






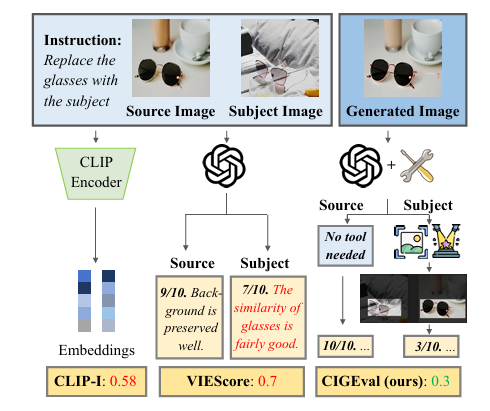
摘要:条件图像生成因其个性化内容的能力而受到广泛关注。 然而,该领域在开发与任务无关、可靠和可解释的评估指标方面面临着挑战。 本文介绍了CIGEval,这是一个用于全面评估条件图像生成任务的统一代理框架。 CIGEval以大型多模态模型(LMM)为核心,整合多功能工具箱,建立细粒度评估框架。此外,我们综合评估轨迹进行微调,使较小的LMM能够自主选择合适的工具,并根据工具输出进行细致的分析。 在七个著名的条件图像生成任务上的实验表明,CIGEval(GPT-4o版本)与人类评估的相关性高达0.4625,与标注者之间的相关性0.47非常接近。 此外,当使用7B开源LMM仅使用2.3K训练轨迹实现时,CIGEval超过了之前基于GPT-4o的最先进方法。 关于GPT-4o图像生成的案例研究突出了CIGEval在识别与主题一致性和遵守控制指导有关的细微问题方面的能力,表明其在以人类水平的可靠性自动评估图像生成任务方面具有巨大潜力。Huggingface链接:Paper page,论文链接:2504.07046
研究背景和目的
研究背景
随着人工智能技术的快速发展,条件图像生成任务在图像编辑、艺术创作、图像修复等多个领域展现出巨大的应用潜力。条件图像生成技术能够根据给定的文本描述、参考图像或其他控制信号,生成符合特定要求的图像内容。这种技术不仅能够极大地丰富图像数据的多样性,还能为用户提供高度个性化的图像生成体验。然而,随着条件图像生成技术的不断进步,如何有效地评估生成图像的质量成为了一个亟待解决的问题。
传统的图像评估方法往往侧重于图像与给定条件的对齐程度或图像的感知质量,但这些方法往往存在任务特异性、解释性差以及与人类评估相关性不高的问题。特别是在处理涉及多个条件或复杂控制信号的条件图像生成任务时,传统方法往往难以全面、准确地评估生成图像的质量。因此,开发一种统一、可靠且可解释的评估框架对于推动条件图像生成技术的发展具有重要意义。
研究目的
本文旨在提出一种用于全面评估条件图像生成任务的统一代理框架CIGEval。该框架旨在克服传统评估方法的局限性,通过整合大型多模态模型(LMM)和多功能工具箱,实现对生成图像的细粒度评估。具体研究目的包括:
- 开发统一评估框架:设计并实现一个能够适用于多种条件图像生成任务的统一评估框架,提高评估方法的通用性和适用性。
- 提高评估可靠性:通过整合大型多模态模型,实现对生成图像质量的更准确评估,提高评估结果与人类评估之间的相关性。
- 增强评估解释性:提供详细的评估过程和中间结果,使评估方法更具解释性,有助于深入理解生成图像的质量问题。
- 促进自动化评估:通过赋予评估框架自主选择合适的评估工具和进行细致分析的能力,推动条件图像生成任务的自动化评估进程。
研究方法
框架设计
CIGEval框架以大型多模态模型为核心,整合了一个多功能工具箱,并建立了细粒度评估框架。具体来说,CIGEval框架包括以下几个关键组成部分:
- 任务定义:首先明确了条件图像生成任务的定义,将评估问题形式化为一个根据指令、合成图像和条件集合生成中间推理和最终得分的函数。
- 工具箱设计:设计了一个多功能工具箱,包括接地(Grounding)、差异(Difference)、高亮(Highlight)和场景图(Scene Graph)等工具,每个工具针对图像评估的特定方面进行优化。
- 评估框架:建立了细粒度评估框架,采用分而治之的策略将评估任务分解为多个子问题,并根据子问题选择合适的评估工具。评估框架能够分析工具输出,并基于中间结果生成最终评分。
- 代理微调:为了将代理能力整合到较小的LMM中,合成了高质量评估轨迹用于微调。通过让GPT-4o执行评估过程并过滤与人类评估一致的轨迹,构建了用于微调的数据集。
实验设置
为了验证CIGEval框架的有效性,本文在七个著名的条件图像生成任务上进行了实验,包括文本引导的图像生成、掩码引导的图像编辑、文本引导的图像编辑、主体驱动的图像生成、主体驱动的图像编辑、多概念图像合成和控制引导的图像生成。实验采用了ImagenHub基准数据集,该数据集包含了大量由不同模型生成的图像及其对应的人类评分。
在实验过程中,本文首先评估了CIGEval框架与人类评估之间的相关性,通过计算Spearman相关系数来衡量。此外,还进行了消融研究以评估每个工具在CIGEval框架中的重要性。最后,通过案例研究展示了CIGEval框架在识别GPT-4o生成图像中细微问题方面的能力。
研究结果
评估性能
实验结果表明,当使用GPT-4o作为底层模型时,CIGEval框架在所有七个任务上均实现了与人类评估高度相关的性能,平均Spearman相关系数为0.4625,与人类评估者之间的相关性0.47非常接近。这一结果表明CIGEval框架能够准确地评估生成图像的质量,并且与人类评估结果高度一致。
工具重要性
消融研究结果显示,CIGEval框架中的每个工具都对其整体性能有重要贡献。当移除任何一个工具时,CIGEval框架的性能都会出现明显下降。特别是接地(Grounding)和高亮(Highlight)工具在多个任务中表现出了关键作用。此外,当使用开源模型(如Qwen2.5-VL-7B-Instruct)作为底层模型时,通过代理微调可以显著提高评估性能,甚至超过了基于GPT-4o的先前最先进方法。
案例研究
案例研究展示了CIGEval框架在识别GPT-4o生成图像中细微问题方面的能力。例如,在文本引导的图像编辑任务中,CIGEval框架能够准确地识别出编辑后的图像与原始图像之间的细微差异,并给出合理的评分。相比之下,传统评估方法往往难以捕捉到这些细微差异。此外,在控制引导的图像生成任务中,CIGEval框架还能够有效地评估生成图像对控制信号的遵守程度。
研究局限
尽管CIGEval框架在条件图像生成任务的评估中表现出了优异的性能,但仍存在一些局限性:
- 模型依赖性:CIGEval框架的性能高度依赖于所使用的底层模型。当使用开源模型作为底层模型时,尽管通过代理微调可以显著提高评估性能,但与闭源模型(如GPT-4o)相比仍存在一定差距。
- 数据局限性:由于缺乏更全面的条件图像生成基准数据集,本文的实验主要集中在ImagenHub数据集上。未来需要扩展实验范围以验证CIGEval框架在不同数据集上的性能。
- 感知质量评估:本文主要关注生成图像的语义一致性评估,而对感知质量的评估仍有待进一步研究。未来可以探索将感知质量评估整合到CIGEval框架中的方法。
未来研究方向
针对上述研究局限,未来可以在以下几个方面进行深入研究:
- 模型优化:进一步优化开源模型的结构和训练策略,提高其在条件图像生成任务评估中的性能。特别是可以探索针对评估任务进行专门优化的模型训练方法。
- 数据集扩展:构建更全面的条件图像生成基准数据集,以验证CIGEval框架在不同数据集和任务上的性能。特别是可以关注具有更复杂控制信号和更高生成质量的条件图像生成任务。
- 感知质量评估:研究将感知质量评估整合到CIGEval框架中的方法。可以考虑引入感知损失函数或利用人类评估数据来指导感知质量评估模型的训练。
- 实时评估:探索实现实时条件图像生成评估的方法。特别是在交互式图像编辑和实时图像生成应用中,实时评估能力对于提供即时反馈和优化生成过程至关重要。
- 跨模态评估:研究将条件图像生成评估扩展到其他跨模态任务中的方法。例如,可以探索如何评估文本到视频的生成质量或音频到图像的生成质量等。这有助于推动多模态生成技术的整体发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









