






摘要:问题解决的任务是修改代码库以生成解决给定问题的补丁。 然而,现有的基准测试,如SWE-bench,几乎只关注Python,这使得它们不足以评估跨不同软件生态系统的大型语言模型(LLMs)。 为了解决这个问题,我们引入了一个多语言问题解决基准,称为Multi-SWE-bench,涵盖Java、TypeScript、JavaScript、Go、Rust、C和C++。 它总共包含1632个高质量的实例,这些实例是由68位专家标注者从2456个候选者中精心标注的,以确保基准能够提供准确可靠的评估。 基于Multi-SWE-bench,我们使用三种代表性方法(无代理、SWE-agent和OpenHands)评估了一系列最先进的模型,并提出了具有关键实证见解的综合分析。 此外,我们推出了一个Multi-SWE-RL开源社区,旨在为问题解决任务构建大规模强化学习(RL)训练数据集。 作为最初的贡献,我们发布了跨越七种编程语言的4723个结构良好的实例,为该领域的强化学习研究奠定了坚实的基础。 更重要的是,我们将整个数据生产管道以及详细的教程开源,鼓励开源社区不断贡献和扩展数据集。 我们设想我们的多SWE-bench和不断发展的多SWE-RL社区是推动RL充分发挥潜力的催化剂,使我们离AGI的曙光更近了一步。Huggingface链接:Paper page,论文链接:2504.02605
研究背景和目的
研究背景
随着人工智能技术的飞速发展,大型语言模型(LLMs)在自动化软件工程任务中展现出巨大的潜力。特别是,在代码生成和问题解决方面,LLMs已经取得了显著的成果。然而,当前的研究主要集中在Python等单一编程语言上,对于多语言环境下的LLMs性能评估仍然不足。在实际的软件开发生态系统中,代码库通常包含多种编程语言,这要求LLMs具备跨语言理解和解决问题的能力。
此外,现有的软件工程基准测试集,如SWE-bench,虽然为评估LLMs在问题解决任务上的性能提供了有力支持,但它们主要聚焦于Python语言,缺乏对多语言环境的全面覆盖。这限制了我们对LLMs在更广泛软件生态系统中的适用性和泛化能力的理解。
为了解决这一问题,需要建立一个多语言的问题解决基准测试集,以全面评估LLMs在不同编程语言环境下的性能。同时,还需要开发相应的方法和工具,以支持在复杂软件工程任务中应用强化学习(RL)技术,进一步推动LLMs向更高级别的智能迈进。
研究目的
本研究旨在解决以下问题:
-
构建多语言问题解决基准测试集:开发一个名为Multi-SWE-bench的多语言基准测试集,涵盖Java、TypeScript、JavaScript、Go、Rust、C和C++等七种广泛使用的编程语言。该基准测试集将包含高质量的问题实例,用于评估LLMs在跨语言环境下的性能。
-
评估LLMs在多语言环境下的性能:利用Multi-SWE-bench基准测试集,评估一系列最先进的LLMs在不同编程语言下的问题解决能力。通过系统的实验和分析,揭示LLMs在不同语言环境中的性能差异和潜在挑战。
-
推动RL在软件工程中的应用:发起Multi-SWE-RL开源社区,旨在构建大规模RL训练数据集,以支持复杂软件工程任务中的RL研究。通过发布初始数据集和开源数据生产管道,鼓励开源社区持续贡献和扩展数据集,推动RL技术在软件工程领域的广泛应用。
研究方法
基准测试集构建
-
仓库选择:从GitHub上精心挑选高质量的仓库,基于星级评分和运行能力进行筛选,以确保仓库的流行性和实用性。
-
拉取请求爬取:收集与问题相关的拉取请求(PR)及其元数据,为后续的环境确定和PR过滤提供基础。
-
环境确定:为每个PR构建Docker化的运行环境,通过提取CI/CD工作流和文档中的依赖项来确保可复现的执行。
-
PR过滤:通过分析测试结果来验证PR的有效性,仅保留具有明确bug修复效果且无回归问题的PR。
-
人工验证:通过双重注释和交叉审查进行严格的人工验证,确保基准测试集的高质量和对齐性。
模型评估
-
评估方法:采用三种代表性的方法(Agentless、SWE-agent和OpenHands)来评估LLMs在问题解决任务上的性能。这些方法分别代表了不同的智能体设计思路和技术路线。
-
评估指标:使用解决率(Resolved Rate)作为主要评估指标,衡量LLMs解决给定问题的百分比。同时,还报告了成功定位率(Success Location)和平均成本(Average Cost)等其他指标,以提供更详细的分析。
-
实验设置:在Multi-SWE-bench基准测试集上评估九种最先进的LLMs,包括GPT-4o、OpenAI-o1、OpenAI-o3-mini-high、Claude-3.5-Sonnet、Claude-3.7-Sonnet、DeepSeek-V3、DeepSeek-R1、Qwen2.5-72B-Instruct和Doubao-1.5-pro。通过系统的实验设计,全面评估这些LLMs在不同编程语言下的性能。
研究结果
性能评估
-
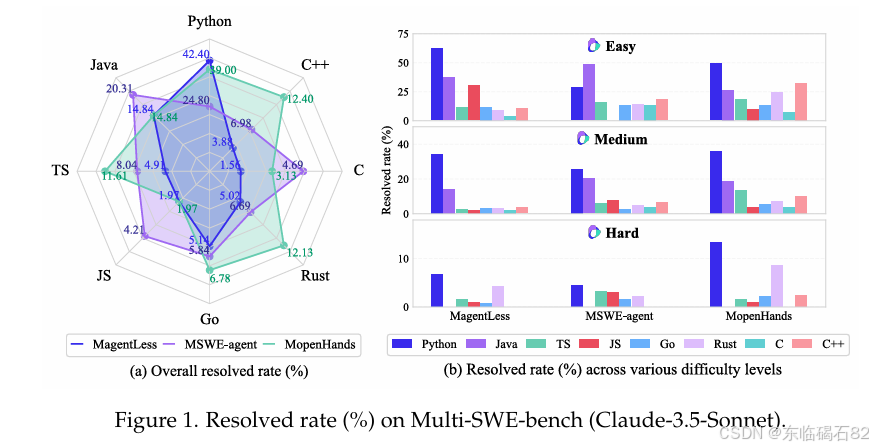
跨语言性能:实验结果显示,现有的LLMs和方法在解决Python问题时表现出色,但在其他语言上的泛化能力有限。这表明LLMs在跨语言环境下的性能仍存在较大提升空间。
-
方法与模型比较:不同方法和模型在解决多语言问题时表现出不同的性能特点。MopenHands方法在大多数语言中表现出最优性能,而MagentLess和MSWE-agent方法则在特定语言和情境下表现更好。此外,不同LLMs之间的性能差异也显著,表明模型架构和训练数据对性能有重要影响。
-
仓库特征影响:仓库的质量(如星级、分支数、PR数和问题数)和复杂性(如代码行数、文件数和语言熵)对LLMs的性能有显著影响。高质量和复杂性适中的仓库往往能够获得更高的解决率。
-
问题类型与难度:不同类型的问题(如bug修复、新功能请求和功能优化)对LLMs的性能有不同影响。bug修复问题相对容易解决,而新功能请求和功能优化问题则更具挑战性。此外,问题的难度级别也与解决率密切相关,难度较高的问题往往需要更多的资源和时间来解决。
影响因素分析
-
问题描述长度:问题描述的长度对解决率有一定影响,但这种影响并不一致。在某些语言中,较长的问题描述可能提供更多的上下文信息,有助于LLMs做出更准确的决策;而在其他语言中,过长的问题描述可能导致信息过载,降低解决率。
-
修复补丁特征:修复补丁的长度和涉及的文件数对解决率有显著影响。较长的修复补丁和涉及多个文件的修复任务往往需要更复杂的推理能力和跨文件处理能力,这对LLMs提出了更高的挑战。
研究局限
-
基准测试集规模:尽管Multi-SWE-bench基准测试集已经包含了1632个高质量的问题实例,但其规模仍然有限,可能无法全面反映真实世界中的软件工程任务复杂性。未来的研究需要进一步扩大基准测试集的规模,以提供更全面的评估。
-
模型泛化能力:现有的LLMs在跨语言环境下的泛化能力仍然有限,特别是在处理复杂软件工程任务时表现出明显的性能下降。这表明LLMs在理解和应用跨语言知识方面仍存在较大挑战。
-
评估方法限制:本研究主要采用了解决率作为主要评估指标,虽然这能够直观地反映LLMs的性能,但可能无法全面评估LLMs在问题解决过程中的其他重要方面(如定位准确性、修复效率等)。未来的研究需要探索更全面的评估方法,以提供更深入的分析。
未来研究方向
-
扩展基准测试集:未来的研究可以进一步扩展Multi-SWE-bench基准测试集的规模和覆盖范围,以包含更多编程语言、问题类型和复杂度级别。这将有助于更全面地评估LLMs在软件工程任务中的性能和泛化能力。
-
提升模型泛化能力:针对LLMs在跨语言环境下的泛化能力有限的问题,未来的研究可以探索更有效的模型架构和训练方法,以提升LLMs在处理复杂软件工程任务时的性能。例如,可以通过引入跨语言表示学习、多模态融合等技术来增强LLMs的跨语言理解和应用能力。
-
强化学习在软件工程中的应用:随着RL技术的不断发展,未来的研究可以进一步探索如何将RL应用于软件工程任务中,以实现更智能、更高效的自动化解决方案。例如,可以开发基于RL的代码修复、软件测试和部署等工具,以支持更复杂的软件工程流程。
-
综合评估方法:未来的研究需要探索更全面的评估方法,以更深入地分析LLMs在问题解决过程中的各种重要方面。例如,可以结合定位准确性、修复效率、代码质量等多个指标来综合评估LLMs的性能,以提供更全面的见解和指导。
综上所述,本研究通过构建Multi-SWE-bench基准测试集和评估一系列最先进的LLMs在多语言环境下的性能,为理解LLMs在软件工程任务中的适用性和挑战提供了重要见解。未来的研究可以进一步扩展基准测试集、提升模型泛化能力、探索RL在软件工程中的应用以及开发综合评估方法等方面来推动该领域的发展。

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









