0],
# 'difficulty': difficulty[i], 'bbox': bbox[i], 'score': annos['score'][i]}
db_info = {'name': names[i], 'path': db_path, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0], 'score': annos['score'][i]}
if names[i] in all_db_infos:
all_db_infos[names[i]].append(db_info)
else:
all_db_infos[names[i]] = [db_info]
for k, v in all_db_infos.items():
print('Database %s: %d' % (k, len(v)))
with open(db_info_save_path, 'wb') as f:
pickle.dump(all_db_infos, f)
4、generate_single_sample_dict函数
def generate_single_sample_dict(batch_index, box_dict):
pred_scores = box_dict['pred_scores'].cpu().numpy()
pred_boxes = box_dict['pred_boxes'].cpu().numpy()
pred_labels = box_dict['pred_labels'].cpu().numpy()
pred_dict = get_template_prediction(pred_scores.shape[0])
if pred_scores.shape[0] == 0:
return pred_dict
# 无情注释
# calib = batch_dict['calib'][batch_index]
# image_shape = batch_dict['image_shape'][batch_index].cpu().numpy()
# pred_boxes_camera = box_utils.boxes3d_lidar_to_kitti_camera(pred_boxes, calib)
# pred_boxes_img = box_utils.boxes3d_kitti_camera_to_imageboxes(
# pred_boxes_camera, calib, image_shape=image_shape
# )
# pred_dict['alpha'] = -np.arctan2(-pred_boxes[:, 1], pred_boxes[:, 0]) + pred_boxes_camera[:, 6]
# pred_dict['bbox'] = pred_boxes_img
# pred_dict['dimensions'] = pred_boxes_camera[:, 3:6]
# pred_dict['location'] = pred_boxes_camera[:, 0:3]
# pred_dict['rotation_y'] = pred_boxes_camera[:, 6]
# 修改
pred_dict['name'] = np.array(class_names)[pred_labels - 1]
pred_dict['alpha'] = -np.arctan2(-pred_boxes[:, 1], pred_boxes[:, 0])
pred_dict['bbox'] = pred_boxes
pred_dict['dimensions'] = pred_boxes[:, 3:6]
pred_dict['location'] = pred_boxes[:, 0:3]
pred_dict['rotation_y'] = pred_boxes[:, 6]
pred_dict['score'] = pred_scores
pred_dict['boxes_lidar'] = pred_boxes
return pred_dict
annos = []
for index, box_dict in enumerate(pred_dicts):
frame_id = batch_dict['frame_id'][index]
single_pred_dict = generate_single_sample_dict(index, box_dict)
single_pred_dict['frame_id'] = frame_id
annos.append(single_pred_dict)
if output_path is not None:
cur_det_file = output_path / ('%s.txt' % frame_id)
with open(cur_det_file, 'w') as f:
bbox = single_pred_dict['bbox']
loc = single_pred_dict['location']
dims = single_pred_dict['dimensions'] # lhw -> hwl
for idx in range(len(bbox)):
print('%s -1 -1 %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f'
% (single_pred_dict['name'][idx], single_pred_dict['alpha'][idx],
bbox[idx][0], bbox[idx][1], bbox[idx][2], bbox[idx][3],
dims[idx][1], dims[idx][2], dims[idx][0], loc[idx][0],
loc[idx][1], loc[idx][2], single_pred_dict['rotation_y'][idx],
single_pred_dict['score'][idx]), file=f)
return annos
5、__getitem__函数
def __getitem__(self, index):
# index = 4
if self._merge_all_iters_to_one_epoch:
index = index % len(self.kitti_infos)
info = copy.deepcopy(self.kitti_infos[index])
sample_idx = info['point_cloud']['lidar_idx']
# 继续注释
# img_shape = info['image']['image_shape']
# calib = self.get_calib(sample_idx)
# obj_list = self.get_label(sample_idx)
# annotations = {}
# annotations['location'] = np.concatenate([obj.loc.reshape(1, 3) for obj in obj_list], axis=0)
# num_objects = len([obj.cls_type for obj in obj_list if obj.cls_type != 'DontCare'])
# loc_ = annotations['location'][:num_objects]
# calib = self.get_calib(loc_)
get_item_list = self.dataset_cfg.get('GET_ITEM_LIST', ['points'])
input_dict = {
'frame_id': sample_idx,
# 'calib': calib,
}
if 'annos' in info:
annos = info['annos']
annos = common_utils.drop_info_with_name(annos, name='DontCare')
loc, dims, rots = annos['location'], annos['dimensions'], annos['rotation_y']
gt_names = annos['name']
# gt_boxes_camera = np.concatenate([loc, dims, rots[..., np.newaxis]], axis=1).astype(np.float32)
# gt_boxes_lidar = box_utils.boxes3d_kitti_camera_to_lidar(gt_boxes_camera, calib)
gt_boxes_lidar = np.concatenate([loc, dims, rots[..., np.newaxis]], axis=1).astype(np.float32)
input_dict.update({
'gt_names': gt_names,
'gt_boxes': gt_boxes_lidar
})
if "gt_boxes2d" in get_item_list:
input_dict['gt_boxes2d'] = annos["bbox"]
# road_plane = self.get_road_plane(sample_idx)
# if road_plane is not None:
# input_dict['road_plane'] = road_plane
if "points" in get_item_list:
points = self.get_lidar(sample_idx)
# if self.dataset_cfg.FOV_POINTS_ONLY:
# pts_rect = calib.lidar_to_rect(points[:, 0:3])
# fov_flag = self.get_fov_flag(pts_rect, img_shape, calib)
# points = points[fov_flag]
input_dict['points'] = points
# if "images" in get_item_list:
# input_dict['images'] = self.get_image(sample_idx)
# if "depth_maps" in get_item_list:
# input_dict['depth_maps'] = self.get_depth_map(sample_idx)
# if "calib_matricies" in get_item_list:
# input_dict["trans_lidar_to_cam"], input_dict["trans_cam_to_img"] = kitti_utils.calib_to_matricies(calib)
# input_dict['calib'] = calib
data_dict = self.prepare_data(data_dict=input_dict)
# data_dict['image_shape'] = img_shape
return data_dict
- pcdet/datasets/kitti/kitti_object_eval_python/eval.py
1、注释第57~61行
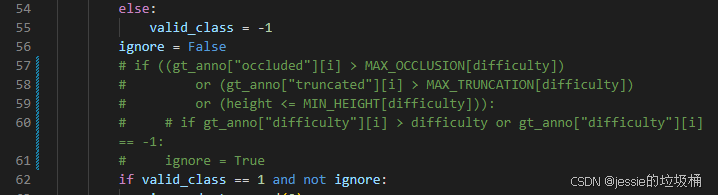
2、注释第82~87行

3、修改第69行的dc_bboxes.append(gt_anno["bbox"][i]) 为dc_bboxes.append(gt_anno["gt_boxes_lidar"][i])
4、修改第362行的dt_boxes = np.concatenate([a["bbox"] for a in dt_annos_part], 0)为 dt_boxes = np.concatenate([a["gt_boxes_lidar"] for a in dt_annos_part], 0)
5、修改第435-436行的gt_datas = np.concatenate([gt_annos[i]["bbox"], gt_annos[i]["alpha"][..., np.newaxis]], 1)为gt_datas = np.concatenate([gt_annos[i]["gt_boxes_lidar"], np.zeros(len(gt_annos[i]["gt_boxes_lidar"]))[..., np.newaxis]], 1)
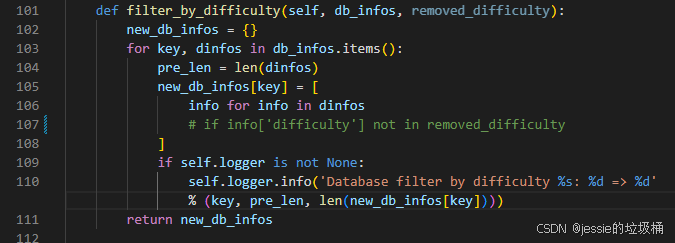
- pcdet/datasets/augmentor/database_sampler.py
1、注释第107行 if info['difficulty'] not in removed_difficulty
上述修改完成之后,需要根据自制数据集的情况对tools/cfgs/dataset_configs/kitti_dataset.yaml和tools/cfgs/kitti_models/centerpoint.yaml进行修改和配置。
首先是kitti_dataset.yaml,以下只列出需要根据实际情况修改的部分
- DATA_PATH:数据集路径
- POINT_CLOUD_RANGE:点云范围,六个数依次是[Xmin,Ymin,Zmin,Xmax,Ymax,Zmax]
- USE_ROAD_PLANE: 默认值是True,但我没这个数据,所以改为False
- VOXEL_SIZE:体素大小,[Xstep,Ystep,Zstep]
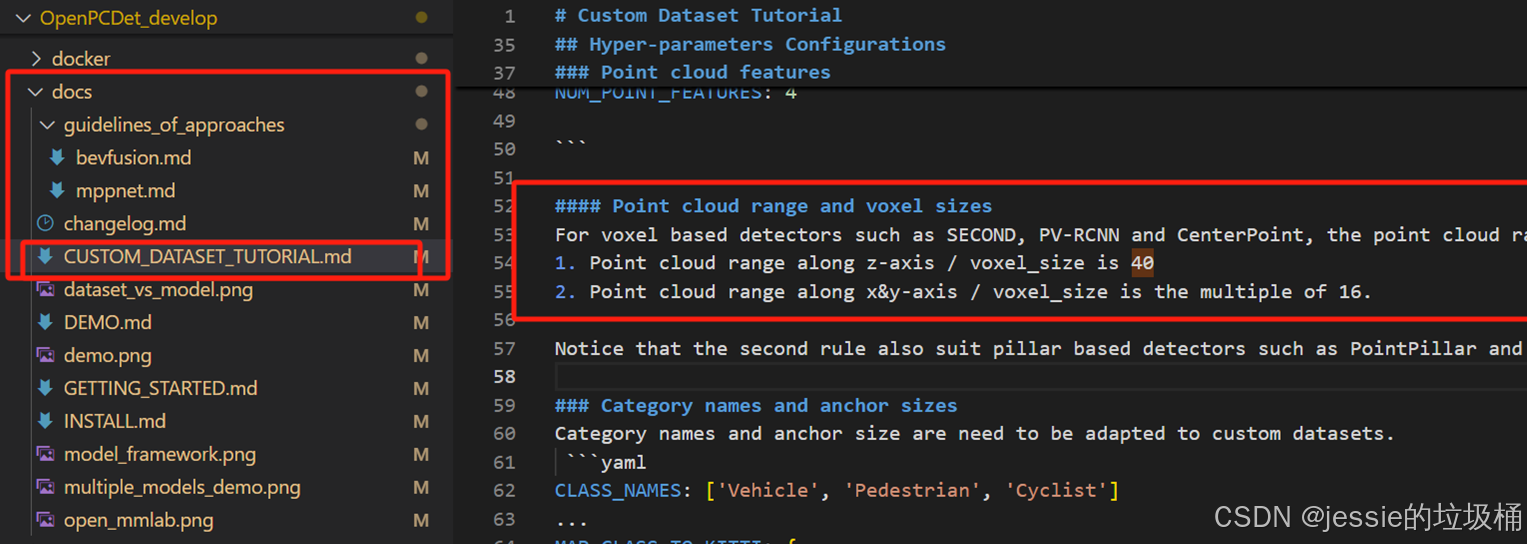
这里有一个大坑:POINT_CLOUD_RANGE和VOXEL_SIZE的设置需要满足下面的条件,不然训练会报错。这个问题官方文档里也有提到
1、(Xmax-Xmin) / Xstep 和 (Ymax-Ymin) / Ystep 的结果必须是16的整数倍
2、(Zmax-Zmin) / Zstep 的结果必须是40的整数倍
比如POINT_CLOUD_RANGE为[0, 0, -2, 69.12, 69.12, 6],相应的VOXEL_SIZE就可以设置成[0.16, 0.16, 0.2]。
然后修改centerpoint.yaml,同样只列出需要根据实际情况修改的部分
- CLASS_NAMES:数据集中的类别,也需要和kitti_dataset.yaml中用到类别的地方保持一致
- BASE_CONFIG:kitti_dataset.yaml的路径
- POST_CENTER_LIMIT_RANGE:后处理范围限制,我设置得和kitti_dataset.yaml中的POINT_CLOUD_RANGE一样
其他的我基本没有做修改。
设置完后,激活虚拟环境,环境的安装和设置参考https://blog.csdn.net/m0_64293675/article/details/144192805?spm=1001.2014.3001.5501
conda activate pcdet
然后运行下面的命令生成训练所需的pkl文件和gt_database
python -m pcdet.datasets.kitti.kitti_dataset create_kitti_infos tools/cfgs/dataset_configs/kitti_dataset.yaml

再运行下面的命令就可以开始训练啦
python tools/train.py --cfg_file tools/cfgs/kitti_models/centerpoint.yaml --epochs 120 --ckpt_save_interval 5 --batch_size 16 --workers 4
训练完成后输出召回如下
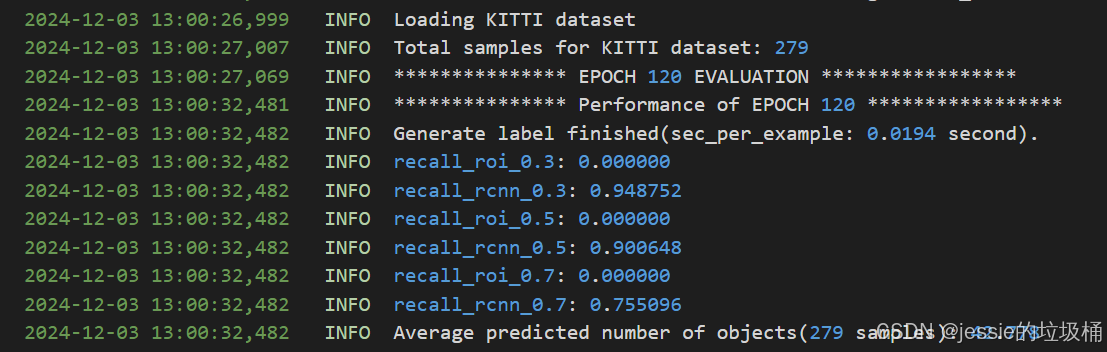
使用模型预测的可视化结果如下

模型的转换以及tensorrt的部署可以参考官方:https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution/tree/master/CUDA-CenterPoint
另外,我自己也记录了模型转换的步骤,可以参考:https://blog.csdn.net/m0_64293675/article/details/146528600?spm=1001.2014.3001.5502


















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









