






摘要:生成与认知对齐的分层SVG仍然是一项挑战,因为现有方法往往倾向于要么输出过于简化的单层结果,要么因优化过程导致形状冗余。我们提出了LayerTracer,这是一个基于扩散变换器的框架,它通过从一个包含顺序设计操作的新型数据集中学习设计师创建分层SVG的过程,从而填补了这一空白。我们的方法分为两个阶段:首先,一个文本条件化的DiT(双向变换器)生成多阶段的栅格化构建蓝图,模拟人类设计工作流程。其次,通过路径去重的逐层矢量化过程,生成干净、可编辑的SVG。在图像矢量化方面,我们引入了一种条件扩散机制,将参考图像编码为潜在令牌,指导分层重建的同时保持结构完整性。大量实验表明,LayerTracer在生成质量和可编辑性方面均优于基于优化的方法和神经基线方法,有效地使AI生成的矢量图与专业设计认知相一致。Huggingface链接:Paper page,论文链接:2502.01105
1. 引言
背景与动机:
- SVG的重要性:可缩放矢量图形(SVG)作为现代数字设计的基石,通过数学方程而非像素网格定义视觉元素(如路径、曲线和几何形状),具有分辨率无关的清晰度,适用于从UI/UX设计到工业CAD系统等对精度要求较高的应用。
- 分层SVG的优势:分层SVG遵循专业标准,允许设计师精细地操作各个图层以优化笔触纹理、空间层次和复合效果,是现代设计工作流程中动态调整和协作迭代的基础。
- 现有方法的局限性:然而,当前的深度学习基于SVG生成技术仍与专业要求存在显著差距。现有方法面临三大系统性挑战:缺乏大规模分层SVG数据集、方法碎片化以及忽视设计师的认知过程。
研究目标:
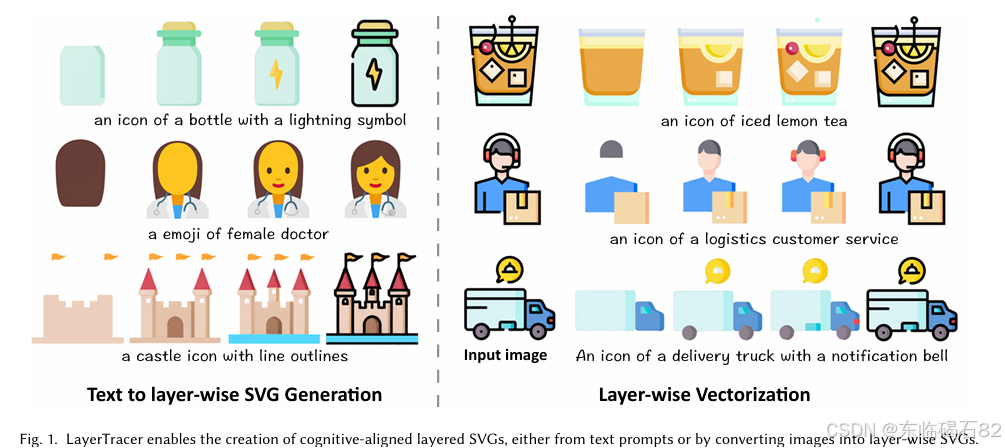
- LayerTracer的提出:为了应对这些挑战,本文提出了LayerTracer,一个基于扩散变换器(DiT)的框架,它通过模拟设计师的分层SVG创建过程,实现了与认知对齐的分层SVG合成。
2. 相关工作
文本到图像扩散模型:
- 扩散模型的发展:近年来,扩散模型在生成高质量合成图像方面展现出了强大的能力,有效平衡了多样性和保真度。
- Stable Diffusion等模型:基于潜在扩散模型的Stable Diffusion通过UNet框架将文本条件融入其中,成为图像生成的主流模型。此外,LoRA和DreamBooth等技术通过微调预训练图像生成模型,增强了其对特定应用场景的适应性。
SVG生成:
- 传统方法:SVG生成通常涉及训练神经网络以产生预定义的SVG命令和属性,使用RNN、VAE和Transformer等架构。然而,由于缺乏大规模矢量数据集,这些方法在泛化能力和复杂图形创建方面受到限制。
- 基于优化的方法:另一种方法是使用可微分的栅格化器在评估阶段优化SVG参数以匹配目标图像,如CLIPDraw、CLIPasso和CLIPVG等。这些方法虽然取得了显著成果,但仍面临挑战。
3. 方法论
总体架构:
- LayerTracer的组件:LayerTracer由以下组件组成:蛇形数据集构建、逐层模型训练、Image2Layers模型和逐层矢量化。首先,通过收集设计师创建分层矢量图形的过程,并将其以蛇形布局排列成3x3和2x2网格数据集。然后,利用LoRA方法对预训练模型进行微调,生成文本描述的分层像素图像。接着,引入图像条件机制,通过额外的LoRA微调预测参考图像的创建过程。最后,在逐层矢量化阶段,将生成的像素图像转换为高质量的矢量图形。
蛇形数据集构建:
- 数据集概述:数据集包含20,000多个由设计师创建的分层SVG,涵盖黑色轮廓图标、常规图标、表情符号和插图图形。每个序列由9或4帧组成,排列成3x3或2x2网格,分辨率分别为1056x1056和1024x1024。
- 蛇形布局:为了确保序列生成的连贯性,采用蛇形布局方法,将时间上相邻的帧在空间上也相邻排列(水平或垂直)。此外,在数据集创建过程中,将具有黑色线条的图标的黑色线条层单独放置在第一帧中,以便在生成阶段进行矢量化并叠加到后续结果上。
逐层图像生成:
- DiT模型的利用:训练在大量图像-文本对上的DiT模型具有上下文生成能力。通过适当激活和增强这种能力,可以将其用于复杂的生成任务。
- 训练与损失函数:采用LoRA微调方法进行训练,并使用条件流匹配损失函数进行优化。
Image2Layers模型:
- 图像条件机制:该模型将图像条件融入DiT模型中,通过自注意力机制为其他帧的去噪过程提供条件信息,增强逻辑一致性和连贯性。
- 训练与推理:在训练阶段,将最终帧(上下文图像)通过VAE提取潜在变量,并将其附加到去噪潜在变量的末尾。在推理阶段,使用参考图像作为条件来预测早期图层,从而推断出参考图像中SVG的分层构建过程。
逐层矢量化:
- 预处理与矢量化:首先,将网格图像分割成单独的单元格,以便进行独立处理。对于图标,准确提取黑色线条至关重要,因为它们代表图像的关键结构元素。接着,通过灰度转换、高斯模糊和自适应阈值等预处理步骤来增强线条对比度并减少噪声。然后,通过计算相邻单元格之间的绝对差异并应用二值阈值和形态学操作来识别显著像素变化区域,并保存为透明PNG以进行后续矢量化。最后,使用工具如vtracer对这些差异层进行矢量化,优化参数以平衡细节保留和文件大小,并将所有矢量化层合并为一个SVG文件。
4. 实验与结果
实验设置:
- 预训练与微调:在预训练阶段,使用基于预训练DiT架构的Flux 1.0dev模型。训练分辨率包括1056x1056(3x3网格)和1024x1024(2x2网格)。采用LoRA微调方法,设置LoRA秩为256、批量大小为16和微调步数为20,000。对于Image Condition模型的训练,将Layer-wise Image Generation LoRA与基础模型合并,并设置LoRA合并权重为1.0,然后在相同数据集上进行额外的20,000步微调。
- 基线方法与基准:在文本到SVG生成任务中,基线方法包括SVGDreamer、Vecfusion和DiffSketcher。在矢量化任务中,基线方法包括diffvg、LIVE和O&R。此外,还引入了LayerSVG数据集和Noto-Emoji数据集作为基准进行测试。
生成结果:
- 文本到SVG生成:LayerTracer能够生成与文本描述相符且具有逻辑图层层次的认知对齐分层SVG(例如,背景到前景的顺序和语义元素的分组)。输出保留了关键设计属性,包括图层独立性、非重叠路径和拓扑可编辑性。
- 图像矢量化:LayerTracer能够将输入栅格图像分解为干净的矢量图层,具有一致的空间对齐和最小的形状冗余。
比较与评价:
- 定量评价:在文本到SVG任务中,LayerTracer在CLIP分数、时间成本和路径数量方面均优于基线方法。在逐层矢量化任务中,LayerTracer在MSE、时间成本和路径数量方面也表现出色。
- 定性评价:LayerTracer生成的结果更加简洁和连贯,符合图标和表情符号的具体要求。相比之下,基线方法导致视觉杂乱和不规则路径。在逐层矢量化任务中,LayerTracer的结果保持了逻辑空间层次和语义分组,而基线方法则产生了碎片化和对齐不良的输出。
消融研究:
- 蛇形布局策略:消融研究表明,不使用蛇形布局策略构建训练数据集时,更可能出现不完整的分解、不必要的重复和帧之间的突然变化。定量评估结果也支持了蛇形布局策略的有效性。
用户研究:
- 用户偏好与文本图像对齐:用户研究表明,LayerTracer在用户偏好、文本图像对齐和图层合理性方面均优于基线方法。
5. 限制与未来工作
- 现有限制:在逐层矢量化过程中,LayerTracer依赖于如Vtracer等方法,继承了其需要手动调整超参数的局限性。此外,LayerTracer在处理分布外数据和复杂图像时的性能也较差。
- 未来方向:未来计划开发更智能的单层矢量化解决方案来替代Vtracer,并改进LayerTracer在处理复杂图像和分布外数据方面的性能。
6. 结论
本文提出了LayerTracer,一个基于扩散变换器的框架,通过模拟设计师的分层SVG创建过程,实现了与认知对齐的分层SVG合成。LayerTracer通过两个阶段的处理——文本条件化的DiT生成多阶段栅格化构建蓝图和逐层矢量化——生成了干净、可编辑且语义上有意义的矢量图形。此外,通过构建包含超过20,000个SVG创建序列的数据集和提出蛇形布局方法,有效支持了模型训练。大量实验表明,LayerTracer在生成质量和可编辑性方面均优于基线方法,为可缩放矢量图形的创建设立了新的基准。

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









