






1、什么是onnx模型
ONNX(Open Neural Network Exchange)是一种用于表示深度学习模型的开放标准,它允许不同的深度学习框架和工具之间进行模型交换。ONNX模型具有跨平台的兼容性,可以在不同的硬件和软件上运行,从而提高了模型的部署效率和可移植性。
ONNX模型的主要特点包括:
- 开放性:ONNX是一个开放的标准,由多家技术公司共同维护和发展,确保了模型的广泛兼容性和未来的发展潜力。
- 跨平台兼容性:ONNX模型可以在不同的操作系统和硬件上运行,包括CPU、GPU等,这使得模型部署更加灵活。
- 广泛的工具支持:许多深度学习框架和工具都支持导出和加载ONNX模型,包括Pytorch、TensorFlow等,这使得模型转换变得更加便捷。
此外,ONNX模型还支持模型的优化和推理,通过使用ONNX Runtime等推理引擎,可以进一步提高模型的运行效率。总的来说,ONNX模型是一种高效的深度学习模型交换格式,它简化了模型的部署和推理过程,提高了模型的可用性和性能。
2、yolov5的pt模型转onnx
本文使用yolov5的pt模型进行转化,yolov5的使用非常广泛,我自己平常也会使用yolo去进行一些目标识别。yolov5的export.py可以直接进行onnx模型的转变。 打开export.py程序,修改几个对应参数,点击运行等待转化完成。
--data、--imgsz、--batch-size与训练时参数一致,--weights为需要转化的pt模型。--include设置为onnx。

3、onnx转engine
engine模型为Tensorrt推理使用模型,转化为engine需要搭建环境,请参考深度学习环境配置CUDA、cuDNN、Tensorrt及Anaconda虚拟环境。我这里用的是C++使用Tensorrt的Api。
#include <string>
#include <iostream>
#include <fstream>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include <cassert>
using namespace nvonnxparser;
using namespace nvinfer1;
// 实例化记录器界面。捕获所有警告消息,但忽略信息性消息
class Logger : public ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} gLogger;
//onnx模型转为engine模型
void ONNXToEngine(std::string onnx_path, std::string save_engine_path)
{
//这个函数接收一个Logger对象gLogger作为参数,返回一个IBuilder对象,即推理构建器。
IBuilder* builder = createInferBuilder(gLogger);
//将数字 1(作为 uint32_t 类型)左移
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
//explicitBatch是一个布尔值参数,指示是否显式地在网络中包含批处理维度
INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
//ONNX解析器库来创建一个解析器对象
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
//加载onnx模型
const char* onnx_filename = onnx_path.c_str();
//解析模型,并且只记录警告级别及以上的日志
parser->parseFromFile(onnx_filename, static_cast<int>(Logger::Severity::kWARNING));
//getNbErrors方法返回在解析过程中遇到的错误数量。
for (int i = 0; i < parser->getNbErrors(); ++i)
{
//打印错误信息
std::cout << parser->getError(i)->desc() << std::endl;
}
//成功加载和解析onnx模型
std::cout << "successfully load the onnx model" << std::endl;
//定义最大批次
unsigned int maxBatchSize = 1;
//设置最大批处理大小为
builder->setMaxBatchSize(maxBatchSize);
//创建一个新的配置对象
IBuilderConfig* config = builder->createBuilderConfig();
//设置最大工作空间
config->setMaxWorkspaceSize(1 << 20);
//在构建过程中使用16位浮点数精度
config->setFlag(BuilderFlag::kFP16);
//根据给定的网络(network)和配置(config)构建一个TensorRT引擎(engine)
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
//尝试序列化一个引擎模型。engine->serialize()方法被用来将TensorRT引擎模型转换为可以存储或传输的格式。
IHostMemory* gieModelStream = engine->serialize();
std::ofstream p(save_engine_path, std::ios::binary);
if (!p)
{
std::cerr << "could not open plan output file" << std::endl;
return;
}
//的返回值转换为一个指向const char*类型的指针,该指针指向要写入的数据的起始位置
p.write(reinterpret_cast<const char*>(gieModelStream->data()), gieModelStream->size());
//销毁流,释放内存
gieModelStream->destroy();
std::cout << "successfully generate the trt engine model" << std::endl;
return;
}
int main()
{
ONNXToEngine("E:\\yolov5n.onnx", "E:\\yolov5n.engine");
return 0;
}4、yolov5不同版本的操作
1、yolov5目标识别经常使用版本都是yolov5_5.0或者yolov5_6.0,yolov5_7.0版本加入了实例分割。7.0版本的export.py可以直接从pt转成engine。

2、转换前需要安装Tesnsorrt环境,在Tensorrt的安装包内pip对应python版本。

2、6.0版本的export.py也可以直接转出为engine,但是不要使用,因为这样转出来的engine是有问题的,后续使用Temsorrt去推理会报错。这主要是yolov5里面的问题,所以6.0版本导出onnx再使用上面转换程序。
3、5.0版本只能先转onnx,再用上面转化程序。
5、可能问题
在onnx模型转换为engine模型过程中可能会遇到程序闪退的问题,这是缺少zlibwapi.dll文件。这个文件可以进入 NVIDIA文档官网 点击下载。或者https://download.csdn.net/download/m0_66380820/90371840下载
文件解压后得到
进入dll文件夹
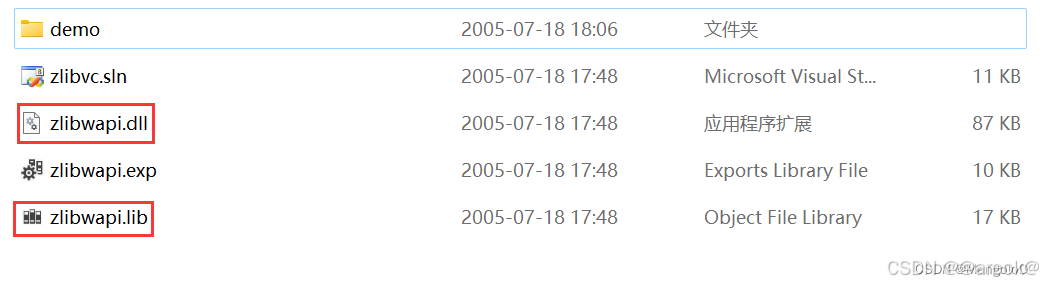
将 zlibwapi.lib 文件放到 path/to/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/lib 下
将 zlibwapi.dll 文件放到 path/to/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/bin 下
为了保险起见,可以将 zlibwapi.lib 文件放到了 path/to/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/lib/x64 下

















 5062
5062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









