







 超级会员免费看
超级会员免费看
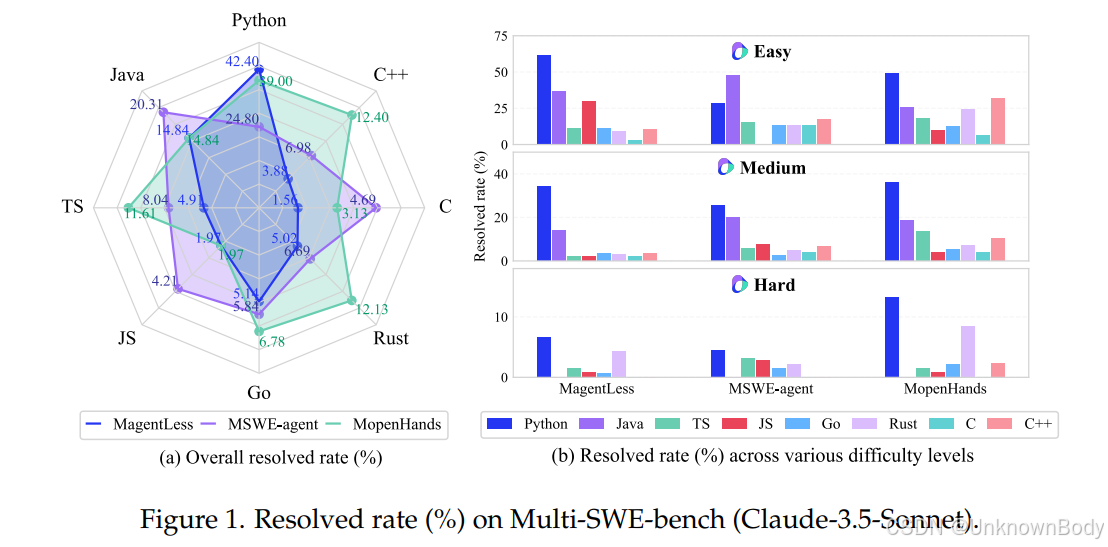
一、主要内容总结
本文提出了多语言问题解决基准 Multi-SWE-bench,旨在评估大型语言模型(LLM)在跨编程语言场景下解决代码问题的能力。现有基准(如SWE-bench)主要聚焦Python,而Multi-SWE-bench覆盖了Java、TypeScript、JavaScript、Go、Rust、C、C++共7种语言,包含1,632个高质量实例,这些实例经过68位专家的严格人工注释和验证,确保了基准的可靠性和准确性。
核心内容:
-
基准构建:通过五个阶段构建数据集:
- 仓库选择:从GitHub筛选高星、活跃且支持CI/CD的优质仓库。
- PR爬取:收集与问题关联的合并PR,确保包含测试文件修改。
- 环境确定:构建Docker化环境,提取依赖以保证可复现性。
- PR过滤:通过测试日志分

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











