









目录
显著性水平(significance level) 或α-error
The power of a statistical test 检验效能
P值 P-Value (the observed significance level)
Ⅰ. 最小二乘法 ordinary least squares (OLS)
最小二乘估计量(Least Squares Estimators)
残余方差 residual variance (σ²的无偏估计)
高斯马尔科夫定理(Gauss-Markov Theorem)
Ⅳ. 预测期望y值 (For prediction interval (PI)预测区间)
Methods for standardizing residuals
Ⅱ.检验 线性(Linearity)、同方差性(Homoscedasticity)、正态性(Normality)
Ⅲ.非线性匹配后如何拟合 Remedial Measures
ANOVA-方差分析 The analysis of variance
PMF,PDF,CDF函数
PMF针对离散变量:

PDF针对连续变量:


中心极限定理 & 大数定律


协方差 Covariance
反映两个变量同向或反向的相似程度

-
相关系数

相关性分析
相关性分析是指对两个或者多个具备相关性的变量元素进行分析,从而衡量两个变量因素的密切程度相关性,换句话说这两个变量之间如果有联系那么他们有多大的联系
- 皮尔逊相关系数
皮尔逊相关系数是用于度量两个变量之间的相关(线性相关)

用皮尔逊相关系数来检验变量的相关性一般满足两个条件:
1.实验数据通常假设是成对的来自于正态分布的总体。为啥通常会假设为正态分布呢?因为我们在求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。
2.实验数据之间的差距不能太大,或者说皮尔森相关性系数受异常值的影响比较大。
- 斯皮尔曼相关系数
等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数ρ为
与皮尔逊相关系数不同的地方在于在计算之前他会先对数据进行排序防止出现异常值
- 肯德尔相关性系数
又称肯德尔秩相关系数,它也是一种秩相关系数,不过它所计算的对象是分类变量

离散系数coefficient of variation
离散系数是测度数据离散程度的相对统计量,主要是用于比较不同样本数据的离散程度。

当进行两个或多个资料离散程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其离散程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。离散系数反映单位均值上的离散程度,常用在两个总体均值不等的离散程度的比较上。若两个总体的均值相等,则比较标准差系数与比较标准差是等价的
随机变量的分布
离散变量
-
Discrete Uniform Distribution 离散均匀分布


-
Bernoulli Distribution 伯努利分布

-
Binomial Distribution 二项分布
X ~ Bin(n, p)
![]()

-
Geometric Distribution 几何分布
直到最后一次成功一次

-
Negative Binomial Distribution
X ~ NB(r , p) 重复伯努利试验直到成功r次,每次成功概率为p
![]()

-
Poisson Distribution 泊松分布
某段连续的时间内随机事件发生的次数X的概率分布
(二项分布n很大而p很小时的一种极限形式:将时间无限划分后的二项分布)
λ的意义:一个时间段内时间平均发生的次数

![]()

泊松过程Poisson process
有界的时间区间发生随机事件数
如果泊松分布的参数为μ =λT,均值与方差均为μ。在这种形式中的λ代表单位长度时间内事件发生的期望数,μ代表长度时间T内事件发生的期望数
连续变量
-
Continuous Uniform Distribution 连续均匀分布
![]()

-
Normal Distribution 正态分布

-
Exponential Distribution 指数分布
两件事情发生的平均间隔时间, x为间隔时间数
指数分布的累积分布函数(CMF)为泊松分布在时间段t内随机事件发生数不为0时的情况
(即泊松过程的事件间隔的分布)
X〜Exp(λ)




-
Erlang & Gamma Distributions
- 指数分布解决的问题:“要等到一个随机事件发生,需要经历多久时间”
- 伽玛分布解决的问题:“要等到n个随机事件都发生,需要经历多久时间”
- 厄兰分布解决的问题:“要等到第n个随机事件都发生,需要经历多久时间” (整数n)
- 泊松分布解决的:“在特定时间里发生n个事件的概率”。
Erlang Distribution

Gamma Distribution
X∼Gamma(r,λ) r是随机事件发生数,X为间隔时间
r为形状参数(shape parameter), λ为尺度参数(scale parameter)


其中,
gamma函数为


-
Chi-Squared Distribution 卡方分布
卡方分布为伽马分布的 λ = 1/2,r = ν/2 where ν = 1, 2, 3, … (v是自由度)

E(X) = n, Var(X) = 2n
Normal Approximation Method 正态拟合其他分布
with continuity correction 连续性修正
- Binomial if np > 5 and n(1-p) > 5
- Poisson if λ > 5
正态分布拟合二项分布:

统计学
自由度:以样本的统计量来估计总体的参数时,样本中独立或能自由变换的变量的个数。
抽样分布(sampling distributions):统计量(statistic)的概率分布
正态变量样本:



三大抽样分布
1.卡方分布( 分布)
分布)

设随机变量 X 是自由度为 n 的 χ2 随机变量, 则其概率密度函数为:
 的密度函数
的密度函数  形状如下图:
形状如下图:
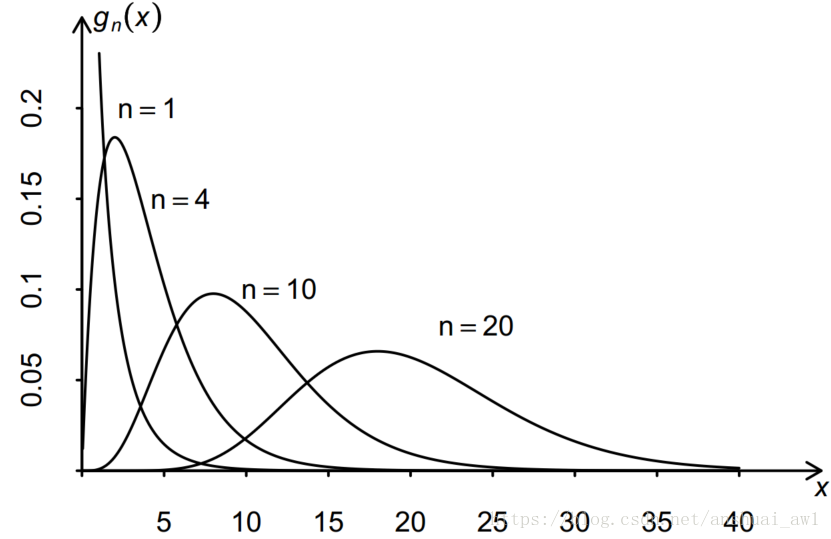
若 X ∼ , 记  ,则
,则  称为 分布的上侧
称为 分布的上侧  分位数, 如下图所示。当 和
分位数, 如下图所示。当 和  给定时可查表求出
给定时可查表求出  之值,如
之值,如 ,
, 等。
等。

卡方分布性质

2. t分布
由于在实际工作中,往往σ(总体方差)是未知的,常用s(样本方差)作为σ的估计值,为了与u变换(标准正态化)区别,称为t变换,统计量t 值的分布称为t分布。

设随机变量 T ∼  , 则其密度函数为
, 则其密度函数为

该密度函数的图形如下

t 变量具有下列的性质:

3. F分布 (Fisher费希尔分布)

若随机变量 Z ∼ , 则其密度函数为
, 则其密度函数为

自由度为 m, n 的 F 分布的密度函数如下图:

注意 F 分布的自由度 m 和 n 是有顺序的, 当  时, 若将自由度 m 和 n 的顺序颠倒一下, 得到的是两个不同的 F 分布. 从上图
时, 若将自由度 m 和 n 的顺序颠倒一下, 得到的是两个不同的 F 分布. 从上图
可见对给定 m = 10, n 取不同值时 的形状, 我们看到曲线是偏态的, n 越小偏态越严重。
的形状, 我们看到曲线是偏态的, n 越小偏态越严重。

若 F ∼ , 记  , 则
, 则  称为 F 分布的上侧 分位数 (见上图). 当 m, n 和 给定时, 可以通过查表求出
称为 F 分布的上侧 分位数 (见上图). 当 m, n 和 给定时, 可以通过查表求出 之值, 例如
之值, 例如 ,
, 等. 在区间估计和假设检验问题中常常用到.
等. 在区间估计和假设检验问题中常常用到.
F 变量具有下列的性质:

以上性质中 (1) 和 (2) 是显然的, (3) 的证明不难. 尤其性质 (3)在求区间估计和假设检验问题时会常常用到. 因为当 α 为较小的数,
如 α = 0.05 或 α = 0.01, m, n 给定时, 从已有的 F 分布表上查不到  和
和  之值, 但它们的值可利用性质(3) 求得, 因为
之值, 但它们的值可利用性质(3) 求得, 因为  和
和 是可以通过查 F 分布表求得的.
是可以通过查 F 分布表求得的.
参数估计(Estimator)
Ⅰ.点估计(point estimator)
用样本的估计量的某个取值直接作为总体参数的估计值

构造点估计常用的方法是:
- 矩估计法 (moments),用样本矩估计总体矩
- 最大似然估计法。利用样本分布密度构造似然函数来求出参数的最大似然估计。
- 最小二乘法。主要用于线性统计模型中的参数估计问题。
- 贝叶斯估计法。
1.矩估计法 (moments)
1 .用样本的一阶原点矩来估计总体的均值μ
2 .用样本的二阶中心矩来估计总体的方差σ2
样本k阶(原点)矩

样本k阶中心矩

2.极大似然估计 (maximum likelihood)

点估计的评价准则(无偏性unbiased,一致性,有效性minimal variance)



估计值的均方误差MSE
![]()

点估计的选择
- A biased estimator can be preferred to an unbiased estimator if it has a smaller MSE.
- UMVUE(一致最小方差无偏估计)选择无偏估计方差更小的
- An estimator whose MSE is smaller than that of any other estimator is called an optimal estimator.
Ⅱ.区间估计(interval estimator)
根据样本统计量的抽样分布能够对样本统计量与总体参数的接近程度给出一个概率度量

置信区间 Confidence Intervals
由样本统计量所构造的总体参数的估计区间称为置信区间
-
样本量的确认(估计总体均值时)


-
置信水平 confidence level & (1-α) confidence coefficient

-
单侧置信区间 One-Sided Confidence Bounds

-
区间估计步骤


-
一个总体参数的区间估计


-
两个总体参数的区间估计


假设验证 Hypothesis Tests
假设检验是先对总体参数提出一个假设值,然后利用样本信息判断这一假设是否成立
假设检验的基本思想是小概率反证法思想,小概率思想认为小概率事件在一次试验中基本上不可能发生,在这个方法下,我们首先对总体作出一个假设,这个假设大概率会成立,如果在一次试验中,试验结果和原假设相背离,也就是小概率事件竟然发生了,那我们就有理由怀疑原假设的真实性,从而拒绝这一假设。
通过证明样本对应的p-value小于α ,以此推翻原假设,接受备择假设
提出假设Statistical Hypotheses
- H0 原假设 (null hypothesis)
- H1 备择假设 (alternative hypothesis)
两类错误



- 弃真错误,也叫第I类错误或α错误
原假设实际上是真的,但通过样本估计总体后,拒绝了原假设。明显这是错误的,我们拒绝了真实的原假设,所以叫弃真错误,这个错误的概率我们记为α。这个值也是显著性水平,在假设检验之前我们会规定这个概率的大小。
- 取伪错误,也叫第II类错误或β错误
原假设实际上假的,但通过样本估计总体后,接受了原假设。明显者是错误的,我们接受的原假设实际上是假的,所以叫取伪错误,这个错误的概率我们记为β。
犯第I类错误的概率已经被规定的显著性水平所控制,对统计者来说更容易控制,将错误影响降到最小。
显著性水平(significance level) 或α-error
显著性水平是指当原假设实际上正确时,检验统计量落在拒绝域的概率,简单理解就是犯弃真错误(Type I error)的概率。这个值是我们做假设检验之前统计者根据业务情况定好的。
The power of a statistical test 检验效能
当原假设不为真时拒绝原假设的概率,即1-β
P值 P-Value (the observed significance level)
在原假设成立的前提下,比所得到的样本观察结果更极端的结果出现的概率。拒绝原假设的最低显著水平。

如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。
- 若P>α,就没有理由怀疑H0的真实性,结论为不拒绝H0,不否定此样本是来自于该总体的结论,也即差别无显著意义。
- 若P≤α,则拒绝H0,接受H1,也就是这些统计量来自不同的总体,其差别不能仅由抽样误差来解释,结论为差别有显著性意义(statistically significant)。
检验方式
-
单侧检验
备择假设带有特定的方向性,拒绝H0总是一个强结论

-
双侧检验

检验统计量
在零假设情况下,这项统计量服从一个给定的概率分布,而这在另一种假设下则不然。从而若检验统计量的值落在上述分布的临界值之外,则可认为前述零假设未必正确。统计学中,用于检验假设量是否正确的量。常用的检验统计量有t统计量,Z统计量等。(n>30一般认为足够大)

假设检验步骤
- 提出原假设与备择假设
- 从所研究总体中出抽取一个随机样本
- 构造检验统计量:t统计量,Z统计量
- 根据显著性水平确定拒绝域临界值
- 计算检验统计量与临界值进行比较
统计检验方法
1. t检验
一般用于定量数据的检测(定类数据采用卡方检验),T检验的前提条件是假设样本服从或者近似服从正态分布
- 单样本均值检验(One-sample t-test

- 两独立样本均值检验(Independent two-sample t-test)
总体方差相等且未知:

其中,
总体方差不同且未知:
 自由度为:
自由度为:
- 配对样本均值检验 (总体方差相同)
适用情况:同一受试对象的两个部分接受不同的处理 或前后对照处理
验证![]() 均值是否为0,其标准差
均值是否为0,其标准差


2. 卡方检验
- 检验拟合优度
依据总体分布状况,计算出分类变量中各类别的期望频数,与分布的观察频数进行对比,判断期望频数与观察频数是否有显著差异,从而达到从分类变量进行分析的目的
 检验统计量
检验统计量
- 检验变量之间的相关性
3. F检验
- 方差齐性检验


- (单因素)ANOVA方差分析

其中 SSA是各个水平之间的偏差平方和,也可以说成是组间平方和(Sum of Square Between Groups),SSE是各个水平内部的偏差平方和,可以说成是组内偏差平方和,可以理解为上面说的误差的平方和(Sum of Square Error)

- 线性回归显著性检验

统计模型
简单线性回归模型(SLR)
线性回归:请注意,它是针对回归系数要求线性

也就是三个基本假设
线性回归参数估计
Ⅰ. 最小二乘法 ordinary least squares (OLS)
残差和误差:

调整β最小化RSS

得出:
最小二乘估计量(Least Squares Estimators)

所以 yi 也可以被写作:![]() ,其中ri是残差
,其中ri是残差
残余方差 residual variance (σ²的无偏估计)

残差标准差 
高斯马尔科夫定理(Gauss-Markov Theorem)
证明了如果误差满足零均值、同方差且互不相关,那么利用最小二乘法(OLS)进行线性回归得到的估计参数是最佳的以及无偏的。所以普通最小二乘法估计是对回归系数的最佳线性无偏估计 (BLUE, Best Linear Unbiased Estimator)
Ⅱ. 极大似然估计 Maximum likelihood
y服从正态分布(因为y是误差项ε的线性组合):

似然函数
 其中,
其中,![]()
最大化似然函数,需要求导为0,得出:

图片解释:

其中,
MLE的σ²为有偏估计

线性回归参数的抽样分布&假设估计
Ⅰ. 斜率slope β1
根据 ,求标准差
,求标准差
所以:


σ未知情况下,t分布 (回归系数的区间估计)

回归系数的显著性检验:
t检验 f检验
f检验
其中
如果用相关系数  则
则 
Ⅱ. 偏置 β0
根据![]() ,求其标准差
,求其标准差


β0和β1的协方差
Ⅲ. 期望平均值μ (全局)For 置信区间CI
![]()
得到其标准差
这里x尖为x的方差
95%置信区间为:
![]()
Ⅳ. 预测期望y值 (For prediction interval (PI)预测区间)
![]()
其标准差为
即x处的方差和y平均值方差之和
95%预测区间为(假设误差正态性):
![]()
置信区间估计(confidence interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的平均值的估计区间。
预测区间估计(prediction interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的一个个别值的估计区间。
判断数据是否适合线性回归模型
Ⅰ. 残差分析(Residual analysis)
- Quantile plots
- Scatterplots
- Histograms直方图, stem and leaf diagrams and boxplots
Methods for standardizing residuals
- Standardized residuals 标准化残差 也称Pearson残差或半学生化残差(semi-studentized residuals)
 (
( 是残差的标准差的估计) 残差除以其标准差后得到的数值。
是残差的标准差的估计) 残差除以其标准差后得到的数值。
如果误差项  服从正态分布的这一假定成立,则标准化残差的分布也服从正态分布。大约有95%的标准化残差在 -2~2 之间。
服从正态分布的这一假定成立,则标准化残差的分布也服从正态分布。大约有95%的标准化残差在 -2~2 之间。
- Studentized residuals 学生化残差
- Jackknife residuals
Ⅱ.检验 线性(Linearity)、同方差性(Homoscedasticity)、正态性(Normality)
- Y-X散点图
- 残差散点图(Residual Scatterplot)

- 残差直方图Residual Histogram
- Normal Probability Plot (Quantile-quantile plots 分位数-分位数图, QQ图)
residuals vs the expected standard deviation from a Normal Distribution
理论值为分位数(将观察值视为等分的实际分布)
分位数(Quantile),亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点。分位数指的就是连续分布函数中的一个点,这个点对应概率p。若概率0<p<1,随机变量X或它的概率分布的分位数Za,是指满足条件p(X≤Za)=α的实数。
常用的有中位数(即二分位数)、四分位数、百分位数等
分位数-分位数图(quantile-quantile plot)或q-q图对着另⼀个对应的分位数,绘制⼀个单变量分布的分位数。它是⼀种强有⼒的可视化
⼯具,使得⽤户可以观察从⼀个分布到另⼀个分布是否有漂移

Ⅲ.非线性匹配后如何拟合 Remedial Measures
- 更换非线性模型
- Transformations on X:当误差分布近似正态分布
- Transformations on Y:当误差分布是非正态性并且方差各不同
- Box Cox Transforms
回归分析Regression Analysis
1. 基本方程
total variation = regression sum of squares + error sum of squares


证明: 证明 总偏差平方和 = 回归平方和 + 残差平方和_心态与做事习惯决定人生高度的博客-CSDN博客_总偏差平方和
各自方差
- SSTO:n-1自由度 包含平均值

- SSE:n-2自由度 β0 and β1

- SSR:1 自由度 只有斜率
![]()
2. 回归评价指标 \ 拟合优度
- 均方误差:MSE(Mean Squared Error)
- 均方根误差:RMSE(Root Mean Squard Error)
- 平均绝对误差:MAE(Mean Absolute Error)
- 决定系数:R²(R-Square)

 SSTO=SST
SSTO=SST
![]()
一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着样本数量的增加,R-Squared 必然增加,无法真正定量说明准确程度,只能大概定量。
单独看 R-Squared,并不能推断出增加的特征是否有意义。通常来说,增加一个特征特征,R-Squared 可能变大也可能保持不变,两者不一定呈正相关。
- 校正决定系数(Adjusted R-Squared)

其中,n 是样本数量,p 是特征数量。Adjusted R-Squared 抵消样本数量对 R-Squared 的影响,做到了真正的 0~1,越大越好。调整R方剔除了自变量个数的影响,其值总是小于R方。
增加一个特征变量,如果这个特征有意义,Adjusted R-Square 就会增大,若这个特征是冗余特征,Adjusted R-Squared 就会减小。
多元线性回归分析MLR
三条基本假定:

基本形式:


在正态假定下,如果X是列满秩的,则普通线性回归模型的参数最小二乘估计为:![]()
于是y的估计值为:
单个系数显著检验的t-检验量:
 σβ是对应标准差,样本数量为p,则自由度1为n-(p+1)
σβ是对应标准差,样本数量为p,则自由度1为n-(p+1)
由 ![]() 得到具体t检验量
得到具体t检验量
其中cjj 是 ![]() 的对角线元素
的对角线元素
方程显著性检验:
![]()

Estimate & Inference of β in MLR
Estimate: • Fisher-scoring Method • Newton-Raphson Method • Iteratively Re-weighted Least Squares (IRLS)
Inference: • Wald Tests • score • likelihood ratio
Wald test
Wald回归系数的检验要求:n足够大,每个β近似正态分布
![]()
原假设![]() 则z统计量为
则z统计量为
实际中,计算β的置信区间![]()
其中z*是标准z分数
ANOVA-方差分析 The analysis of variance
1. 方差分析表 ANOVA Table (回归分析)


多元回归分析, p为自变量x个数, df 自由度
期望值:
- MSR

- MSE

2. F检验 简单线性回归 (回归系数的显著性检验)
H0 : β1 = 0
原假设成立时 F趋于1,不成立时 F大于1

MSR/MSE的意义: 笔者认为其参考的是观察点是否可被线性拟合的能力
推导:
科克伦定理 Cochran’s theorem

根据科克伦定理:

 所以
所以 ![]()
对于t检验同样的假设验证:

3. 方差分析

方差分析确定三个或更多组的均值是否不同。 ANOVA使用F-test来检验均值是否相等。
差异研究的目的在于比较两组数据或多组数据之间的差异,通常包括以下几类分析方法,分别是方差分析、T检验和卡方检验。



误差分解+方差分析
单因子:


效应量分析:
它反映了在因变量取值的总误差中被因子解释的比例,效应量越大说明自变量与因变量之间的关系就越强

多因子:


效应量Effect size
衡量自变量和因变量之间关联强度的指标,它是原假设H0错误的程度且几乎不受样本量大小的影响。换句话理解:当效应量过小时,自变量就是不重要的
| 效应量类型 | 效应量名称 | 适用数据形式 |
|---|---|---|
| Correlation family | Pearson r | Correlational data |
| R² (r-squared) | Correlational data | |
| η² (Eta-squared) | Correlational data | |
| ω² (Omega-squared) | Correlational data | |
| Difference family | Cohen's d | Continuous data |
| Hedges' g | Continuous data | |
| Categorical family | Cohen's w | Binary data |
| Odds ratio (OR) | Binary data | |
| Relative risk (RR) | Binary data |


计算:

广义线性模型GLM
定义
广义线性模型(Generalized Linear Model)是线性模型的扩展,通过连接函数建立因变量(y)的数学期望值与线性组合(WX)的预测变量之间的关系。其中因变量y属于线性指数族分布,指数族是以自然指数e为基础、各类分布的统一形式化。
GLM 有三个假设:
1.在给定 x 的条件下,假设随机变量 y 服从某个指数族分布;
2.在给定 x 的条件下,我们的目标是得到一个模型 h(x) 能预测出 T(y) 的期望值;
3.假设该指数族分布中的自然参数 η 和 x 呈线性关系,即 η= w^T x
指数分布族:

η:分布的自然参数(natural parameter)或者称为标准参数(canonical parameter)
T (y):充分统计量,通常用T(y) = y
a(η):对数分割函数(log partition function)
:本质上是一个归一化常数,确保概率和为1。
当给定T时,a、b就定义了一个以η为参数的一个指数分布。我们变化η就得到指数分布族的不同分布。
Bernoulli分布的指数分布族形式:


可以得到:![]()

Gaussian 分布的指数分布族形式:
因为theta对参数选择没有影响,将theta设为1方便计算


构建广义线性模型
- 选择一个输出y服从的线性指数族分布。
- 分布的自然参数η与输入X保持线性关系即η=Xβ。
- 通过连接函数表达输出y的期望与自然参数本身之间的关系即η=g(E[y]),结合2,从而建立输出y与输入X之间的关系。

广义线性模型 推导出 线性回归:
step1: ![]()
step2: 由假设2 对拟合函数期望 ![]() 得到:
得到:

广义线性模型 推导出 逻辑回归:
step1: ![]()
step2: 与上面同理

连接函数(link function)
link function的作用是把Y与X间的非线性关系转换成线性关系


广义线性模型总结

逻辑回归 Logistic Regression
Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计
逻辑回归模型

Odd ratio OR值
取x=0或1时,log的值区别为β1的值:

所以e^β1被称为odd ratio, 代表x=1对x=0的优势比,比值比
似然方程获取β参数
重写逻辑回归模型方程,得到:

写成似然函数:

g函数就是px,然后使用极大似然估计求出参数
回归系数的置信区间
可以使用Walt检验,![]() ,z*是标准z分数
,z*是标准z分数
贝叶斯线性回归 (Bayesian Linear Regression)

输出 y 是从一个由均值和方差两种特征刻画的正态(高斯)分布生成的。线性回归的均值是权重矩阵的转置和预测变量矩阵之积。方差是标准差 σ 的平方(乘以单位矩阵,因为这是模型的多维表示)。
推断和预测 (Inference & prediction)
根据 中似然和先验P(w)算出参数w的后验分布
中似然和先验P(w)算出参数w的后验分布
得到w后验分布,加上新数据x*,可以预测y*的分布
推导过程:
参数估计:最大似然
似然方程:

我们要求的是![]()
假设先验概率分布满足正态分布(高斯分布)
![]() , 高斯分布为
, 高斯分布为 
多元高斯分布方程为
后验概率![]()
依据仿射变换Affine transformation,得到

References
统计学之参数估计(点估计和参数估计)含例题和解答_Lora青蛙的博客-CSDN博客_统计学参数估计例题
统计学简介之十——样本量的确定_LthID的博客-CSDN博客_样本量的确定公式
残差分析(残差原理与标准化残差分析)_我不爱机器学习的博客-CSDN博客_残差分析
三大抽样分布:卡方分布,t分布和F分布的简单理解_anshuai_aw1的博客-CSDN博客_t分布
卡方分布_ClintonZero的博客-CSDN博客_卡方分布
多元线性回归模型_米斯特黄的博客-CSDN博客_多元线性回归模型
广义线性模型(Generalized Linear Models) - 奋斗少年Cornelius - 博客园















 3898
3898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









