






我们在模拟辐照的级联碰撞过程时,常常需要观察辐照产生的缺陷(包含间隙原子和空位)变化,通过ovito中的Wigner-Seitz defect analysis方法(即W-S法)可进行相关分析。
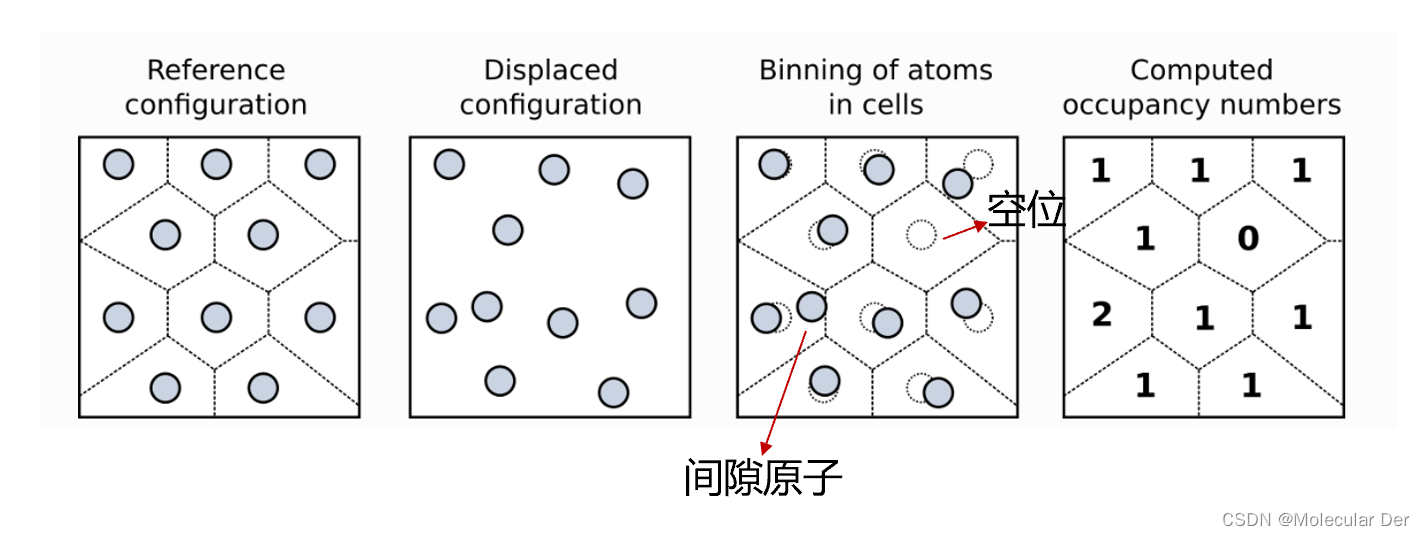
它的原理如下图所示[1],将完美晶体(未经辐照的晶体)视为参考模型,并对它进行网格划分,一个原子占据一个网格位置。辐照发生后晶体内的原子发生迁移,相较于参考模型,有的网格位置原子离开,留下一个空位,即没有原子占据;有的网格位置有其他原子进入,这些原子视为间隙原子,即存在两个及以上的原子占据。因此,我们在进行识别的时候,Occupancy==1表示未离位的原子;Occupancy==2表示间隙原子;Occupancy==0表示空位。
具体操作步骤如下:
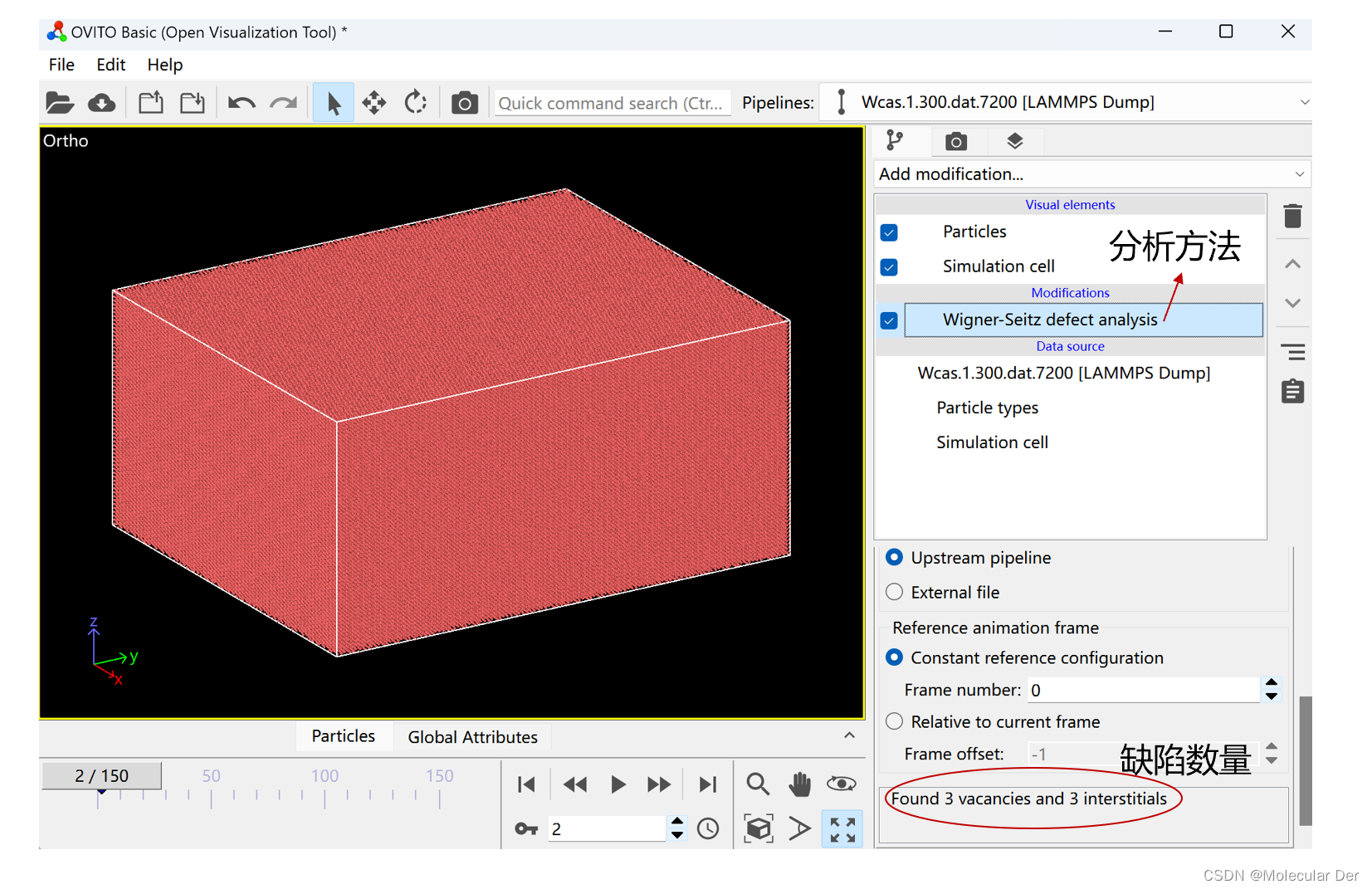
①以单晶为例,我们将计算文件拉入ovito,选择W-S分析法,命令框下方给出了缺陷数量信息(一般来说,单晶中产生的空位和间隙原子数量相等)。
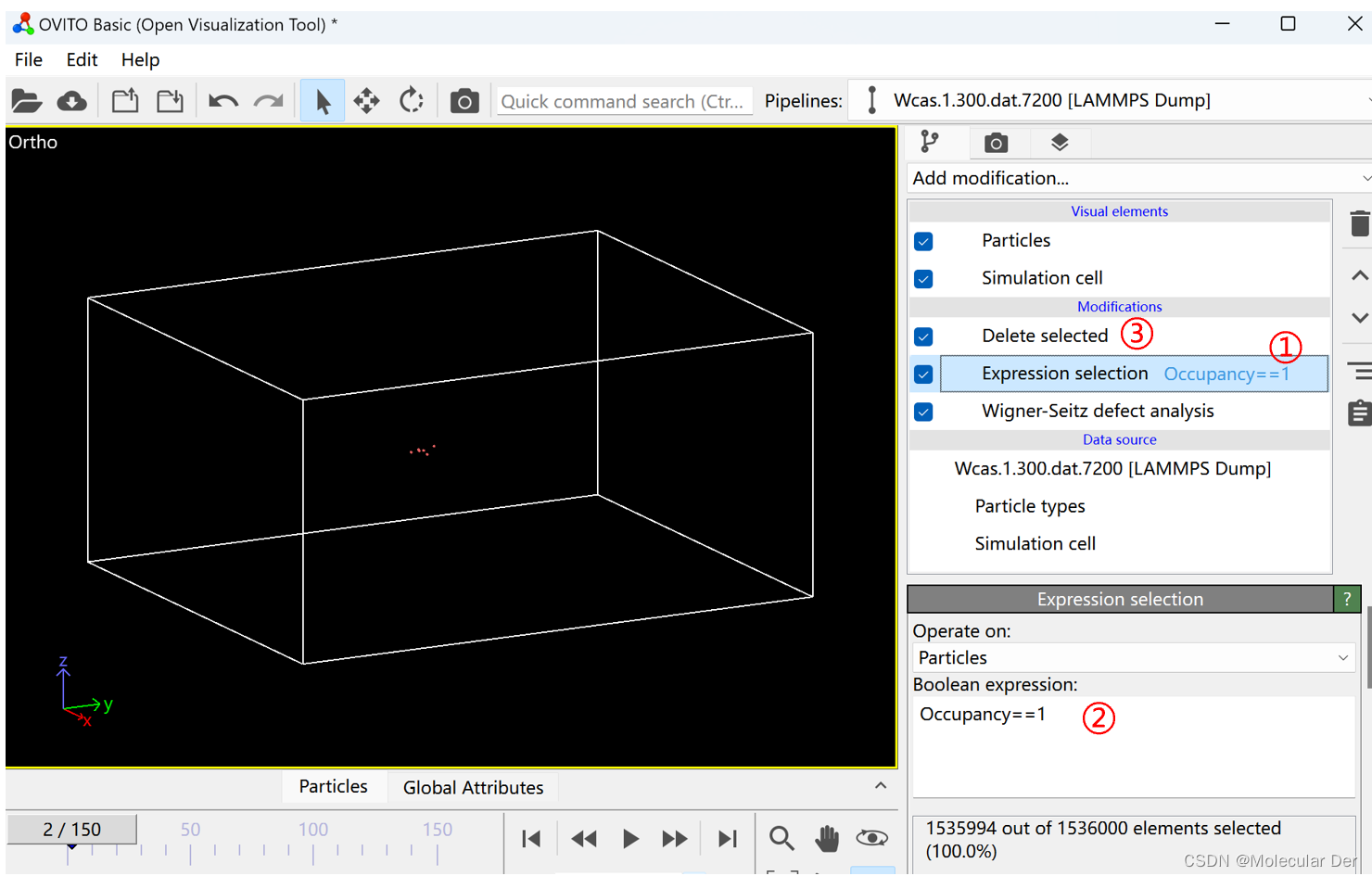
②为了更好的观察间隙原子和空位的变化,我们通过Expression selection命令,在Boolean expression框中输入Occupancy==1将未离位的原子删去。
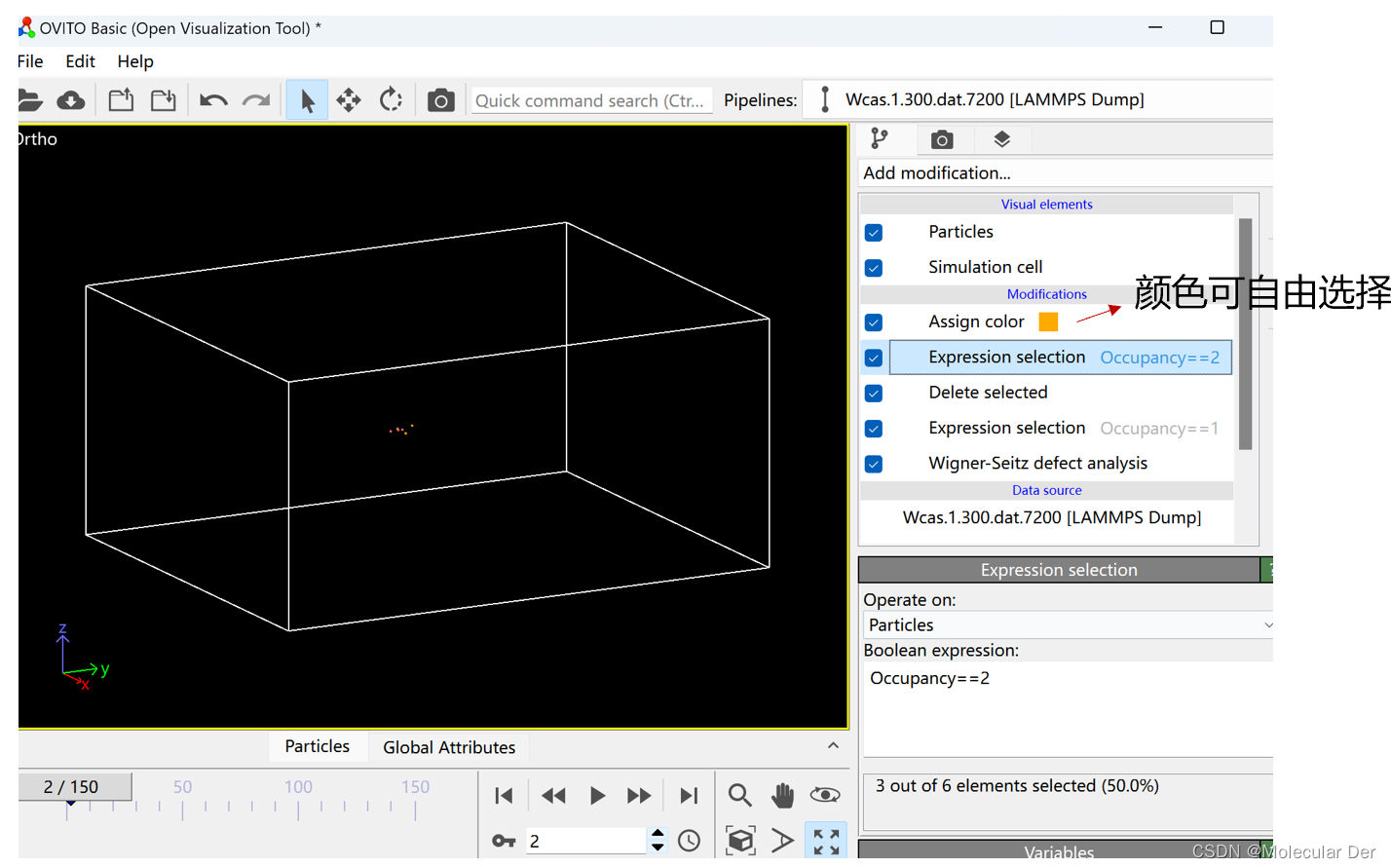
③同样通过Expression selection命令选中间隙原子(Occupancy==2或者Occupancy>1)和空位(Occupancy==0),并分别赋予不同的颜色,这样就能够帮助我们更好的观察和分析他们的变化规律。
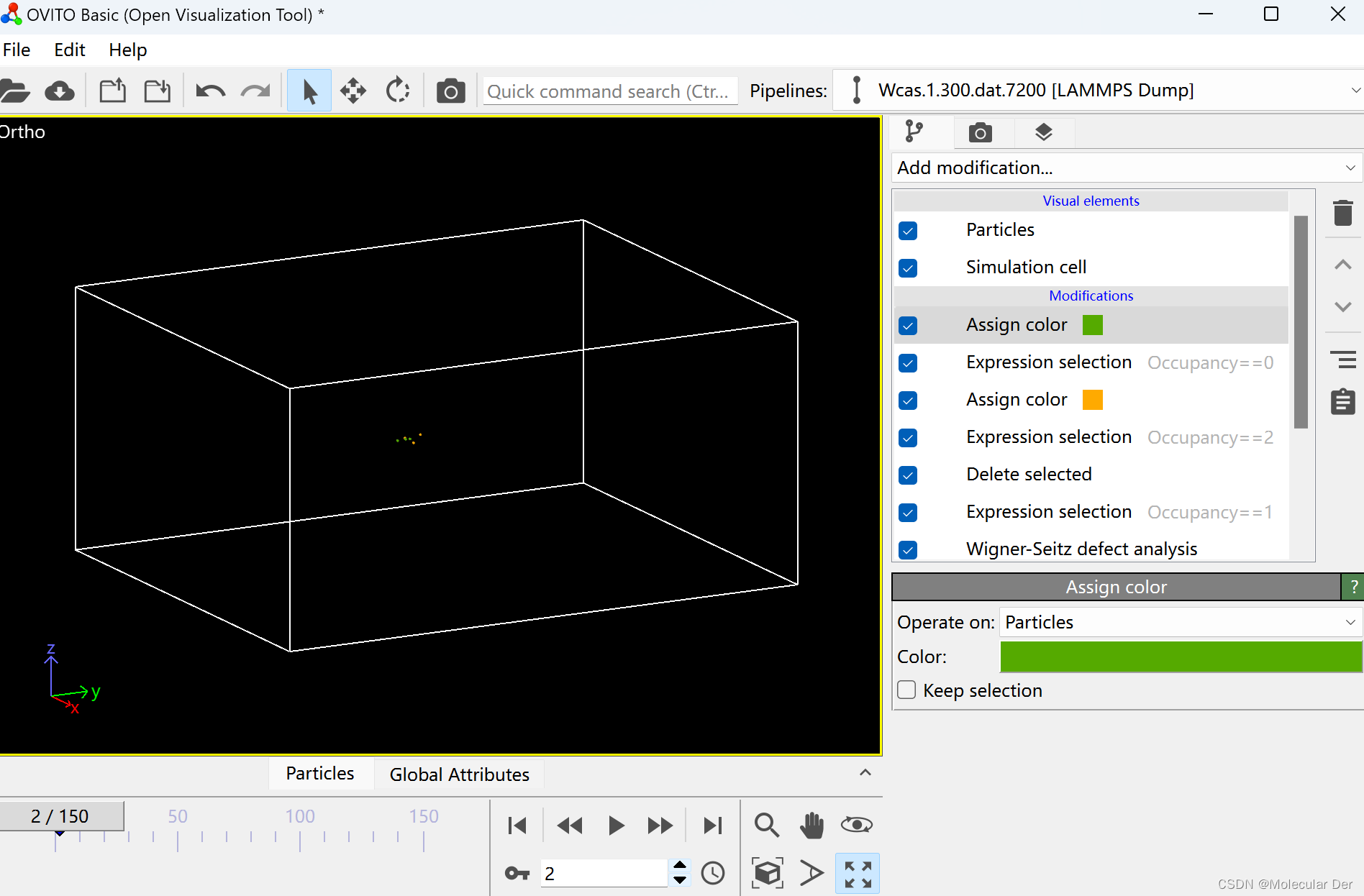
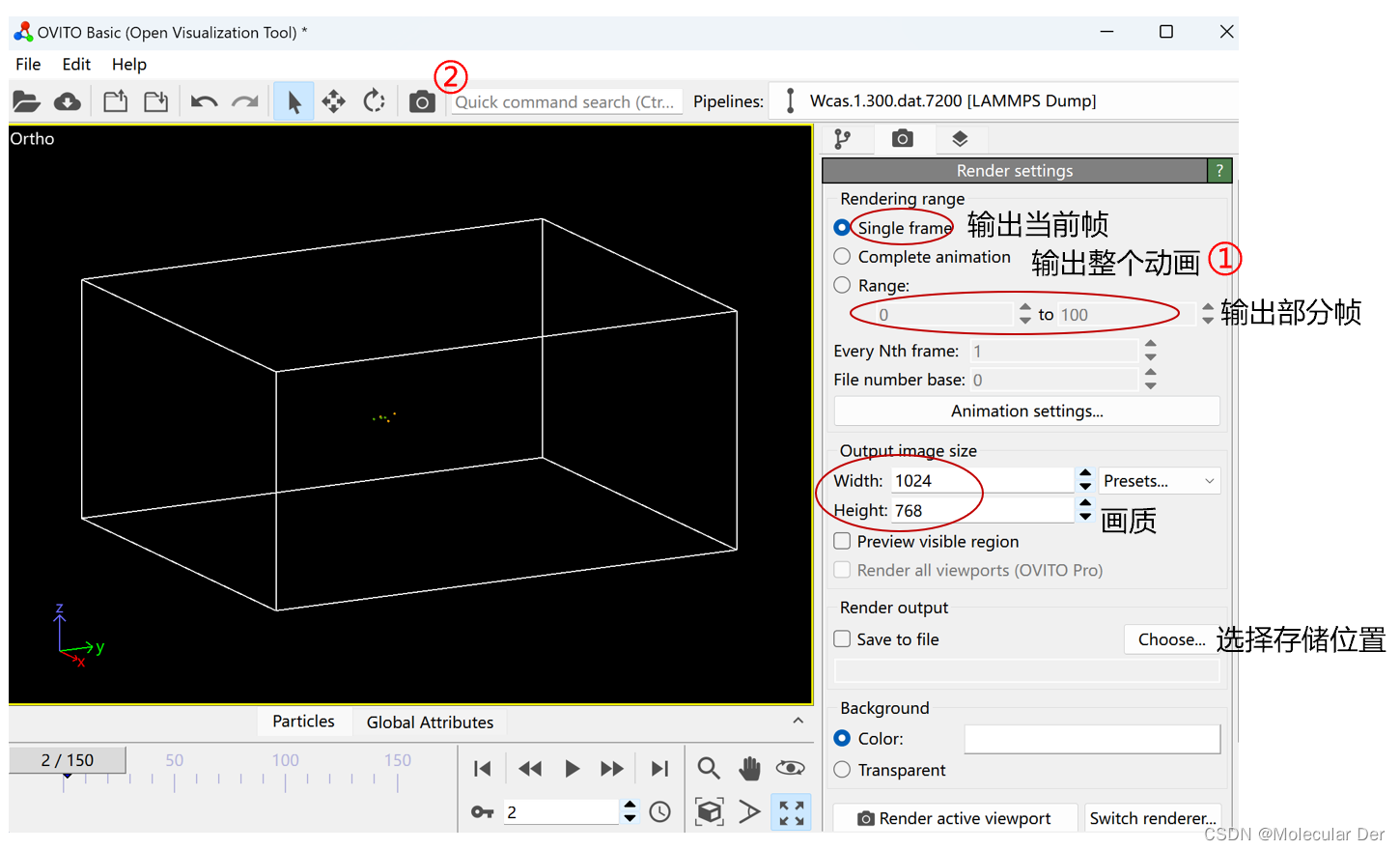
④最后,我们可以输出动画,将整个过程呈现出来(以输出整个动画为例,选择Complete animation;每1步输出一帧(Every Nth frame,类似于视频倍速,数值越大,输出动画播放越快);这里画质选择1024×768,大家可以根据自己的需求更改;勾选Save to file,选择存储位置;背景默认为白底,有需要的可以更改;最后点击图中②位置的Render即可导出,文件导出时动画注意选择gif或者mp4格式)
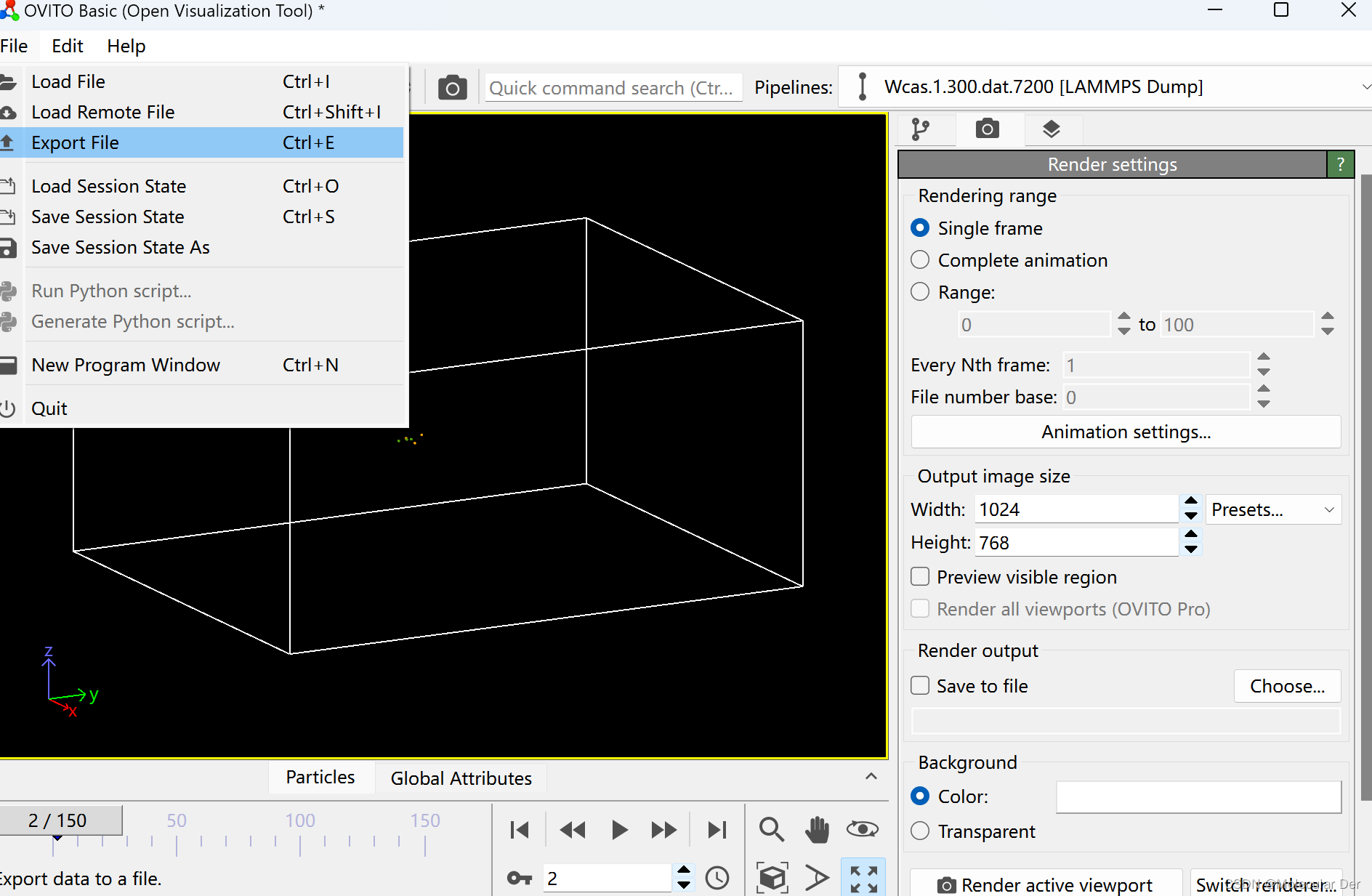
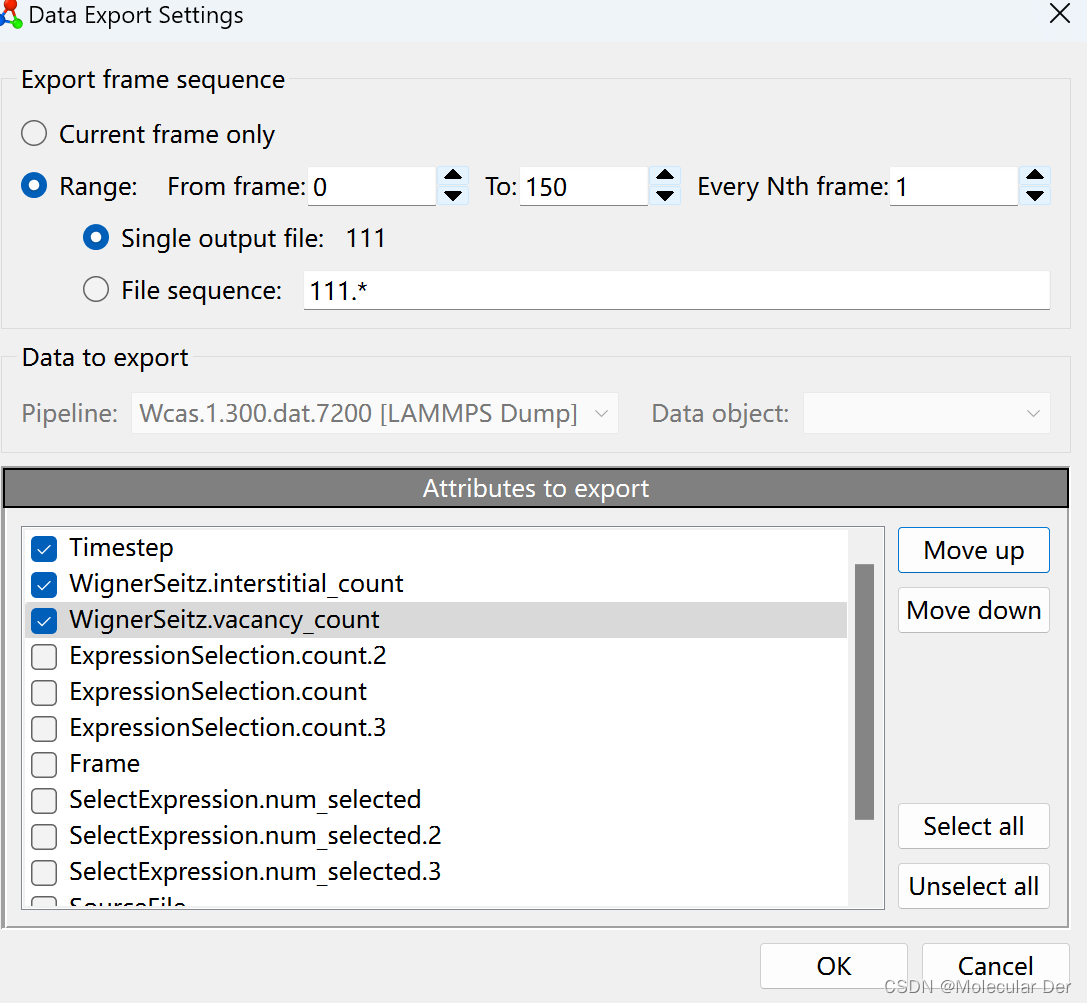
⑤还可以导出数据绘制成图。选择File,选中Export File,选择存储路径,编辑文件名,选择要输出的数据信息(这里我们选取时间步长、间隙原子和空位数量信息),这样就可以了。
[1] https://ovito.org/manual/reference/pipelines/modifiers/wigner_seitz_analysis.html
附上手册命令网址,有不足之处欢迎大家补充~


















 9636
9636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











