






本文主要从数据预处理,统计分析、时序分析、空间分析,质量分类等角度去对长江流域环境水质量这一目标进行分析。后面会有详细的代码!
摘要
长江及其支流是许多地区的重要水源,其水质关系到沿途省份居民饮用水和工业灌溉用水的安全问题。由于对环境水质量的时空演变分析可以很好的研究环境水质量变化规律,低检测成本、短耗时的指标开发水质预测分类模型是实现更好的河流水质管理的重要一步。因此文本拟解决以下五个问题:1.长江流域环境水质量的时序规律与时间序列预测方法探究;2.长江流域环境水质量空间分布关系分析;3.基于有限变量的长江流域环境水质量分类评级模型探究;4.长江流域环境水质量敏感因子路径分析;5.环境水质量互联网舆情分析。
首先,我们利用大数据挖掘与爬虫技术,从中国环境监测总站 (cnemc.cn)爬取环境水数据,然后我们对数据进行处理,利用DBSCAN聚类算法提取出所有样本当中的离群值,并清除,得到不错的结果,然后对原始数据进行皮尔逊相关性分析,分析各个变量之间的相关性。
然后,分别从时间和空间两个维度出发,耦合两个维 度结果,完整阐明流域水环境质量演变规律:首先对原始数据进行季节性分解,得到其具有很强的季节性,然后利用SARIMAX与LSTM模型对环境水质量时间序列进行预测分析,发现LSTM模型明显由于SARIMAX,R2达到0.90558,模型良好;然后我们对原始数据进行空间主成分聚类处理,分类出三个类别并可视化,发现南京滁槎、乐山岷江大桥、安庆皖河口、九江河西水厂、扬州三江营、泸州沱江二桥地区的环境水质量属于同一类水质。
随后,利用五个模型RandomForest,SVM(rbf),Adaboost,MLP(adam),Logistics,分别对原始数据构建分类模型,并利用混淆矩阵,ROC曲线,ACU,AUC,MSE,MAPE等指标进行模型的评价,最终对比几个模型的评价指标发现Adaboost的模型最优,分类效果最佳。RF算法次之,由此可见集成算法对环境水质量分析有着良好的作用,明显由于其他的弱分类器。
接着,我们分别从相关性和logistics分类,实际等三个方面对环境水敏感因子路径进行解析,最终发现环境水质量受NH3H与DO这两个指标的影响较大,较为敏感。
关键词:机器学习分类算法;时间序列分析;空间主成分聚类分析;水环境质量;
引言
长江及其支流是许多地区的重要水源,其水质关系到沿途省份居民饮用水和工业灌溉用水的安全问题。而保护的前提是要对流域的水环境状况有完整的理解和认识。然而,现有针对水环境质量的分析存在数据收集不足、分析维度单一等问题,缺乏系统性解析。对环境水质量的时空演变分析可以很好的研究环境水质量变化规律,因此对长江流域环境水质量时空分析具有十分重要的意义。
此外,2017年出台的《城市地表水环境质量排名技术规定(试行)》提出基于《地表水环境质量标准》除水温、粪大肠菌群和总氮以外的21项水质指标构建水质综合指数(City Water Quality Index,CWQI),以便综合反映地表水环境质量状况。该指数为定量评价城市地表水环境质量状况和变化情况的重要指标,涵盖指标全面,为科学管理地表水水质提供了遵循.但此类水质评价方法也面临着需要基础数据种类多、缺少某一项基础数据无法计算指标值的不足。此外,部分水质基础参数存在监测成本昂贵、测试耗时较长的问题,制约着水环境监测的高效率开展。在信息化数据时代大背景下,加大水环境管理力度、提升水环境监测技术的同时,尝试利用低检测成本、短耗时的指标开发水质预测分类模型是实现更好的河流水质管理的重要一步。
目前机器学习方法已广泛应用于环境科学领域,并被证明是水环境研究中挖掘复杂非线性环境质量数据规律的有力工具,如Ho等(2019)应用决策树算法对水质类型进行预测,所构建的最佳预测模型预测精度达84.09%。杨明悦等(2022)应用随机森林模型构建基于变量重要性评分的深圳湾溶解氧预报模型,输入变量为pH值、水温、叶绿素a等水质参数,模型对中短期预测效果良好,并能够预报极端值以达到及时预警效果。
本文拟研究五个问题:1.长江流域环境水质量的时序规律与时间序列预测方法探究;2.长江流域环境水质量空间分布关系分析;3.基于有限变量的长江流域环境水质量分类评级模型探究;4.长江流域环境水质量敏感因子路径分析;5.环境水质量互联网舆情分析。
本文以2016年长江流域水文监测数据为研究对象,通过大数据挖掘网络爬虫技术获取数据,拟基于时间序列分析、空间主成分聚类分析以及众多机器学习模型,深度学习算法耦合起来探究长江流域时空演变分析。此外,本文分别应用多元线性回归、回归决策树、支持向量机、随机森林等机器学习模型,选取监测成本较低的水质参数,包括pH、溶解氧(DO)、高锰酸盐指数指数(CODMn)、氨氮(NH3-N),探讨基于上述4项基础水质指标的CWQI预测模型与敏感因子路径。此外,本文还基于大数据挖掘技术与NLP自然语言情感分析模型对舆情进行分析。
项目流程图如下:

研究区域和数据来源
-
-
研究区域
-
长江发源于青海省的唐古拉山,自西向东横贯中国中部,前后流经青海和湖北等11个省(直辖市),最终在上海市崇明岛附近汇入东海,长江全长约6300千米,长江干流宜昌以上为上游,长4504千米,流域面积约180万平方千米,其中直门达至宜宾称金沙江流域,长3464千米。宜宾至宜昌河段均称川江,长1040千米。宜昌至湖口为中游,长955千米,流域面积68万平方千米。湖口至长江入海口为下游,长938千米,流域面积12万平方千米。地理位置介于北纬24°27′~35°54′,东经90°33′~122°19之间.长江流域现有国控断面648个,共监测319条河流(湖泊).
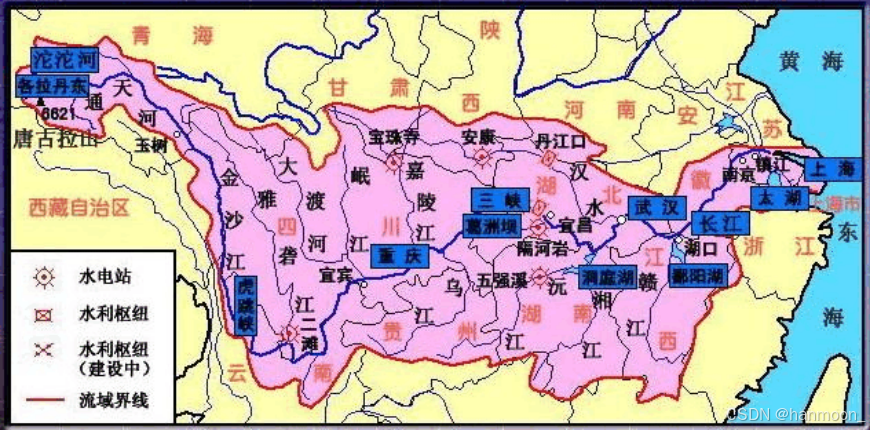
长江流域图
-
-
数据来源
-
水质数据为2016年长江流域的包括pH、溶解氧(DO)、高锰酸盐指数指数(CODMn)、氨氮(NH3-N)的周数据,来源于中国环境监测总站官方网站发布的地表水环境质量周报。(水质自动监测周报-中国环境监测总站 (cnemc.cn))
长江流域环境水质量数据的获取
详细内容请看我的另外一篇博客基于网络爬虫从水环境质量周报中获取水质数据的方法探究_水质数据源-CSDN博客
数据预处理与统计分析
-
-
数据类型处理
-
由于需要进行时间序列预测分析,所以我们以周为一个小周期建立时间序列变量,对同一点位数据按时间顺序进行标记,然后通过数据切片,保留环境水特征数据,将数据保存到data3.xlsx.
又由于需要进行空间主成分聚类分析,所以我们对原始成分进行了切片处理,保留环境水质量数据以及点位名称,保存到主成分.xlsx.
又由于需要进行环境水质量分类,所以我们对原始成分进行了切片处理,保留环境水质量数据,所有环境水特征数据以及点位名称,保存到data.xlsx.
-
-
基于DBSCAN无监督学习的异常离群值处理
-
由于常见的数据输入错误、处理错误、抽样误差等可能的误差导致原始数据或许存在异常值,因此在进行数据分析之前必须先取出异常值。而自然离群点就属于自然问题。
箱线图(Box Plot)是一种用于展示一组数据分散情况及其集中趋势的图形。它由一组数据的最大值、最小值、中位数、及上下四分位数(Q1、Q3)组成。箱线图可以直观地展示数据的分布情况,以及是否存在异常值。在箱线图中,箱体表示数据的集中趋势,线段表示数据的离散程度。因此箱线图是一种非常实用的数据分析工具,可以直观地展示数据的分布情况和离散程度。通过观察箱线图,我们可以快速地了解数据的整体情况和分布特征,以及是否存在异常值。
因此为了检查原始数据是否有异常值,我们采用箱线图初步判断并可视化各自变量的样本分布情况以及异常值,绘制原始数据的箱线图如下:(黄色的点代表异常值)
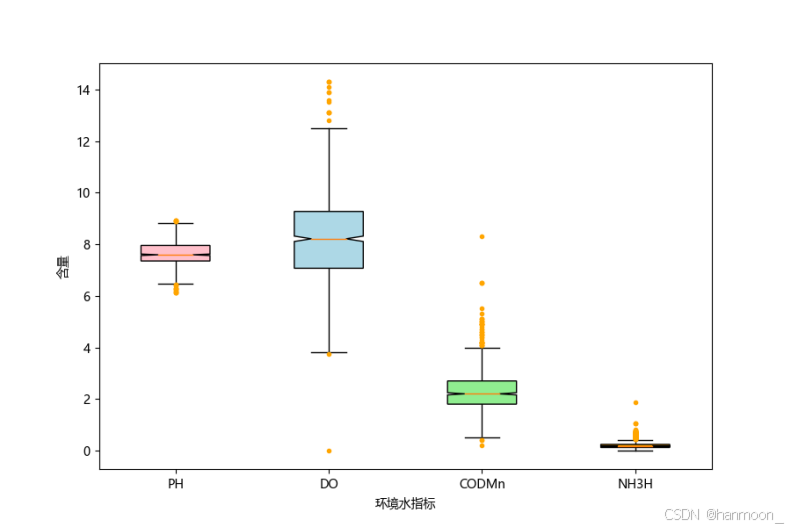
原始数据箱线图
3σ准则是建立在正态分布的。如果一组测量数据中某个测量值的残余误差的绝对值>3σ,则该测量值为坏值,剔除。然而面对很明确的会发现当存在过大的异常点时,那么判定异常点的阈值范围非常大,这样就会造成除非非常异常的数据能剔除,稍微异常数据(亚异常值)有可能都落在这范围内,导致亚异常值根本剔除不掉,方法效率变得极为低下。因此我们提出以下改进方法,从μ前面的系数入手,在计算μ之前我们可以先对数据集进行去极值处理。
利用改进后的3σ原则对各个维度(环境水特征)异常值进行处理,成功去除大部分异常值,绘制处理后箱线图(异常值过滤)如下:
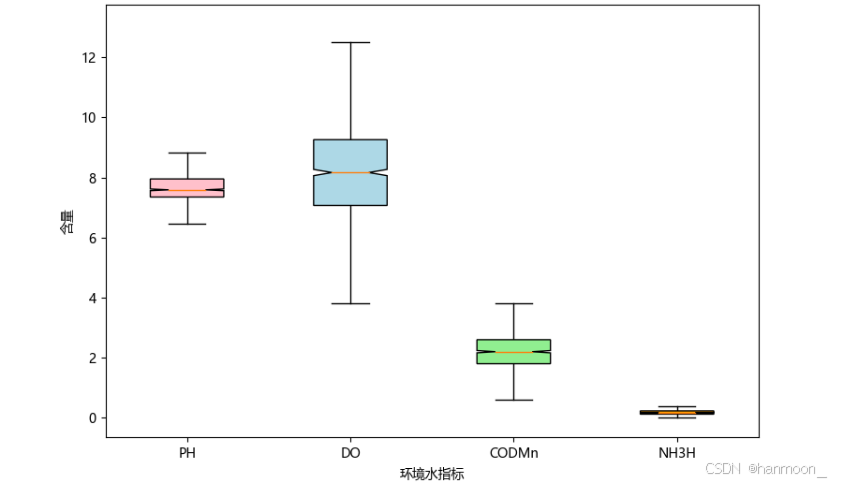
处理后箱线图(异常值过滤)
由图可见异常值均被清除,然而为了探究普遍数据的分类模型,排除一些特殊情况下水环境质量特征变化,构建出具备普遍规律的机器学习分类模型,去除整体离群值具有很大的意义。
DBSCAN无监督学习算法考虑两个主要参数(如下所述)与最近的数据点形成一个集群,并根据高密度或低密度区域检测 Inliers 或 outliers。该算法可以找到多特征整体样本中的离群值,并标记,算法的超参数以及原理如下:
主要参数有两个:(1)eps(本文采用1);(2) min_samples(eps中要考虑的数据点数量,本文采用4)。首先根据主要参数(eps , minPts )找出所有点中的核心点,确定核心点集合为Ω;第二步,再从Ω中,随机选取一个核心点作为对象,找出所有由其密度可达的样本生成聚类簇;重复第二部,在Ω中随机选取未被聚簇过的剩余核心点,持续进行直到所有核心点密度可达的聚类完全被发现;最后剩余的未聚类的点即为离群点,因此用该算法找到并去除样本综合的离群值。
读取数据,建立DBSCAN模型聚类分析,对每一聚类进行进一步分析和描述,并标记出离群点,对原始数据进行可视化,获得部分特征的散点图如下(蓝色点表示离群值):
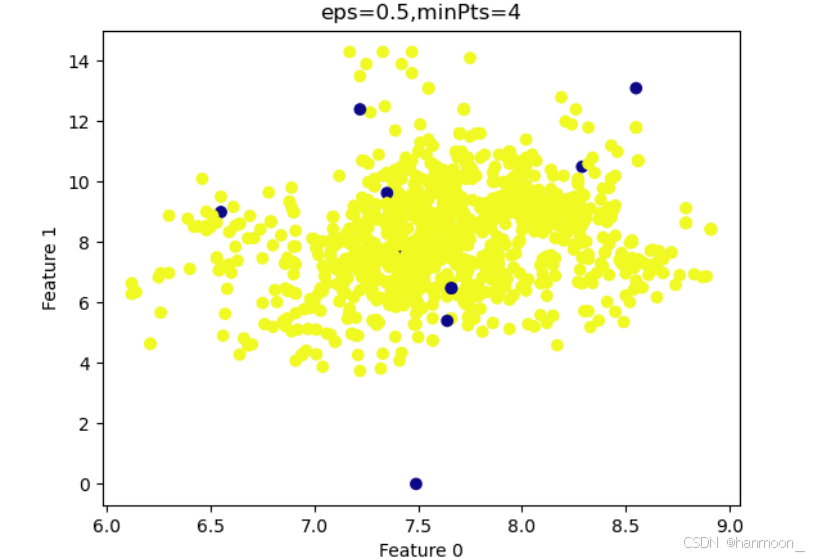
部分特征的散点图
由图可以看出,蓝色的点为离群值,删去所有离群点,并且再次重复聚类操作,判断是否去除所有离群值,最终得到处理后部分特征的散点图如下,可见没有离群值。
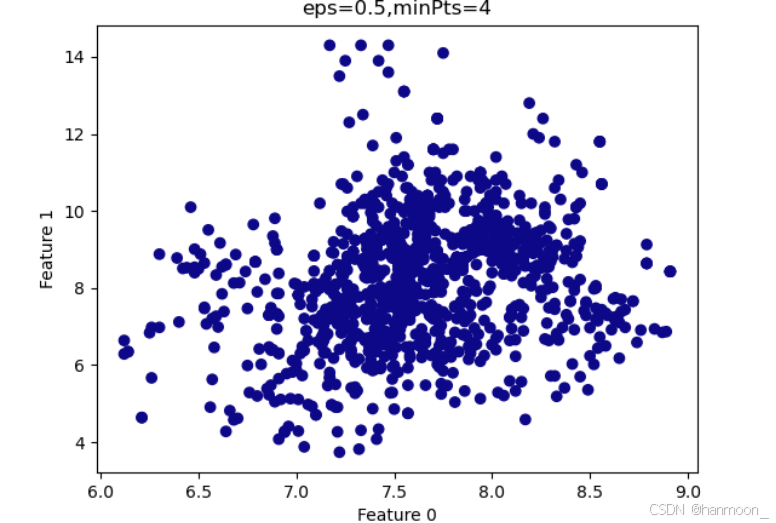
处理后部分特征的散点图
最后将处理后的数据存入data3.xlsx,为后续环境水质量分类模型的构建做铺垫。
-
-
环境水数据的描述性统计
-
描述性统计,是运用制表和分类,图形以及计算概括性数据来描述数据特征的各项活动。描述性统计分析是对数据源最初的认知,包括数据的集中趋势、分散程度以及频数分布等,了解了这些后才能去做进一步的分析。
散点分布矩阵
散点分布矩阵是散点图的高维扩展,它在一定程度上克服了在平面上展示高维数据的困难,在展示多维数据的两两关系时有着不可替代的作用,如下是环境水质量特征的散点分布矩阵图:
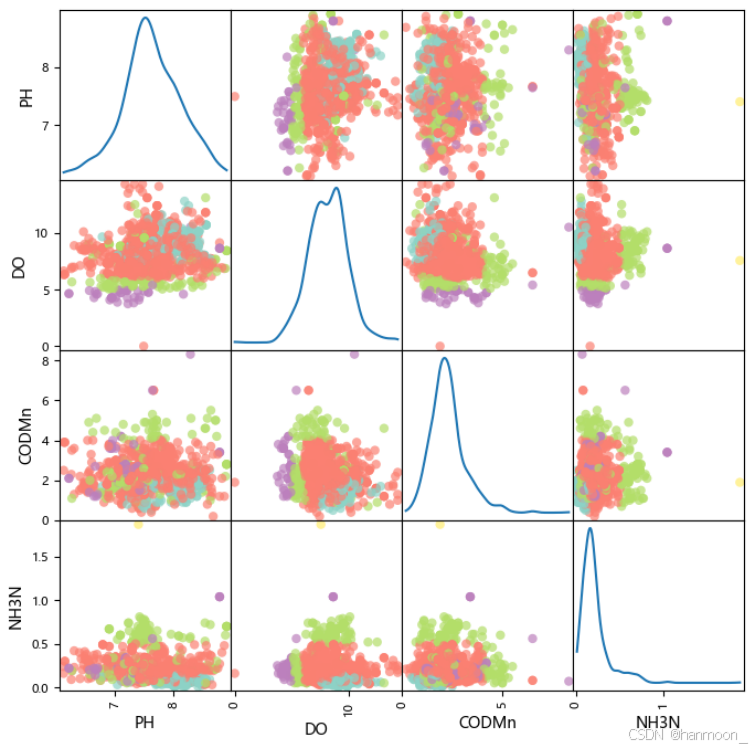
散点分布矩阵
由上图可以看出各个环境水特征变量之间的关系,散点颜色表明每个样本的质量标签,一共有五类,由图也可以看出各个标签之间不够截然,可能是一个非线性的分类问题。
和弦图
和弦图是表示数据之间相互关系的图形方法。节点围绕着圆周分布,点与点之间以弧线彼此连接以显示当中关系,通过每个圆弧的大小比例给每个连接分配数值。此外,还可以通过颜色将数据分类,直观地进行比较和区分。
我们对长江的几个小型点位以及环境水质量数据整合,做出和弦图如下:标记为1,2,3,4的为环境水质量,右侧标记为汉字的是长江各处的部分监测点位。
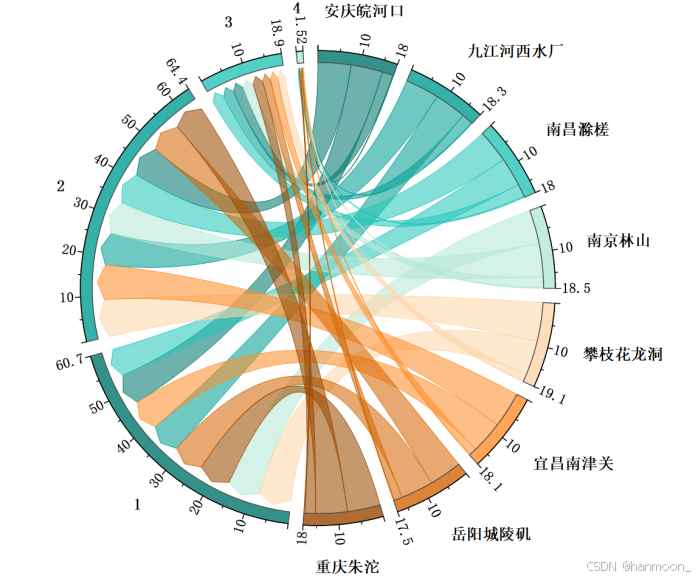
由该图可以看出各点位处环境水质量分布均匀,而这几个点位空间环境水分布不够截然,比较相似,可以多选取几个点例如长江支流点位进行分析。
小提琴图
小提琴图 (Violin Plot)是用来展示多组数据的分布状态以及概率密度。这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。跟箱形图类似,但是在密度层面展示更好。
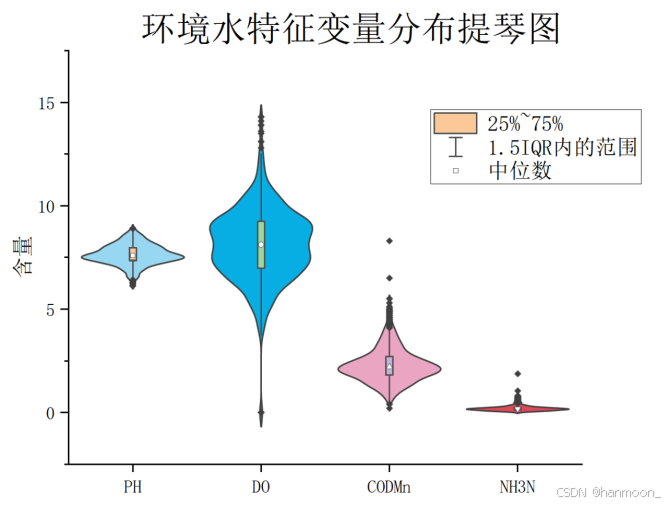
环境水特征变量分布提琴图
环境水数据特征的相关性分析
相关系数是衡量两个数据相关关系的指标,两个数据相关在某种程度上可以帮助人们理解事物的变化规律。又由于上文已经去除异常值,并且变量为连续变量,因此本文可以采用皮尔逊相关系数进行相关性分析,相关性分析热力图绘制如下:
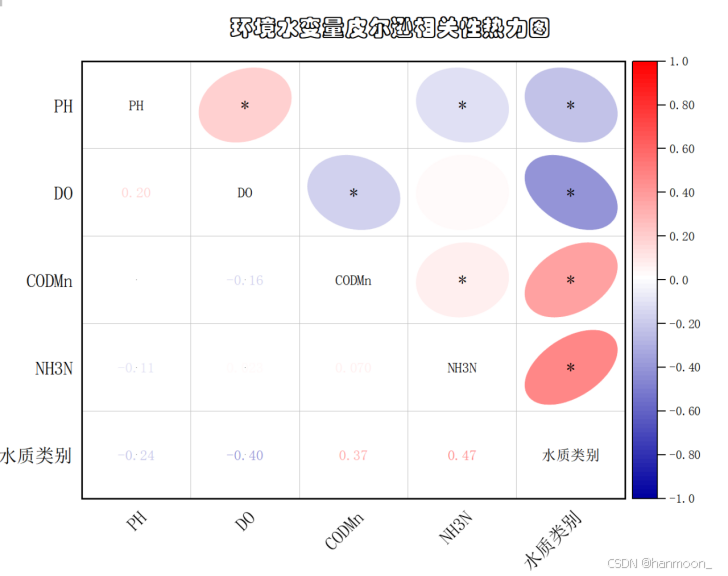
由图可以看出各个变量之间的相关性关系,右上方椭圆中的*代表各个变量之间的显著性程度,可见大部分具有毕竟强的相关性,椭圆的方向代表相关性的正负。
样本数据均衡处理
原始水质等级数据频数具有较大差异,因此由此训练的分类,回归等模型或许会偏向某一变量,针对此问题需采用样本均衡的方法,使个样本的频数一致,从而提高最终模型的泛化性能以及鲁棒性,原始水质等级数据频数饼图如下:
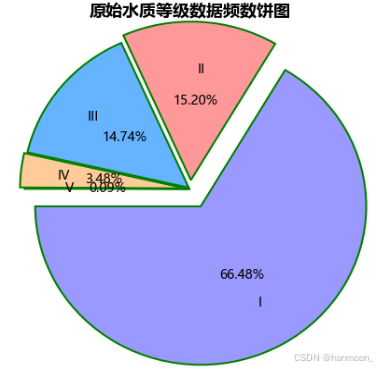
过采样,又称上采样(over-sampling),通过增加分类中少数类样本的数量来实现样本均衡。本文采用随机选取点,扩充数据,来达到上采样这一目的。过采样数据频数统计图如下:
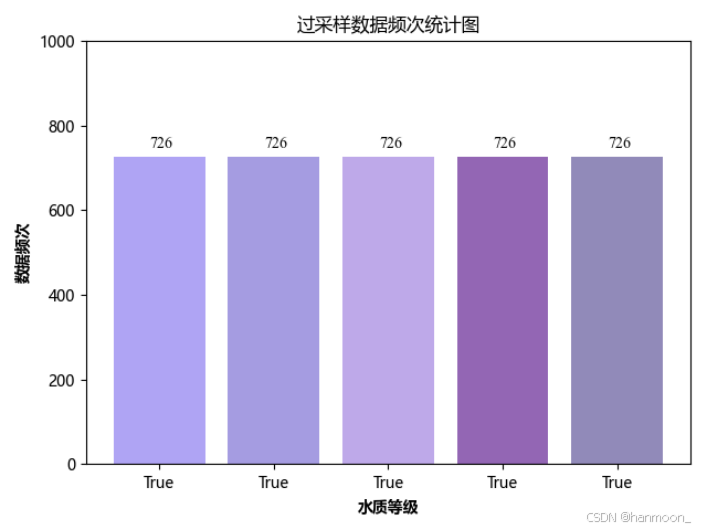
样本数据达到均衡,随之进行下一步的操作。
长江流域环境水质量时序分析与预测
时间序列变量的构建
利用抓取整理得到的长江流域逐年水质,构建评价因子DO数据集,为时一年进行时
序分析,并配合已有文献及政策资料对水环境质量年际演变趋势进行支撑解析。
季节性分解
一般时间序列数据由以下几个方面构成:
(1)长期趋势:是时间序列在长时期呈现出来 的持续向上或持续向下的变动。
(2)季节变动:时间序列数据以一年为周期, 随着季节呈现出反复的有规则的变动趋势。
(3)循环变动:循环变动又称周期变动,是指 时间序列在为期较长的时间内呈现出涨落起伏,且 变动的周期大于一年。
(4)不规则变动:是指现象由偶然因素引起的 无规律的变化。
季节性是指在相同时间周期内不断重复出现的周期性变化。由于本数据为长江流域环境水质量数据,而季节性通常是由自然界在几天和几年内的循环或围绕的日期和时间的社会行为惯例驱动的。因此常理上数据具有周期性的变化,本文先考虑进行季节性分解,观察数据分布状况
本文选取各子流域的评价因子进行季节性分解,将时间序列数据拆分为「季节性」、「趋势性」、「周期性」和「随机性」四个部分的方面,分解结果如下:
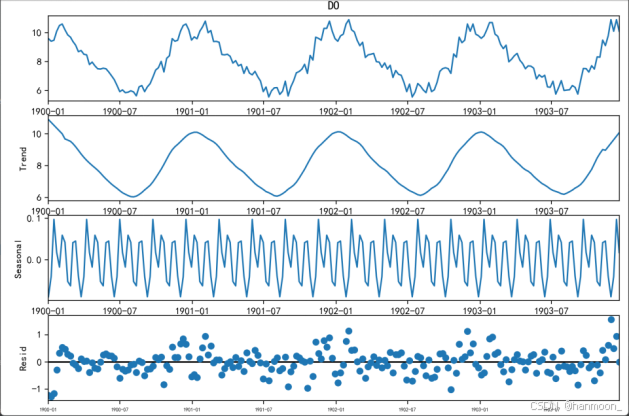
DO季节性分解结果
由上图可以看出特征均具有一定的季节性特点。
SARIMA时间序列预测模型的构建与求解
ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;I为差分,d为使之成为平稳序列所做的差分次数(阶数);MA为"滑动平均",q为滑动平均项数,。ACF自相关系数能决定q的取值,PACF偏自相关系数能够决定q的取值。ARIMA原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
SARIMA是季节性自回归移动平均模型。对于周期性时间序列,首先需要去除周期性,去除的方式是在周期间隔上做一次ARIMA,此时可以得到一个非平稳非周期性的时间序列,然后在此基础之上再一次使用ARIMA进行分析。
ADF平稳性检验
为了确保时间序列预测的准确性,首先对原始品类销售量时间序列数据进行ADF平稳性检验检查原始数据是否具有稳定的分布特征。
对其进行原假设:存在单位根,时间序列是非平稳的,以及备择假设:不存在单位根,时间序列是平稳的不含截距项和趋势项平稳/含截距项平稳/含截距项和趋势平稳。备择假设检验回归式如下:
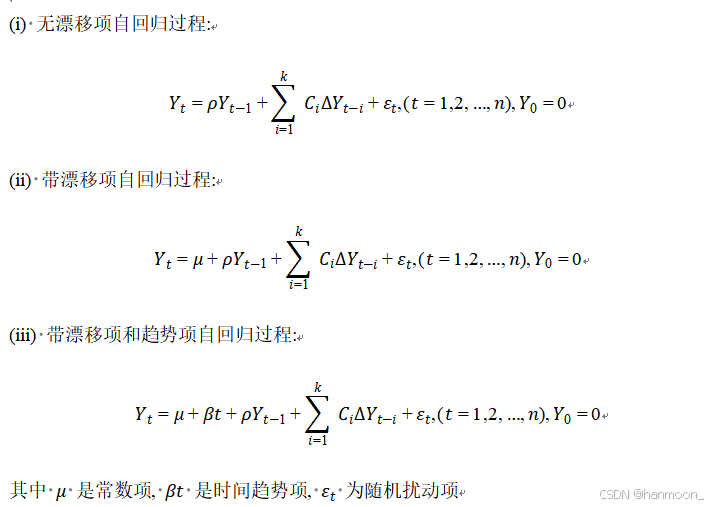
求得原始数据检验统计量大于临界值,不能拒绝原假设,序列是非平稳的,作出原始数据序列,移动平均值以及移动标准差折线图如下。

由上图可以发现处理后数据平稳性良好,可以进行下一步的操作。
基于网格搜索的SARIMAX模型参数优化
SARIMAX模型作为ARIMA模型的季节性扩展模型,对平稳且具有季节性特征的时间序列数据具有较好的预测效果。由于该模型由自回归模型(AR)、移动平均模型(MA)和差分法(I)等模型加以季节性因子(S)结合而成,模型方程如下所示:


内容懒得打字了,我直接把我的报告截图过来
SARIMAX时间序列预测模型的最优参数与诊断结果
选取DO的时间序列数据作为示例,对于差分处理后的DO序列进 行SARIMAX模型拟合,由网格搜索算法迭代多次,找到设置范围内最优的参数组合为SARIMAX(4,1,3)(2, 1, 3, kw),相对最优R方
为0.8108,均方误差MSE为0.8967,AIC为275.5013。
接着对模型进行诊断分析,以确保没有违反模型的假设,分别作出标准残差图、残差的自相关图、正态概率图和正态Q-Q图如下:
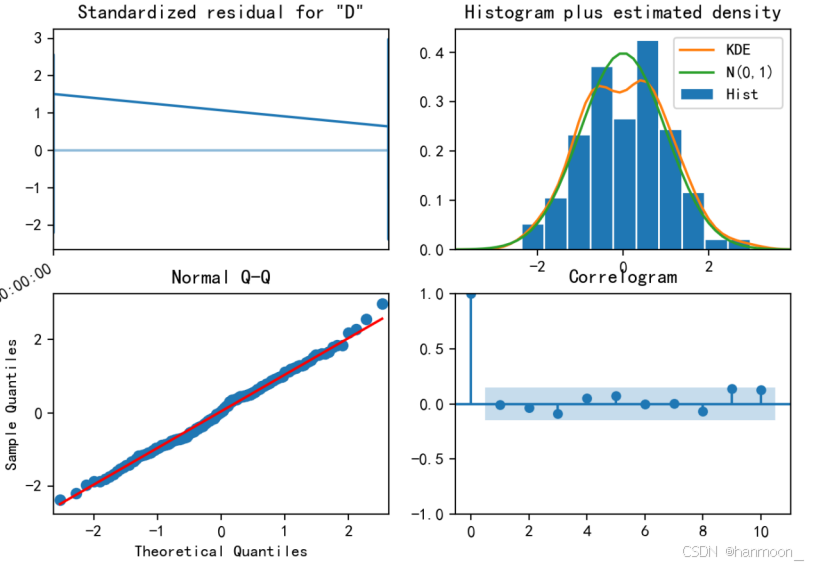
由上图可见标准残差图中标准残差均接近于0,正态概率图和正态Q-Q图中两条线均接近重合,说明残差序列可看作为正态分布,而残差的自相关图可见第一阶差分后残差值均在置信区间之内,不存在明显的自相关性,上述皆说明模型拟合效果较好。
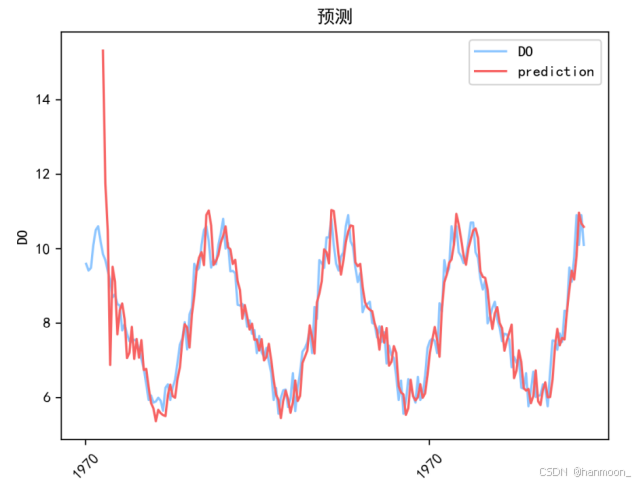
基于SARIMAX模型预测未来环境水质量
拟合出模型后,接着对每日DO进行预测,由上述可知该模型的拟合R方为0.8108,拟合度很高,作出DO的SARIMAX模型原始数据与预测值折线图如下:
LSTM长短期记忆递归神经网络算法的探究与模型构建
LSTM长短期记忆神经网络是在循环神经网络RNN的基础上,通过改进其信息的保存机制,增加遗忘门和细胞状态等方法来保存那些有用的信息并舍弃那些没用的信息,从而使得LSTM能够处理更长序列的数据。LSTM的模型结构主要如下图:(其余的算法原理可以自行搜索)
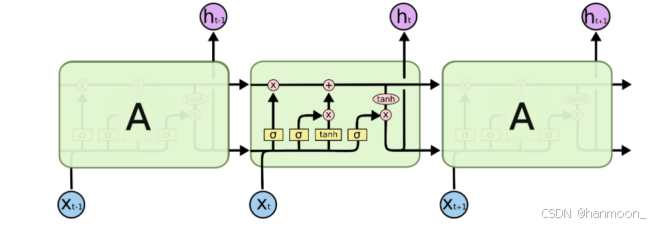
本文利用Sequential()函数构建神经网络,并且对LSTM模型设置参数如下:
| 参数名称 | 具体值 |
| 网络层数 | 3 |
| LSTM层1层数 | 50 |
| 输入时间步特征数 | 1 |
| LSTM层2层数 | 50 |
| 全连接层(输出层)的神经元 | 1 |
| 优化器选取 | adam |
| 损失函数 | mean_squared_error(MSE) |
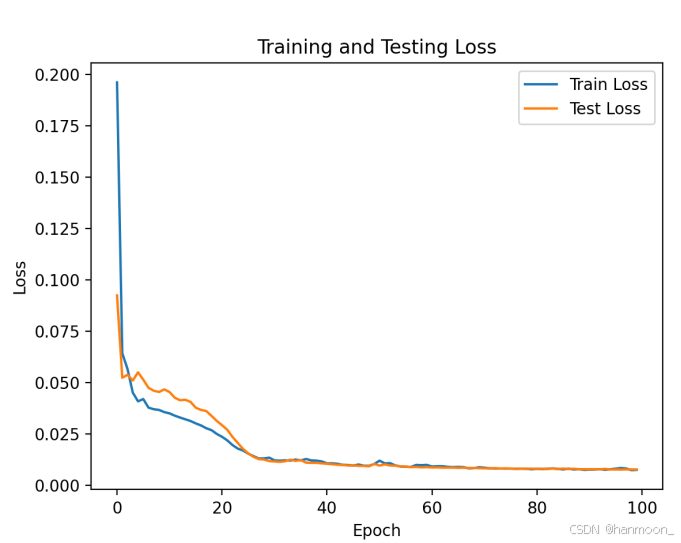
经过100个Epoch的训练,最终损失函数,MAPE与准确率如下:
| 名称 | 具体值 |
| 训练集MAPE(百分比误差) | 4.49897 |
| 测试集MAPE(百分比误差) | 5.00685 |
| 训练集R2 | 0.91252 |
| 测试集R2 | 0.90558 |
损失函数与训练Epoch值之间关系折线图如下:
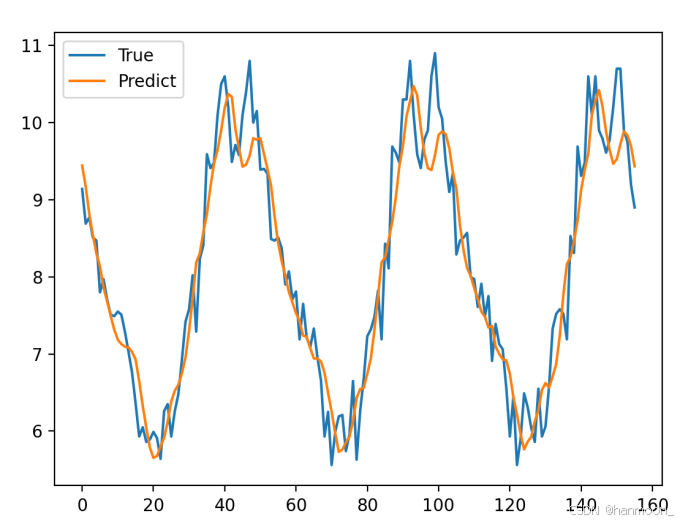
拟合出模型后,接着对每日DO进行预测,由上述可知该模型的拟合R方为0.90558,拟合度很高,作出DO的LSTM模型原始数据与预测值折线图如下:
两种机器学习算法预测效果的对比
SARIMAX(季节性自回归移动平均模型)是一种经典的统计模型,通过对时间序列数据的自回归(AR)、差分(I)和移动平均(MA)组件进行建模来预测未来值。而LSTM是一种循环神经网络(RNN)的变体,通过使用长短期记忆单元(LSTM)来捕捉时间序列数据中的长期依赖关系,适用于处理非平稳和非线性的时间序列数据。两种模型结构上完全不同,以下对两种模型的结果进行对比分析:
| 模型 | 训练集R2 | 训练集MSE |
| SARIMAX | 0.8108 | 0.8967 |
| LSTM | 0.90558 | 0.0073 |
由此可见LSTM对于本问题的解决效果更好。
剩下来的内容后续会更新,请关注我,上述代码如下:
预处理代码
import pandas as pd
from imblearn.over_sampling import RandomOverSampler
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from pandas.plotting import scatter_matrix
from collections import Counter
import matplotlib
from scipy.stats import chi2_contingency
import numpy as np
import seaborn as sns
import mglearn
matplotlib.rc("font",family='Microsoft YaHei')
path = "data.xlsx"
rawdata = pd.read_excel(path)
rawdata = rawdata.dropna(subset=['点位名称']) # 去除空值
rawdata = rawdata.fillna(method='bfill') # 使用后一个有效值填充
# class_encoder = LabelEncoder()
# rawdata['点位名称'] = class_encoder.fit_transform(rawdata['点位名称'].values)
X = rawdata.iloc[:,2:6]
Y = rawdata.iloc[:,6]
# 根据X绘制桑基图
def sankey_plot(X):
fig, ax = plt.subplots()
sankey = mglearn.tools.sankey(ax=ax)
sankey.add(X, label='X')
sankey.finish()
plt.savefig('图/桑基图.png')
plt.show()
sankey_plot(X)
places=[]
for place in rawdata['点位名称'].unique():
place_data = rawdata[rawdata['点位名称']==place]
a,b,c,d = place_data.iloc[:,2:6].mean()
places.append([place,a,b,c,d])
print(places)
pd.DataFrame(places).to_excel('河流均值.xlsx')
'''
# 散点分布矩阵
scatter_matrix(X, alpha=0.7, figsize=(8, 8), diagonal='kde', marker='o', hist_kwds={'bins': 20},c=Y,cmap=plt.cm.Set3)
plt.savefig('图/散点分布矩阵.png')
plt.show()
for col in X.columns:
print('特征: ',col)
print('极差Max-Min: ',X[col].max()-X[col].min())
print('标准差std: ',X[col].std())
print('方差var: ',X[col].var())
# 散点分布图
plt.figure(figsize=(15, 8))
plt.plot(X["PH"], np.zeros(len(X)), ls="", marker="o", ms=10, color="g", label="PH")
plt.plot(X["DO"], np.ones(len(X)), ls="", marker="o", ms=10, color="r", label="DO")
plt.plot(X["CODMn"], 2*np.ones(len(X)), ls="", marker="o", ms=10, color="b", label="CODMn")
plt.plot(X[X.columns[3]], 3*np.ones(len(X)), ls="", marker="o", ms=10, color="y", label="NH3H")
plt.axvline(X["PH"].mean(), ls="--", color="g", label="PH均值")
plt.axvline(X["DO"].mean(), ls="--", color="r", label="DO均值")
plt.axvline(X["CODMn"].mean(), ls="--", color="b", label="CODMn均值")
plt.axvline(X[X.columns[3]].mean(), ls="--", color="y", label="NH3H均值")
plt.legend()
plt.savefig('图/散点分布图.png')
plt.show()
# 欠采样处理
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, Y)
print(sorted(Counter(y_resampled).items()))
print('1',y_resampled)
df=pd.merge(X_resampled,y_resampled,left_index=True,right_index=True)
print(df)
# df.to_excel("data2.xlsx",index=False)
# 绘制箱线图
def box_draw(X,number=1):
# 首先有图(fig),然后有轴(ax)
fig= plt.figure(figsize=(9, 6))
axes = fig.add_subplot()
bplot = axes.boxplot(X,
notch=True,
vert=True,
patch_artist=True,
flierprops ={"markerfacecolor": 'orange', "markersize": 3, "markeredgecolor": 'orange', "alpha": number})
# 颜色填充
colors = ['pink', 'lightblue', 'lightgreen', 'orange']
for patch, color in zip(bplot['boxes'], colors):
patch.set_facecolor(color)
# 加水平网格线
axes.set_xlabel('环境水指标') # 设置x轴名称
axes.set_ylabel('含量') # 设置y轴名称
axes.background_color = 'white'
# 加刻度名称
plt.setp(axes, xticks=[1, 2, 3, 4],
xticklabels=['PH', 'DO', 'CODMn', 'NH3H'])
if number==0:
plt.savefig('图/处理后箱线图(异常值过滤).png')
else:
plt.savefig('图/原始箱线图.png')
plt.show()
box_draw(X)
def choosesigm_prin(df,n=1):###默认sigm前面系数为3
for i in range(df.shape[1]):
tt = df.iloc[:, i]
LS = list(tt)
Max = list(df.max())[i]
Min = list(df.min())[i]
while Max in LS:
LS.remove(Max)
while Min in LS:###处理掉样本中的极值,如果极值重复,一直去除
LS.remove(Min)
m = pd.Series(LS).mean()
s = pd.Series(LS).std()
print('极值取出后均值:%.3f'%m)
print('极值取出后标准差:%.3f'%s)
t1 = m - n * s
t2 = m + n * s
print('\033[1;38m异常值范围在区间[%s,%s]之外\033[0m'%(t1,t2))
fil_S = tt[(tt < t1) | (tt > t2)]###基于数据框做条件筛选,避免for循环出现
print(fil_S)
fil_index = fil_S.index###异常点的横坐标位置
col = df.columns[i]
DF = df[col].drop(list(fil_index), axis=0)###去除异常值后的数据框的均值代替
df[col].loc[fil_index] = DF.mean()
print('\033[1;33m{0:*^80}\033[0m'.format('处理后结果'))
print(df)
box_draw(df,number=0)
choosesigm_prin(X,n=3)
plt.rcParams['font.family'] = ['Microsoft YaHei'] # 设置字体
a=Y.value_counts().sort_index()
print(a)
b=sum(a.values)
plt.pie(Y.value_counts(), # 绘图数据
labels=['I', 'II', 'III', 'IV', 'V'], # 绘图标签
explode=[a[1]/b,a[2]/(b*10),a[3]/(b*10),a[4]/b,a[5]/b], # 指定饼图某些部分的突出显示,即呈现爆炸式
colors=['#9999ff', '#ff9999', '#66b3ff', '#ffcc99', '#99ccff'],
autopct='%.2f%%', # 设置百分比的格式,这里保留两位小数
pctdistance=0.5, # 设置百分比标签与圆心的距离
labeldistance=0.7, # 设置标签与圆心的距离
startangle=180, # 设置饼图的初始角度
radius=1.2, # 设置饼图的半径
wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize':10, 'color':'black'}, # 设置文本标签的属性值
)
plt.title("原始水质等级数据频数饼图", fontsize=13, weight='bold')
plt.savefig('图/原始水质等级数据频数饼图.png')
plt.show()
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()+rect.get_width()/2.-0.08, 1.03*height, '%s' % int(height), size=10, family="Times new roman")
water_data=df.iloc[:,-1].value_counts()
cm=plt.bar(water_data.index,water_data.values,color=['slateblue','darkslateblue','mediumslateblue','mediumpurple','indigo']
,alpha=0.6,tick_label=True) #指定不同颜色并设置透明度
autolabel(cm)
plt.ylim(0,1000)
plt.xlabel('水质等级',fontsize=10,weight='bold')
plt.ylabel('数据频次',fontsize=10,weight='bold')
plt.title('过采样数据频次统计图',fontsize=12)
plt.tight_layout()
plt.savefig('图/过采样数据频次统计图.png')
plt.show()
# 设置绘图风格
df=pd.read_excel("data.xlsx")
# 使用向前填充方法填充缺失值
df = df.fillna(method="ffill")
# 计算相关性 皮尔逊相关
corr = np.corrcoef(df.iloc[:,2:7], rowvar=False)
print(df.iloc[:,2:7])
print(corr)
mask = np.zeros_like(corr)
#将mask的对角线及以上设置为True
#这部分就是对应要被遮掉的部分mask[np.triu_indices_from(mask)] = True
with sns.axes_style("white"):
sns.heatmap(corr, mask=mask, vmax=0.3, annot=True,cmap="RdBu_r")
plt.title("Heatmap of all the Features", fontsize=15)
plt.savefig('图/热力图1.png')
plt.show()
'''
# 设置绘图风格
sns.set_style('whitegrid')
# 设置画板尺寸
df=rawdata.iloc[:,2:7]
print(df)
rc = {'font.sans-serif': 'SimHei',
'axes.unicode_minus': False}
# 画热力图
# 为上三角矩阵生成掩码
mask = np.zeros_like(df.corr(), dtype=np.bool_)
mask[np.triu_indices_from(mask)] = True
sns.set(rc=rc)
sns.heatmap(df.corr(),
cmap=sns.diverging_palette(20, 220, n=200),
mask=mask, # 数据显示在mask为False的单元格中
annot=True, # 注入数据
center=0, # 绘制有色数据时将色彩映射居中的值
)
# Give title.
plt.title("Heatmap of all the Features", fontsize=15)
plt.savefig('图/热力图.png')
plt.show()
离群值分析算法
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import numpy as np
path = "data.xlsx"
rawdata = pd.read_excel(path)
rawdata = rawdata.dropna(subset=['点位名称']) # 去除空值
rawdata = rawdata.fillna(method='bfill') # 使用后一个有效值填充
X = rawdata.iloc[:,2:6]
y = rawdata.iloc[:,6]
# 绘制延伸图
plt.scatter(X.iloc[:,0],X.iloc[:,1])
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
# dbscan聚类算法 按照经验MinPts=2*ndims,因此我们设置MinPts=4。
dbscan= DBSCAN(eps=1,
min_samples=4)
clusters = dbscan.fit_predict(X)
def cm_scatter(X, clusters):
# dbscan聚类结果
plt.scatter(X.iloc[:, 0], X.iloc[:, 1],
c=clusters,
cmap="plasma")
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.title("eps=0.5,minPts=4")
plt.show()
print(X.value_counts())
cm_scatter(X, clusters)
# 使用enumerate()函数找到值为1的下标
indexes = [i for i, x in enumerate(clusters) if x != 0]
print(indexes)
XL=X.drop(indexes)
print(XL.value_counts())
clustersL = dbscan.fit_predict(XL)
cm_scatter(XL, clustersL)
indexes = [i for i, x in enumerate(clustersL) if x != 0]
print(indexes)
XL.to_excel("data3_去异常值.xlsx")时序分析算法
import pandas as pd
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
from statsmodels.tsa.stattools import adfuller #Dickey-Fuller test
from pmdarima import auto_arima
from sklearn.metrics import mean_squared_error # 差分
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # 作ACF,PACF图
import statsmodels.api as sm
import statsmodels.tsa.stattools as ts
import joblib
from keras.models import Sequential
from keras.layers import LSTM, Dense
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from sklearn.metrics import r2_score
plt.rcParams['font.sans-serif'] = ['SimHei'] # 例如设置为'SimHei'字体
plt.rcParams['axes.unicode_minus'] = False # 设置是否使用 Unicode 减号字符,如果设置为False,则使用 ASCII 减号
# 1. 读取数据
data = pd.read_excel("安庆皖河口.xlsx")
# 2. 数据预处理
# 转换日期列为 datetime 类型
data["期"] = pd.to_datetime(data["期"],format='%Y-%m-%d')
# print(data["期"])
# 设置日期列为索引
data.set_index("期", inplace=True)
# 构建时间序列数据
lines = {'DO'}
print(1)
# 数据平稳性检测 因为只有平稳数据才能做时间序列分析
def judge_stationarity(data_sanya_one):
dftest = ts.adfuller(data_sanya_one)
print(dftest)
dfoutput = pd.Series(dftest[0:4],
index=['Test Statistic', 'p-value', '#Lags Used', 'Number of Observations Used'])
stationarity = 0
for key, value in dftest[4].items():
dfoutput['Critical Value (%s)' % key] = value
if dftest[0] > value:
stationarity = 1
print(dfoutput)
print("是否平稳(1/0): %d" % (stationarity))
return stationarity
def test_stationarity(timeseries):
#Determing rolling statistics
rolmean = timeseries.rolling(7).mean()
rolstd = timeseries.rolling(7).std()
#Plot rolling statistics:
fig = plt.figure(figsize=(12, 8))
orig = plt.plot(timeseries, color='#4F9FC7',label='Original')
mean = plt.plot(rolmean, color='#F08080', label='Rolling Mean')
std = plt.plot(rolstd, color='#2F3A59', label = 'Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show()
#Perform Dickey-Fuller test:
print('Results of Dickey-Fuller Test:')
dftest = adfuller(timeseries, autolag='AIC') #autolag : {‘AIC’, ‘BIC’, ‘t-stat’, None}
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
stationarity=1
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
if dftest[0] > value:
stationarity = 0
print(dfoutput)
print("是否平稳(1/0): %d" % (stationarity))
return stationarity
def visualization(pdd,color): # 可视化函数
plt.rcParams['font.family'] = ['Microsoft YaHei'] # 设置字体
'''
# 一阶差分
df2 = pdd.diff().dropna()
df2.columns = [u'一阶差分']
# 时序图
df2.plot()
plt.show()
#画ACF图,PACF图来确定p、q值
ax1 = plt.subplot(211)
plot_acf(pdd,ax=ax1) #lags 表示滞后的阶数,值为30,显示30阶的图像
ax2 = plt.subplot(212)
plot_pacf(pdd,ax=ax2,lags=6)
plt.subplots_adjust(hspace=0.5)
plt.show()
'''
# 做出预测模型
plt.plot(pdd, label=line, color=color)
# 设置图表标题、坐标轴标签和图例
plt.title("预测")
plt.xlabel("日期")
plt.ylabel(line)
plt.legend()
# 自动旋转x轴日期,以便阅读
# plt.xticks(rotation=45)
# 显示图表
plt.show()
# 保存
# plt.savefig(line+'.jpg', dpi=1000)
def sarimax(pdd):
''''''
''''''
# 网格搜索sarimax模型参数优化
'''
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
for param in pdq:
for param_seasonal in seasonal_pdq:
'''
kw=7
# SARIMAX算法函数参数说明(order:非季节性p,d,q,seasonal_order:季节性p,d,q,周期)
arima_model = sm.tsa.statespace.SARIMAX(pdd,
order=(4,1,3),
seasonal_order=(2, 1, 3, kw),
enforce_stationarity=False,suppress_warnings=True,
enforce_invertibility=False)
arima_model = arima_model.fit()
# print(arima_model.summary().tables[1])
arima_model.plot_diagnostics(figsize=(8, 6))
plt.show()
# 预测
pred = arima_model.predict(kw)
# print(pred)
# 保存预测结果
predictions[line] = pd.Series(pred)
# print(f"Line {line} prediction:")
# print(predictions[line])
df = pd.DataFrame({0: pred})
# 将df1视为预测值,df2视为真实值
y_true = pdd.values[kw:len(pred)+kw]
y_pred = df.values
# 计算R方值
r2 = r2_score(y_true, y_pred)
print("R2:", r2)
plt.plot(pdd, label=line, color="#8dc6ff")
plt.plot(df, color="#f76262",label='prediction')
# 设置图表标题、坐标轴标签和图例
plt.title("预测")
plt.xlabel("日期")
plt.ylabel(line)
plt.legend()
# 自动旋转x轴日期,以便阅读
plt.xticks(rotation=45)
# 显示图表
plt.show()
# plt.savefig(line+'00.jpg', dpi=1000)
print('MSE:{} AIC:{}'.format(arima_model.mse, arima_model.aic))
return "SARIMAX"
# 3. 训练和预测
predictions = {}
for line in lines:
group = data[line]
# 使用向前填充方法填充缺失值
group = group.fillna(method="ffill")
# 平稳性测试
# test_stationarity(group)
lab = sarimax(group)
# 输出指定线路的预测结果
forcast=pd.DataFrame.from_dict(predictions, orient='columns', dtype=None, columns=None)
forcast.tail(2).to_excel("算法forcast_49.xlsx")
print(4)
# 加载数据
rawdata = pd.read_excel('注册制公司21-22股价数据.xlsx')
rawdata.set_index('日期', inplace=True)
# for column in rawdata.columns:
# rawdata[column] = np.log(rawdata[column] / rawdata[column].shift(1))
rawdata = rawdata.fillna(method='bfill') # 使用后一个有效值填充
columns = rawdata.columns
print(rawdata)
rawdata.to_excel('data_股价.xlsx', index=True)
for column in columns:
rawdata_ = rawdata[column].values.reshape(-1, 1) # 将数据转换为二维数组
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(rawdata_)
# 划分训练集和测试集
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size, :]
test_data = scaled_data[train_size:, :]
# 创建时间窗口
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset) - look_back):
X.append(dataset[i:i + look_back, 0])
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 7 # 时间窗口大小
train_X, train_Y = create_dataset(train_data, look_back)
test_X, test_Y = create_dataset(test_data, look_back)
# 调整输入数据的形状
train_X = np.reshape(train_X, (train_X.shape[0], train_X.shape[1], 1))
test_X = np.reshape(test_X, (test_X.shape[0], test_X.shape[1], 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(look_back, 1)))
model.add(LSTM(units=50))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
# 训练模型
history = model.fit(train_X, train_Y, validation_data=(test_X, test_Y), epochs=100, batch_size=32)
# 绘制训练损失和测试损失曲线
train_loss = history.history['loss']
test_loss = history.history['val_loss']
plt.plot(train_loss, label='Train Loss')
plt.plot(test_loss, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Testing Loss')
plt.legend()
plt.show()
# 预测
# test_p=[]
train_predict = model.predict(train_X)
test_predict = model.predict(test_X)
# 反归一化
train_predict = scaler.inverse_transform(train_predict)
train_Y = scaler.inverse_transform([train_Y])
test_predict = scaler.inverse_transform(test_predict)
test_Y = scaler.inverse_transform([test_Y])
# test_p = scaler.inverse_transform([test_p])
# 计算平均绝对百分比误差
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
print('训练集MAPE:', mean_absolute_percentage_error(train_Y[0], train_predict[:, 0]))
print('测试集MAPE:', mean_absolute_percentage_error(test_Y[0], test_predict[:, 0]))
print('训练集R2:', r2_score(train_Y[0], train_predict[:, 0]))
print('测试集R2:', r2_score(test_Y[0], test_predict[:, 0]))
plt.plot(test_Y[0], label='True')
plt.plot(test_predict[:, 0], label='Predict')
plt.legend()
plt.show()
这是我本科阶段的一个大作业,为了将开源出来供大家学习。文章为本人原创,如需转载请私信。


















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









