







动手实践篇:文档场景信息抽取(PP-ChatOCRv2_doc)模型训练部署实践
前期准备0:在线体验模型方案
🔗效果体验:可以点击链接下载 测试文件,上传至官方文档场景信息抽取应用 体验抽取效果。
✅体验步骤:【上传数据】->【文档解析】->【输入提示词规则】->【对话体验抽取效果】
如体验效果满足需求,可直接点击右上角的「模型产线」进行模型部署。
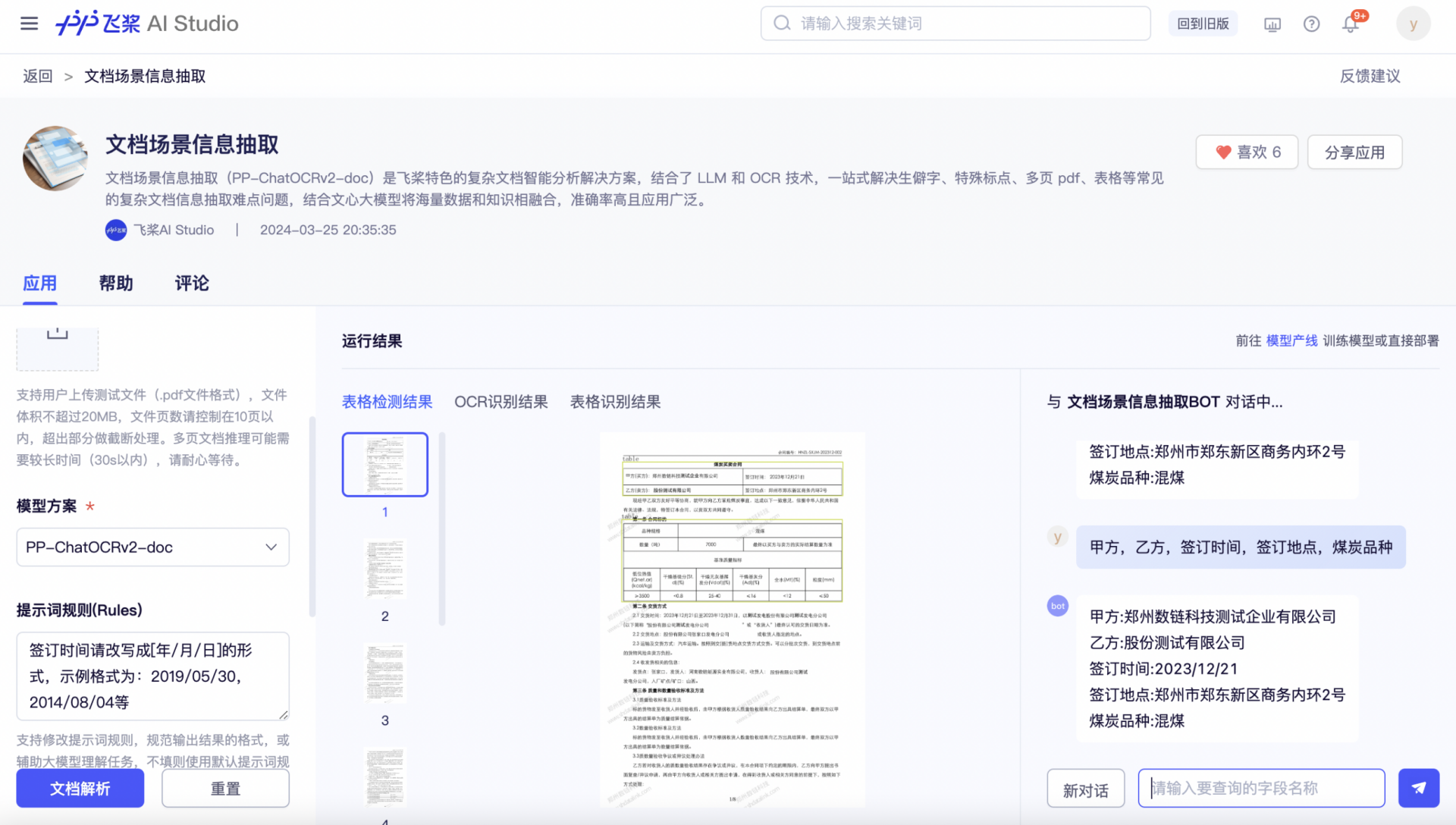
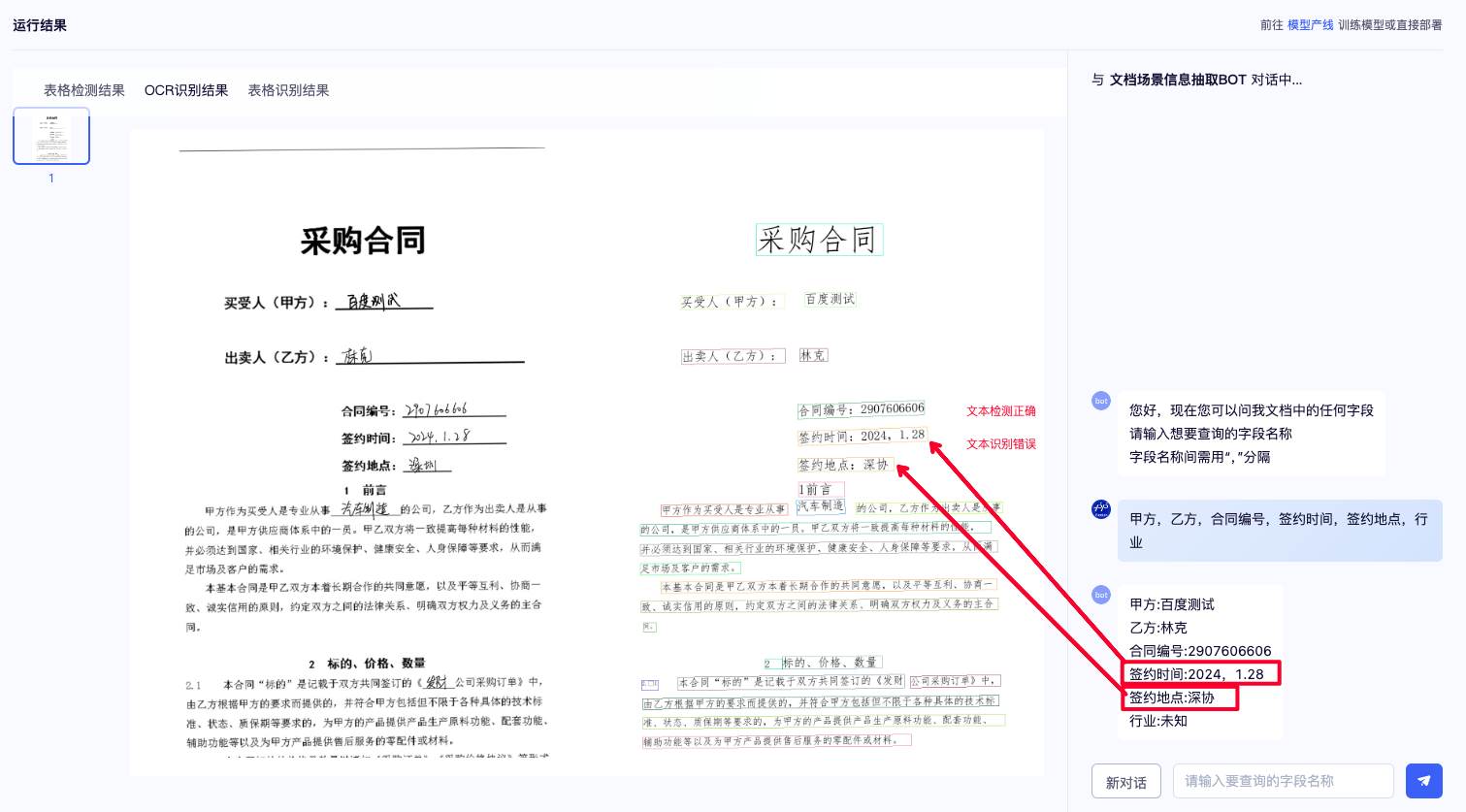
前期准备1:发现问题,定位微调模型
在运行结果部分能够查看「表格检测」「OCR识别」「表格识别」三个小模型结果,方便我们分析 badcase,有针对性的选择需要微调的模型。
通过可视化结果,我们观察到:
1.签约时间和签约地点文字内容被正确检测到,但识别结果并不准确;
2.签约时间希望以[xx年xx月xx日]的格式输出,方便统一管理;
因此本方案选择微调文本识别模型+调整Prompt来提升整体效果。

前期准备2:模型选择
本产线考虑精度和性能的不同需求,提供了 server 和 mobile 两种方案,当 OCR 识别效果无法满足特定场景时,推荐基于自有数据进行模型训练,benchmark 如下:
| 模型 | 检测 Hmean(%) | 识别 Avg Accuracy(%) | GPU 推理耗时(ms) | CPU 推理耗时(ms) | 模型存储大小(M) |
|---|---|---|---|---|---|
| PP-OCRv4_server | 82.69 | 79.20 | 22.20346 | 2662.158 | 198 |
| PP-OCRv4_mobile | 77.79 | 78.20 | 2.719474 | 79.1097 | 15 |
注: 评估集是 PaddleOCR 自建的中文数据集,覆盖街景、网图、文档、手写多个场景,其中文本识别包含 1.1w 张图片,检测包含 500 张图片。GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32,CPU 推理基于 Intel® Xeon® Gold 5117 CPU @ 2.00GHz,线程数为 8,精度类型为 FP32。
可见,在模型精度方面,文本检测 server 相比 mobile 的精度提高 4.9 个百分点,文本识别 server 相比 mobile 的精度提高 1 个百分点。在推理耗时方面,OCR 端到端 GPU 推理耗时 mobile 相比 server 预测速度快约 10 倍以上,CPU 推理耗时 mobile 相比 server 预测速度快约 33 倍。可以结合实际场景需求自行选择。
前期准备3:数据收集与标注
为了微调文本识别模型,基于公开的手写文本识别数据:中科院自动化研究所-手写中文数据集 和开源的印刷文本数据:ICDAR2019-LSVT 和 ICDAR2017-RCTW-17,本教程整理了一个中文手写与印刷文本数据集,包含 30 万个训练样本和 2.9 万个验证样本。PaddleX 已将整理好的数据集,内置到产线的样例数据集中,直接导入使用即可。
数据集目录结构
请按照以下格式准备数据,以确保产线可以正确读取数据集,进行模型训练。
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 存放图像的目录,目录名称可以改变,但要注意和 train.txt val.txt 的内容对应
├── train.txt # 训练集标注文件,文件名称不可改变,内容举例:images/111085122871_0.JPG \t 百度
├── val.txt # 验证集标注文件,文件名称不可改变,内容举例:images/111085122871_0.JPG \t 百度
└── dict.txt # 字典文件,文件名称不可改变。字典文件将所有出现的字符映射为字典的索引,每行为一个单字。
你可以参考:文本识别数据准备说明。
其中数据集目录下必须包含字典文件 dict.txt,如果你没有特殊的要求,我们推荐使用 PP-OCR 默认字典,也可使用脚本 gen_dict.py 根据训练/评估数据自动生成字典:
# 将脚本下载至 {dataset_dir} 目录下
wget https://paddleocr.bj.bcebos.com/script/gen_dict.py
# 执行转化,默认训练集标注文件为"train.txt", 验证集标注文件为"val.txt", 生成的字典文件为"dict.txt"
python gen_dict.py
知识补充
数据收集
训练模型的开源数据收集是一个复杂且关键的过程,它直接决定了模型训练的效果和最终性能。以下提供一些选择开源数据时可以遵循的标准:
- 数据质量的可信度: 选择来自知名机构或研究者发布的开源数据集,这些机构或团队通常具有严格的数据采集和处理流程,能够保证数据的质量和可信度。
- 样本丰富度和多样性: 丰富的样本量和多样性的开源数据集有助于模型更好地泛化到各种场景。因此,在选择开源数据集时,应该保证数据集有足够的规模和多样性,以覆盖不同的情境和条件。
- 数据相关性: 收集的数据应该与你要解决的问题密切相关。比如,如果你在训练一个用于识别猫和狗的图像分类模型,那么你的数据集最好包含大量的猫和狗的照片。
- 数据标注的准确性: 对于需要标注的数据集,应该检查标注的准确性和一致性。同时,还需要关注数据的格式和结构,确保它们与模型训练的要求相匹配。数据标注为了训练出高精度的模型,除了开源数据外,贴近实际场景的真实数据也是为必关键,因此通常需要标注一批真实数据加入训练集。关于 OCR 相关的数据标注可以参考 数据标注指南,该指南将详细指导您如何利用 PaddleLabel 和 PPOCRLabel 工具完成文本识别、文本检测、版面分析等相关单模型的数据标注工作。
尝试

此文档介绍了如何通过PP-ChatOCRv2_doc模型进行文档场景信息抽取的训练与部署实践。用户可通过在线体验模型效果,并根据问题定位和微调模型来提升识别精度。同时,文档提供了数据集的准备、模型选择和部署实践的具体操作指南。
















 8672
8672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}