






01
引言
近期,Meta开源了Llama 3.3 多语言大型语言模型(LLM),Llama 3.3 是一个预训练并经过指令调优的生成模型,参数量为70B(文本输入/文本输出)。Llama 3.3 指令调优的纯文本模型针对多语言对话用例进行了优化,并在常见的行业基准测试中优于许多可用的开源和闭源聊天模型。
Llama 3.3 是一个使用优化后的Transformer架构的自回归语言模型。调优版本使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)来与人类对有用性和安全性的偏好保持一致。
-
训练数据:新的公开在线数据混合集
-
参数量:70B
-
输入模态:多语言文本
-
输出模态:多语言文本和代码
-
上下文长度:128K
-
GQA:是
-
训练tokens:15T+(仅指预训练数据)
-
知识截止日期:2023年12月
-
支持的语言: 英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语
*注:Llama 3.3 的训练数据集包含了比所支持的8种语言更广泛的语言。开发者可以在遵守 Llama 3.3 社区许可和可接受使用政策的前提下,对 Llama 3.3 模型进行微调以支持更多语言,在这种情况下,开发者需确保在额外语言中使用 Llama 3.3 是安全且负责任的行为。
02
模型下载
模型链接:
https://www.modelscope.cn/models/LLM-Research/Llama-3.3-70B-Instruct
CLI下载:
modelscope download --model LLM-Research/Llama-3.3-70B-Instruct
Python SDK下载:
#模型下载``from modelscope import snapshot_download``model_dir = snapshot_download('LLM-Research/Llama-3.3-70B-Instruct')
===
03
模型推理
transformers推理
import transformers``import torch``from modelscope import snapshot_download`` ``model_id = snapshot_download("LLM-Research/Llama-3.3-70B-Instruct")`` ``pipeline = transformers.pipeline(` `"text-generation",` `model=model_id,` `model_kwargs={"torch_dtype": torch.bfloat16},` `device_map="auto",``)`` ``messages = [` `{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},` `{"role": "user", "content": "Who are you?"},``]`` ``outputs = pipeline(` `messages,` `max_new_tokens=256,``)``print(outputs[0]["generated_text"][-1])
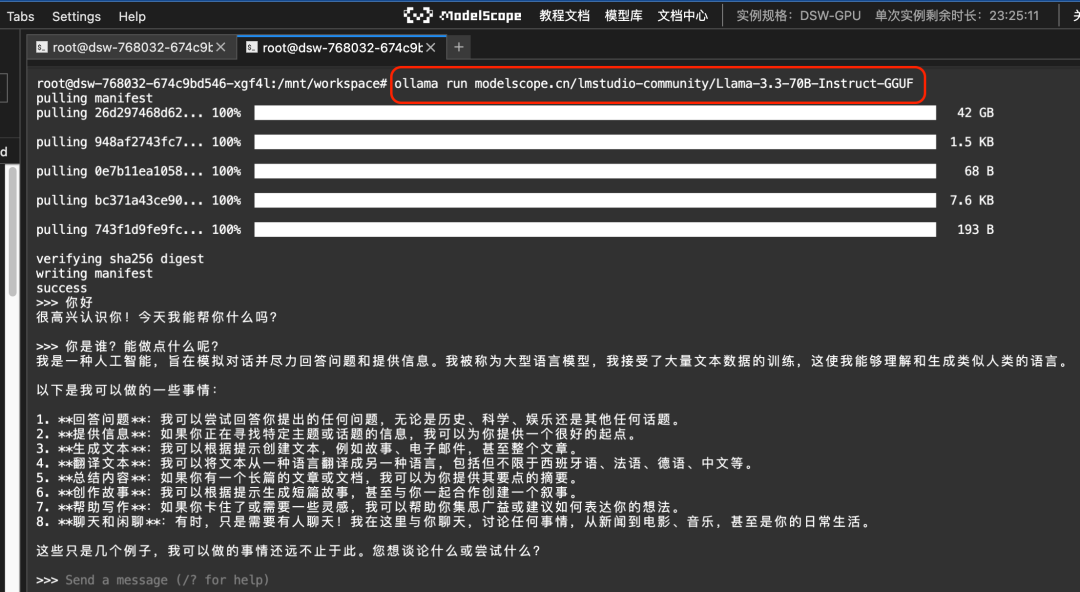
Ollama:一行命令运行魔搭上的 Llama-3.3-70B-Instruct GGUF模型
- 设置ollama下启用
ollama serve
- ollama run ModelScope任意GGUF模型,指定model id即可:
ollama run modelscope.cn/lmstudio-community/Llama-3.3-70B-Instruct-GGUF
04
模型微调
这里我们介绍使用ms-swift 3.0对Llama3.3进行自我认知微调。
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift``pip install git+https://github.com/modelscope/ms-swift.git
微调脚本如下:
CUDA_VISIBLE_DEVICES=0,1 swift sft \` `--model LLM-Research/Llama-3.3-70B-Instruct \` `--dataset AI-ModelScope/alpaca-gpt4-data-zh#500 \` `AI-ModelScope/alpaca-gpt4-data-en#500 \` `swift/self-cognition#500 \` `--train_type lora \` `--lora_rank 8 \` `--lora_alpha 32 \` `--num_train_epochs 1 \` `--logging_steps 5 \` `--torch_dtype bfloat16 \` `--max_length 2048 \` `--learning_rate 1e-4 \` `--output_dir output \` `--target_modules all-linear \` `--model_name 小黄 'Xiao Huang' \` `--model_author 魔搭 ModelScope \` `--per_device_train_batch_size 1 \` `--gradient_accumulation_steps 16
训练显存占用:

推理脚本:
若出现兼容问题,请关注:https://github.com/modelscope/ms-swift
CUDA_VISIBLE_DEVICES=0 swift infer \` `--ckpt_dir output/vx-xxx/checkpoint-xxx \` `--stream true
推理效果:

AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











