






摘要
从神经信号中解码人类语音对于脑机接口(BCI)技术来说至关重要,这项技术旨在为有神经缺陷的人群恢复语音能力。然而,这仍然是一个已知的任务,主要是由于与语音对应的神经信号稀缺、数据复杂性以及高维度问题。这里,我们提出了一个基于深度学习的新型神经语音解码框架,该框架包括一个将皮层电图(ECoG)信号从大脑皮层翻译成可解释语音参数的ECoG解码器,以及一个将语音参数映射到声谱图的新型可微分语音合成器。语音到语音的自编码器,包括一个语音编码器和相同的语音合成器,以生成相关语音参数,从而促进ECoG解码器的训练。该框架能够生成自然语音的语音,并且在48名参与者的队列中具有高度可重复性。我们的实验结果表明,我们的模型能够以高相关性解码语音,仅限于因果操作(即使对于这种实时神经假体应用是必要的)。最后,我们成功地在左侧或右侧大脑半球覆盖的参与者中解码了语音,这可能为影响右侧半球损伤并导致缺陷的患者开发语音假体提供了支持。
- 语音参数(SpeechParameters)
- 定义:描述语音特征的一些数值,如音高(音高)、焦点峰(共振峰)等。
- 基础知识:语音是由声带振动和口腔形状决定的,这些参数是中间表示,方便从信号到声音的转换。
- 论文中的作用:ECoG解码器输出这些参数,而不是直接生成声音。
- 声谱图(Spectrogram)
- 定义:一个可视化声音的图像,横轴是时间,纵轴是频率,颜色表示强度。
- 基础知识:声谱图是语音信号处理的核心工具,常用于语音合成或分析。
- 论文中的作用:语音合成器把参数变成声谱图,重新生成可听到的声音
- 可微分语音合成器(Differentiable Speech Synthesizer)
- 定义:一种可以用梯度优化的合成器,适合与神经网络一起训练。
- 基础知识:可微分意味着它能够模拟复杂学习的训练过程,比传统合成器更灵活。
- 论文中的创新点:这是他们的一个新设计,能够提高解码精度。
- 因果操作(Causal Operations)
- 定义:只用过去和当前的数据进行处理,不依赖未来数据。
- 基础知识:实时系统(如假体)必须是因果的,因为不能“预知”未来的信号。
- 论文中的意义:模型即使在这种限制下也表现良好,说明其实用性强。
- 自编码器(Auto-Encoder)
- 定义:一个神经网络,先压缩数据(编码),再重建数据(解码),常用于学习数据的表示。
- 基础知识:这里是“语音到语音”,输入语音,输出参考参数,帮助解码器。
- 论文中的作用:提供了一个标准,让ECoG解码器知道目标是什么。
方法
实验设计
我们从 48 名患有难治性癫痫的英语母语参与者(26 名女性,22 名男性)那里收集了神经数据,他们在纽约大学朗格尼医院植入了 ECoG 硬膜下电极网格。五名参与者接受了 HB 采样,43 名参与者接受了 LD 采样。32 名参与者在左半球植入 ECoG 阵列,16 名参与者在右半球植入。纽约大学格罗斯曼医学院的机构审查委员会批准了所有实验程序。在咨询临床护理提供者后,研究团队成员获得了每位参与者的书面和口头同意。每位参与者执行五项任务47,以响应听觉或视觉刺激产生目标词。这些任务包括听觉重复(AR,重复听觉单词)、听觉命名(AN,根据听觉定义命名单词)、句子完成(SC,完成听觉句子的最后一个单词)、视觉阅读(VR,大声朗读书面单词)和图片命名(PN,根据彩色图画命名单词)。对于每项任务,我们使用精确的 50 个目标单词和不同的刺激模式(听觉、视觉等)。每个单词在 AN 和 SC 任务中出现一次,在其他任务中出现两次。这五项任务涉及 400 次试验,每个参与者都有相应的单词产生和 ECoG 记录。每次试验产生的语音平均持续时间为 500 毫秒。
数据收集与重建
该研究记录了 48 名参与者在执行五项语音任务时的大脑外侧裂皮质(包括 STG、下额回 (IFG)、中央前回和中央后回)的 ECoG 信号。麦克风记录了受试者的语音,并与临床 Neuroworks 量子放大器 (Natus Biomedical) 同步,后者捕获 ECoG 信号。对于 43 名低密度采样的参与者,ECoG 阵列由 64 个标准 8×8 宏接触(间距 10 毫米)组成。对于五名采用混合密度采样的参与者,ECoG 阵列还在宏接触之间包含 64 个额外的散布较小电极(1 毫米)(宏接触之间的中心间距为 10 毫米,微/宏接触之间的中心间距为 5 毫米;PMT Corporation)(图 3b)。该阵列经美国食品药品监督管理局 (FDA) 批准,用于本研究。研究小组成员在参与者同意期间告知他们,额外的接触是为了研究目的。临床护理独自决定参与者(32 个左半球;16 个右半球)的放置位置。解码模型使用除从每个任务中随机选择的 10 次试验之外的所有试验为每个参与者单独训练,从而产生 350 次训练试验和 50 次测试试验。报告的结果仅用于测试数据。我们以 2,048 Hz 的频率从每个电极采样 ECoG 信号,并在处理前将其下采样至 512 Hz。具有伪影(例如,线路噪声、与皮质接触不良、高幅度偏移)的电极被拒绝。具有发作间期和癫痫样活动的电极也被排除在分析之外。从每个单独的电极中减去共同平均参考的平均值(涵盖所有剩余有效电极和时间)。减法之后,希尔伯特变换从原始信号中提取高伽马(70-150 Hz)分量的包络,然后将其下采样至 125 Hz。通过提取训练集中每次试验刺激期之前 250 毫秒的静默期并对这些静默期内的信号取平均值来获得参考信号。每个电极的信号都被标准化为参考均值和方差(即 z 分数)。数据预处理管道使用 MATLAB 和 Python 编码。对于有噪声的语音记录的参与者,我们应用频谱门控通过开源工具48 消除语音中的平稳噪声。我们按照已发表的方法49 排除了我们的神经数据受到最近报道的声学污染的可能性(补充图 5)。为了预训练自动编码器,包括语音编码器和语音合成器,与我们之前在参考文献中的工作不同。 29,完全依赖于无监督训练,我们对一些语音参数进行了监督,以进一步提高其估计精度。具体来说,我们使用 Praat 方法 50 从语音波形中估计音高和四个共振峰频率(fti=1to4,以赫兹为单位)。估计的音高和共振峰频率被重新采样为 125 Hz,与 ECoG 信号和频谱图采样频率相同。语音编码器生成的这些语音参数与 Praat 方法估计的语音参数之间的均方误差被用作监督参考损失,以及无监督频谱图重建和 STOI 损失,使自动编码器的训练成为半监督的
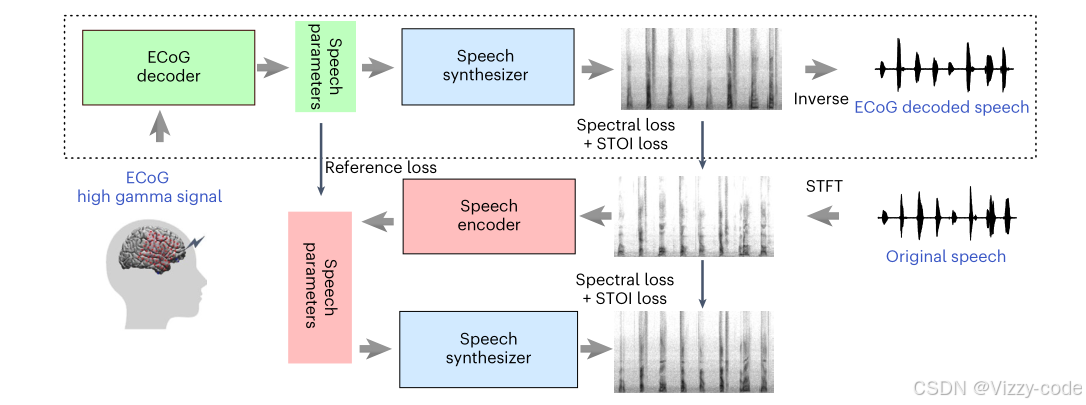
自编码器预训练路径(红色+蓝色)
原始语音 → 语音编码器 → 语音参数 → 语音合成器 → 重建语音
- 输入:原始语音(Original Speech),是参与者实际发出的声音。
- 语音编码器(Speech Encoder):将原始语音编码成“语音参数”(SpeechParameters),这些参数应与ECoG解码器的输出参数一致。
- 语音合成器(Speech Synthesizer):接收这些参数,生成声谱图,再合成出重建语音。
- 损失函数:
- 损失损失+STOI损失(Spectral Loss + STOI Loss):比较重建语音的声谱图与原始语音的声谱图,保证合成语音的质量。STOI(Short-Time Objective Intelligibility)平滑语音的可懂度。
- 参考损失(Reference Loss):用Praat工具从原始语音中提取音高和焦点峰(作为监督信号),与编码器输出器的参数比较,计算均方误差(Mean Square Error, MSE)。
ECoG解码路径(绿色+蓝色)
ECoG信号 → ECoG解码器 → 语音参数 → 语音合成器(固定)→ 解码语音。
- 输入:高伽马ECoG信号(High Gamma ECoG Signal),是来自大脑皮层采集的神经信号(否则提取后的高伽马效应,70-150Hz)。
- ECoG解码器(ECoG Decoder):将ECoG信号转化为“语音参数”(SpeechParameters),这些参数是描述语音特征的中间表示(如音高、焦点峰)。
- 语音合成器(Speech Synthesizer):接收这些参数,生成声谱图(Spectrogram),然后通过逆变换(Inverse)合成出“解码语音”(ECoG Decoded Speech)。
- 损失函数:解码语音与原始语音(Original Speech)之间的差异通过“损失损失+STOI损失”(Spectral Loss + STOI Loss)计算,用于优化ECoG解码器。
参考损失的作用:自编码器预训练生成高质量的“语音参数”,ECoG解码器的参考目标。ECoG解码器通过与这些参数作为对齐来学习。
希尔伯特变换(Hilbert Transform):提取信号包网络,常用于分析频率成分。
高伽马(High Gamma):70-150Hz效应,与大脑活跃状态相关。
STFT(Short-Time Fourier Transform):原始语音通过短时傅里叶变换(STFT)转为声谱图
训练流程的整体逻辑
1. 自编码器预训练(第一阶段):
• 训练语音编码器和语音合成器,生成高质量的参考语音参数。
• 半监督学习:结合Praat的监督信号(音高、焦点峰)和无监督信号(声谱图、STOI)。
• 输出:预训练好的语音合成器(固定)和参考语音参数。
2. ECoG解码器训练(第二阶段):
• 利用预训练的语音合成器,训练ECoG解码器。
• 优化目标:解码语音接近原始语音(通过损失损失和STOI损失)。
• 输出:能够从ECoG信号生成语音的完整解码系统。
语音合成器
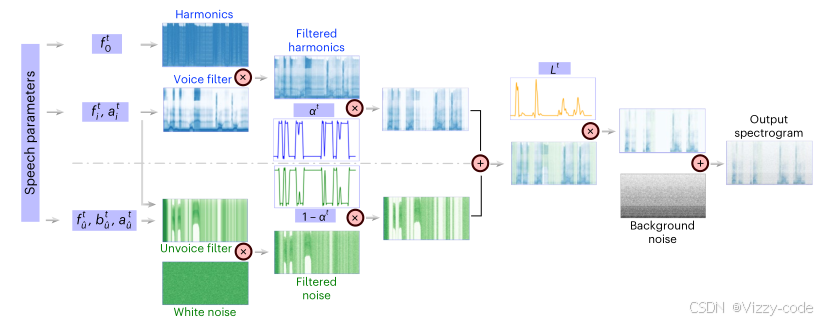

18个语音参数(每时刻 t 的动态参数)
参数化设计:图5展示了如何用少量参数(18个)生成复杂的声谱图。你可以考虑类似的参数化方法来表示你的解码目标(如动作、意图)。
双路径架构:语音和噪声路径的分离设计可以启发你处理多模态信号(比如神经信号中可能有不同类型的活动)。
可视化:图5的频谱图和滤波器可视化可以帮助你理解信号处理过程,建议在你的研究中也用类似方法分析中间结果。

语音通道中的共振峰滤波器



可学习滤波器:原型滤波器 𝐺proto 的可学习性可以启发你设计自适应的信号处理模块。
参数约束:带宽与频率的关系公式可以用于你的神经信号特征提取,减少参数数量。
多滤波器设计:6个共振峰滤波器的组合可以启发你用多个特征提取器处理复杂信号。

无声滤波器


语音激励

噪声激励

共振峰滤波器:使用共振峰滤波器来生成有声成分(voiced component),特别是元音和鼻音的特性
无声滤波器:通过一个宽带滤波器和共振峰滤波器的组合,生成无声成分(如辅音),并考虑了过渡特性。
语音激励:通过谐波信号调制,生成有声成分(如元音)。
噪声激励:使用高斯白噪声,通过无声滤波器生成辅音和摩擦音。
为什么要这样设计:
语音是由声带振动和声道形状共同产生的。人类语音可以分为:
- 有声成分(Voiced Component):如元音(“a”、“e”)和鼻音(“m”、“n”),由声带振动产生,带有周期性(音高)。
- 无声成分(Unvoiced Component):如辅音(“s”、“p”),没有声带振动,更多是噪声(如气流摩擦)。
谐波信号通过共振峰滤波器调制:生成有声成分(元音和鼻音)
通过无声滤波器调制高斯白噪声生成辅音和摩擦音


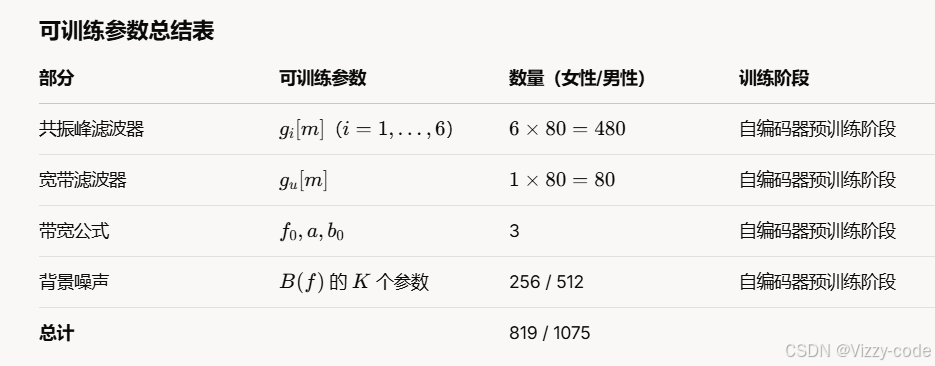
语音参数概要

- 自然模拟:用谐波和白噪声模仿声带(基频)和气流,再用滤波器模拟口腔和风道,贴近人类发声(个体音色)。
- 紧凑高效:18个参数比80个参数少,减少计算量,适合数据少的场景(如ECoG解码)。
- 解耦表示:分开处理基频(音高)和共振峰(音色),方便控制和学习。
- 大脑兼容:参数有物理意义(基频、共振峰),可能反映大脑的控制方式,提升稳健性。

特定于说话者的语音合成参数


语音编码器
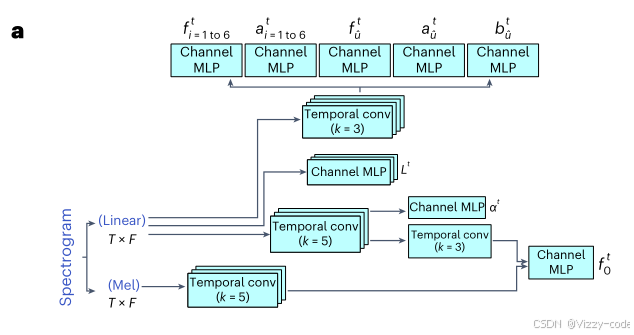

基频 𝑓0𝑡 的提取:
基频是音高(比如高音或低音),编码器从——线性频谱图(直接频率图)和Mel-scale频谱图(人类听觉更敏感的频率图)——中提取特征,结合后得到 。
反归一化:
乘以 𝑓max=8,000 Hz 还原真实频率,归一化到[0, 1],再反归一化,防止参数“失控”,让训练更平稳。
其余17个参数:
- 用时间卷积层:捕捉声音的变化规律。
- 用通道MLP:综合分析不同频率的特征。
这些参数通过卷积和MLP从线性频谱图中推导,控制声音的音色和强度。
借鉴:
- 特征提取:可以用类似卷积+MLP的结构从复杂信号(如神经信号)中提取关键特征。
- 多模态融合:结合不同表示(如线性/Mel频谱图)可能提升解码精度。
- 归一化技巧:限制参数范围([0, 1])可以提高模型稳定性,适用于你的任务。
EoG解码器
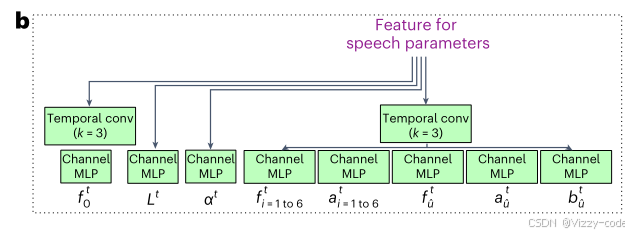
本节介绍三种ECoG解码器的设计细节:3D ResNet ECoG解码器、3D Swin Transformer ECoG解码器和LSTM ECoG解码器。模型使用PyTorch 1.21.1版本在Python中实现。
3D ResNet ECoG解码器
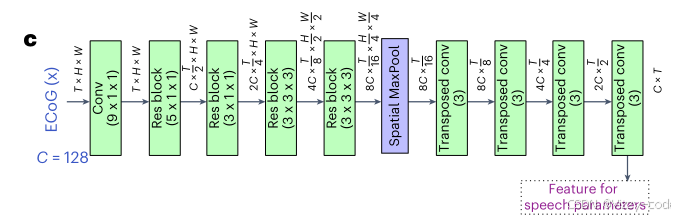
该解码器采用ResNet架构23作为特征提取的核心骨干网络,图6c展示了特征提取部分。模型将ECoG输入视为具有空间-时间维度的3D张量。在第一层,仅对每个电极应用时间卷积,因为ECoG信号在时间维度上的相关性高于空间维度。在解码器的后续部分,我们使用四个残差块(residual blocks)通过3D卷积提取空间-时间特征。在将电极维度下采样到 1×1,时间维度下采样到 T/16 后,我们使用多个转置卷积层(transposed Conv layers)将特征上采样到原始时间维度 T。图6b展示了如何使用不同的时间卷积和通道MLP层从结果特征中生成语音参数。时间卷积操作可以是因果的(仅使用过去和当前样本作为输入)或非因果的(使用过去、当前和未来样本),从而支持因果和非因果模型。
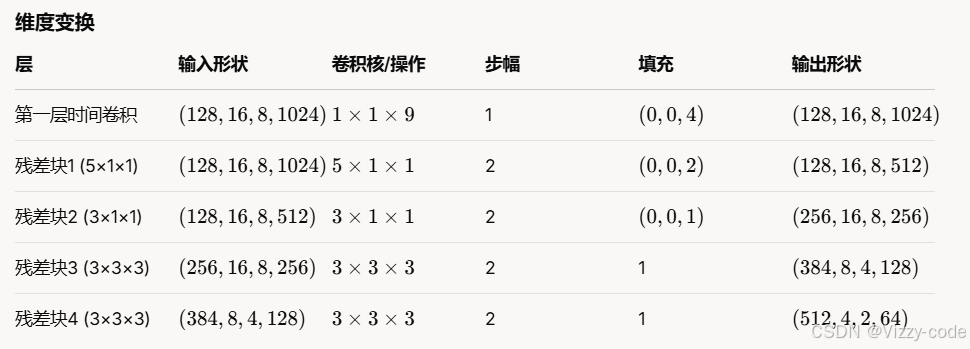
输入:ECoG信号,形状为 (C,H,W,T)
早期层(第一、二块)聚焦时间信息(5×1×1,3×1×1),通道数较小(128→256),提取时间相关特征。
后期层(第三、四块)引入空间信息(3×3×3),通道数更大(384→512),提取时空联合特征。
- ResNet策略:逐步增加通道数是ResNet的常见设计,平衡表达能力与计算量。
- 任务适配:从时间特征(低通道)到时空特征(高通道),适配ECoG特性。
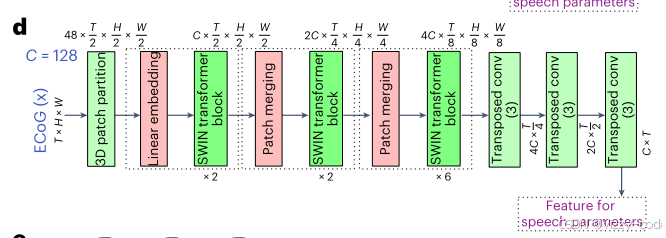
3D Swin Transformer ECoG解码器
Swin Transformer(参考文献24)采用窗口和移窗方法,在每个窗口内对小块(patch)进行自注意力计算。这降低了计算复杂度,并引入了局部性的归纳偏置(?)。由于我们的ECoG输入数据具有三个维度,我们将Swin Transformer扩展到三维,以在时间和空间维度上对3D patch进行局部自注意力。随着模型在更深的Transformer阶段合并相邻patch,每个窗口内的局部注意力逐渐变为全局注意力。
局部性的归纳偏置(Inductive Bias of Locality):假设信号在局部范围内更相关(如ECoG中相邻电极信号更相似),通过窗口机制引入这种假设
Swin Transformer把视频分成小块(窗口),先让每个小块内的“像素”互相交流(局部注意力),降低计算量。随着层数增加,小块合并,交流范围变大,最终覆盖整个视频(全局注意力)。
图6d展示了提出的3D Swin Transformer的整体架构。输入ECoG信号的尺寸为 𝑇×𝐻×𝑊,其中 𝑇 是帧数,𝐻×𝑊 是每帧的电极数量。我们将每个大小为 2×2×2 的3D patch视为3D Swin Transformer中的一个token。3D patch划分层生成 𝑇/2×𝐻/2×𝑊/2 个3D token,每个token具有48维特征。然后,一个线性嵌入层将每个token的特征投影到更高维度 𝐶=128。
- 假设ECoG信号是一个“3D积木”,大小 1024×16×8 1024 \times 16 \times 8 1024×16×8。我们把它切成 2×2×2 2 \times 2 \times 2 2×2×2 的小积木(patch),每个小积木是一个token。切完后有 512×8×4=16384 512 \times 8 \times 4 = 16384 512×8×4=16384 个小积木(token)。每个小积木有48个“描述信息”(48维特征),通过一个“翻译器”(线性嵌入层)把描述信息扩展到128维,方便后续处理。
D Swin Transformer包括多个阶段:对于LD(低难度)参与者,有3个阶段,分别包含2、2和6层;对于HB(高难度)参与者,有4个阶段,分别包含2、2、6和2层。每个阶段的patch合并层执行 2×2×2 的空间和时间下采样。patch合并层将每组 2×2×2 个时间和空间上相邻的token的特征进行拼接,并应用一个线性层将拼接后的特征投影到原始维度的四分之一。
阶段(Stage):Transformer模型的分层结构,每个阶段包含若干层(layer)。
Patch合并(Patch Merging):将相邻的token合并,类似池化操作,降低分辨率。
下采样(Downsampling):减少维度(如时间、空间),降低计算量。
拼接(Concatenate):将多个token的特征向量连接起来(例如 8×𝐶→2𝐶)。
原始维度的四分之一:拼接后维度增大,通过线性层降维
在3D Swin Transformer块中,我们将原始Swin Transformer中的多头自注意力(MSA)模块替换为3D移窗多头自注意力模块,并将其他组件也适配为3D操作。一个Swin Transformer块包括一个基于3D移窗的MSA模块,后面跟着一个前馈网络(FFN,即一个两层MLP)。在每个MSA模块和FFN之前应用层归一化(Layer Normalization),并在每个模块后应用残差连接。
每个Swin Transformer块像一个“加工站”。加工站有两个步骤:第一步是“聊天”(3D移窗自注意力),让小积木(token)在窗口内互相交流,移窗让交流范围更大;第二步是“加工”(FFN),对每个积木的特征进行调整。为了让加工更稳定,先“整理数据”(层归一化),加工后“保留原样”(残差连接),防止信息丢失。


在自注意力操作中的时间注意力可以被限制为因果性(即每个token仅关注其时间上之前的token)或非因果性(即每个token可以关注其时间上之前或之后的token),从而分别形成因果模型和非因果模型。
- 将Swin Transformer扩展到3D,适配ECoG的时空特性,通过窗口和移窗机制降低复杂度,逐步实现局部到全局建模。
- 应用场景:因果模型用于实时BCI,非因果模型用于离线分析。
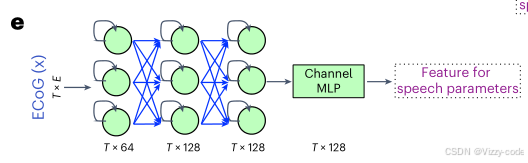
LSTM解码器
该解码器使用LSTM架构(参考文献25)进行图6e中的特征提取。每个LSTM单元由一组控制信息流的门组成:输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。输入门调节新数据进入单元状态(cell state),遗忘门决定从单元状态中丢弃哪些信息,输出门决定哪些信息传递到下一个隐藏状态(hidden state)并可从单元输出。 在LSTM架构中,ECoG输入会按顺序通过这些单元进行处理。对于每个时间步 𝑇,LSTM会接收当前输入 𝑥𝑡 和前一隐藏状态 ℎ𝑡−1,并生成新的隐藏状态 ℎ𝑡 和输出 𝑦𝑡。这一过程使LSTM能够随时间保持信息,对于语音和神经信号处理等任务尤其有用,因为这些任务中时间依赖性至关重要。在这里,我们使用了三层LSTM和一层线性层来生成特征,以映射到语音参数。与3D ResNet和3D Swin不同,我们在所有层中保持时间维度不变。
输入:ECoG信号,形状 𝑇×𝐸,其中 𝐸 是电极数。
三层LSTM:
第一层:𝑇×64,表示每个时间步输出64维特征。
第二层:𝑇×128,特征维度增至128。
第三层:𝑇×128,保持128维。
Channel MLP:多层感知机(MLP),将特征映射到语音参数。
语音编码器和语音合成器的训练
如前所述,我们对语音编码器和语音合成器中的可学习参数进行预训练,以执行语音到语音的自动编码任务。我们使用多个损失项进行训练。修改后的多尺度谱损失(MSS loss)受到参考文献53的启发,并定义为:
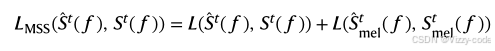
实现重构的频谱图和真实际谱图的差异最小化
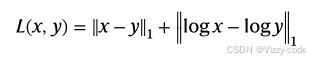
为了提高重构语音的清晰度,我们还通过实现 STOI+ 指标引入了 STOI 损失,STOI+ 是原始 STOI 指标的变体。STOI+ 丢弃了 STOI 中的归一化和裁剪步骤,并且已被证明在清晰度评估指标中表现最佳。首先,通过将离散傅里叶变换 (DFT) 频段分组为 15 个三分之一倍频程频段,进行三分之一倍频程频带分析,最低中心频率设置为 150 Hz,最高中心频率设置为 4.3 kHz。令 x(k,m) 表示真实语音的第 m 帧的第 k 个 DFT 频段。然后,将第 i 个三分之一倍频程频段的范数(称为时频 (TF) 单元)定义为:
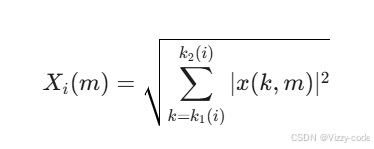


真实和重建声谱图的差异。
重建语音的清晰度(用STOI+衡量)。
音高和共振峰频率的准确性。
调整损失函数中的“权重”(如 𝜆),让程序优先关注清晰度。用不同人的ECoG数据测试程序,根据表现微调模型。
ECoG解码器的训练


第一阶段:预训练编码器和合成器(语音到语音自动编码),固定它们的参数。
第二阶段:训练ECoG解码器,编码器和合成器仅作为“工具”生成参考参数(𝐶𝑗𝑡)和重建声谱图(用于MSS/STOI),但参数不更新。
讨论
我们的新型管道可以通过利用可互换的ECoG解码器架构和一个新颖的可微分语音合成器(图5)从神经信号中解码语音。我们的训练过程依赖于使用预训练的语音编码器(图6a)从参与者的语音中估计指导语音参数。这一策略使我们在有限的对应语音和神经数据下训练ECoG解码器,并与我们的语音合成器配合时能产生自然的声音。我们的方法在参与者(N = 48)中具有高度可重复性,为使用卷积(ResNet;图 6c)和变压器(Swin;图 6d)架构成功进行因果解码提供了证据,这两种架构都优于循环架构(LSTM;图 6e)。我们的框架可以成功地从高空间采样和低空间采样中进行解码,并具有高水平的解码性能。最后,我们提供了右半球稳健语音解码以及皮质结构对半球解码的空间贡献的潜在证据。
我们的解码管道显示了参与者之间的稳健语音解码,导致在多个架构中解码语音和真实语音之间的 PCC 值在 0.62-0.92 范围内(图 2a;因果 ResNet 平均值 0.797,中位数 0.805)。我们将稳定的训练和准确的解码归功于我们精心设计的管道组件(例如,语音合成器和语音参数指导)以及与我们之前在混合密度网格的参与者子集上的方法相比的多项改进(方法部分语音合成器、ECoG 解码器和模型训练)29。之前的报告研究了使用线性模型、过渡概率、循环神经网络、结构神经网络以及其他混合或选择方法的语音或解码。总体而言,我们的结果与许多之前的报告相似(或更好),54%的参与者在解码PCC值高达0.8(图3c)。然而,由于多种文本结构,直接比较是复杂的。之前报告的性能指标、解码的刺激(例如,连续语音与单个单词)、皮层采样(即高密度与低密度、深度电极与表面网格)等方面有所不同。我们公开的管道可用于多种神经网络架构,并可在各种性能指标上进行测试,可以帮助研究社区进行更直接的比较,同时仍保持隐形的语音解码。
解码操作的时间因果性对实时BCI应用至关重要,但大多数先前研究并未考虑这一因素。许多非因果模型依赖于听觉(以及体感)反馈信号。我们的分析表明,非因果模型主要依赖颞上回(STG)的强大贡献,而使用因果模型时这一贡献基本被消除(图4)。我们认为,非因果模型由于过度依赖反馈信号,其对实时BCI应用的可推广性有限,因为这些反馈信号可能缺失(如果不允许延迟)或不正确(如果在实时解码中允许短时延迟)。一些方法使用了想象的语音,这在训练期间避免了反馈,或展示了缺乏听觉反馈的模仿生成的可推广性。然而,大多数报告仍采用非因果模型,这些模型无法排除训练和推理期间的反馈影响。确实,我们的贡献地图显示,非因果ResNet和Swin模型强烈招募了听觉皮层(图4,与其因果对应模型相比,后者基于更多前额叶区域进行解码)。此外,文献中广泛使用的循环神经网络通常是双向的,产生非因果行为,并在实时应用中预测时产生较长的延迟。单向因果结果通常未被报告。我们测试的循环网络在单向训练时表现最差(图2a,因果LSTM)。尽管我们当前的重点不是实时解码,但我们能够从神经信号合成语音,延迟低于50毫秒(补充表1),这提供了最小的听觉延迟干扰,并允许正常的语音产生。我们的数据表明,因果卷积和变换器模型能够与其非因果对应模型表现相当,并招募更相关的皮层结构用于实时解码
在我们的研究中,我们利用了一个中间语音参数空间以及一个新颖的可微分语音合成器来解码特定于参与者的自然语音(图1)。之前的报告使用了不同的方法来建模语音,包括中间运动空间、基于HuBERT特征的声学相关中间空间(来自自监督语音掩码预测任务)、中间随机向量(即GAN)或直接的声谱图表示。我们选择的语音参数作为中间表示,使我们能够解码特定于参与者的声学特性。我们的中间声学表示比直接将ECoG映射到语音声谱图显著提高了语音解码的准确性,也比将ECoG映射到随机向量(随后输入基于GAN的语音合成器)更准确(补充图10)。与运动表示不同,我们的声学中间表示使用语音参数和相关的语音合成器,使我们的解码管道能够生成自然的声音,保留特定于参与者的特性,而这些特性在使用运动表示时会丢失。 我们的语音合成器受到经典声码器模型的启发,用于语音生成(通过将激励源(谐波或噪声)通过滤波器生成语音),并且完全可微分,促进了使用谱损失通过反向传播训练ECoG解码器。此外,训练ECoG解码器所需的指导语音参数可以使用仅需语音数据即可预训练的语音编码器获得。因此,它可以利用患者的旧语音录音或患者选择的代理发言人进行训练(对于无法说话的患者)。然而,使用这种指导训练ECoG解码器需要我们修改当前的训练策略,以克服神经信号与语音信号之间的时间不对齐挑战,这是我们未来工作的范围。此外,低维声学空间和仅使用语音信号的预训练语音编码器(用于生成指导)缓解了训练ECoG到语音解码器的有限数据挑战,并提供了一个高度可解释的潜在空间。最后,我们的解码管道可以泛化到未见过的单词(图2b)。这相较于模式匹配方法提供了优势,后者虽能生成特定于参与者的发音,但泛化能力有限。
许多早期的研究采用了覆盖皮层的髙密度电极,提供了许多不同的神经信号。直接解决的一个问题是较高的密度覆盖是否会改善解码。令人惊讶的是,我们发现即使在低密度和较高(混合)密度网格覆盖下,声谱图PCC的解码性能也很高(图3c)。此外,比较我们在混合密度参与者中使用所有电极与仅使用同一参与者中的低密度电极获得的解码性能,显示解码性能没有显著差异(尽管对于一名参与者例外;图3d)。我们将这些结果归因于我们的ECoG解码器能够从神经信号中提取语音参数,只要有足够的周皮质覆盖,即使在低密度参与者中也是如此。
一个显著的结果是来自右半球皮层结构的稳健解码,以及右周皮质的明确贡献。我们的结果与音节级语音信息双侧表示的观点一致。然而,我们的发现表明,语音信息在右半球中得到了很好的表示。我们的解码结果可以直接用于失语症或言语失用症患者的语音假体。一些先前研究显示了对元音和句子的有限右半球解码。然而,这些结果大多与左半球信号混合。虽然我们的解码结果为右半球中稳健的语音表示提供了证据,但需要注意的是,这些区域很可能不是语音的关键区域,因为少数研究通过电刺激映射探测了两个半球。并且,目前尚不清楚如果左半球受损,右半球是否包含足够的解码语音信息。需要从左半球受损患者那里收集右半球神经数据,以验证我们是否仍能实现可接受的语音解码。然而,我们认为右半球解码仍然是一个令人兴奋的临床目标,适用于因左半球皮层损伤而无法说话的患者。
我们的研究存在几个局限性。首先,我们的解码管道需要与ECoG录音配对的语音训练数据,而这些数据对于瘫痪患者可能不存在。这可以通过使用想象或模仿语音的神经录音以及患者过去的语音录音或患者选择的代理发言人的语音来缓解。如前所述,我们需要修改我们的训练策略,以克服神经信号与语音信号之间的时间不对齐挑战。其次,我们的ECoG解码器模型(3D ResNet和3D Swin)假定基于网格的电极采样,而实际情况可能并非如此。未来的工作应开发能够处理非网格数据的模型架构,例如条带和深度电极(立体脑电图,sEEG)。重要的是,这些解码器可以替代我们当前的基于网格的ECoG解码器,同时仍使用我们的整体管道进行训练。最后,我们在本研究中关注的是单词级解码,词汇量限制在50个单词,这可能无法直接与句子级解码相比。具体来说,最近两项研究在少数长期植入患者的颅内ECoG或Utah阵列上提供了稳健的语音解码,这些研究利用了每项研究中一名患者的大量数据。值得注意的是,这些研究采用了多种方法来约束其神经预测。Metzger等人使用预训练的大型变换器模型,利用定向注意力提供HuBERT特征作为其ECoG解码器的指导。而Willet等人则在音素级别进行解码,并在音素和单词级别使用过渡概率模型来约束解码。我们的研究在数据量方面受到更多限制。然而,我们通过使用紧凑的声学表示(而非学习的上下文信息)在大量患者群体中实现了良好的解码结果。我们期望我们的方法可以帮助提高长期植入患者的泛化能力。
总结而言,我们的神经解码方法能够在48名参与者中解码自然语音,提供了以下主要贡献。首先,我们提出的中间表示使用明确的语音参数和一个新颖的可微分语音合成器,使解码具有可解释性和声学准确性。其次,我们直接考虑了ECoG解码器的因果性,为因果解码提供了强有力的支持,这对实时BCI应用至关重要。第三,我们在使用低采样密度和右半球电极方面取得了有前景的解码结果,为未来使用低密度网格和左半球受损患者的神经假体设备提供了启示。最后但同样重要的是,我们已将我们的解码框架向社区开放并提供文档(https://github.com/flinkerlab/neural_speech_decoding),我们相信这个开放平台将有助于推动该领域向前发展,支持可重复的科学研究。

















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









