






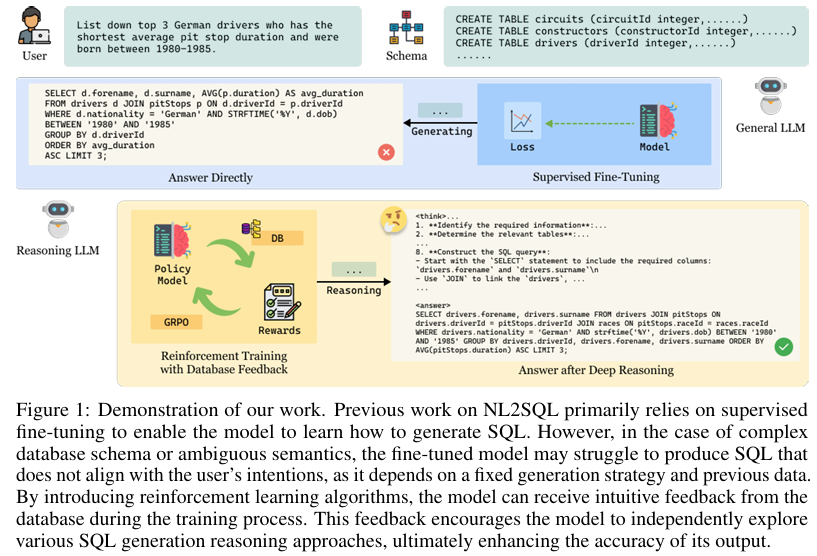
摘要:自然语言到SQL(NL2SQL)通过将自然语言查询转换为结构化的SQL语句,实现了与数据库的直观交互。 尽管最近在增强数据库应用程序中的人机交互方面取得了进展,但仍然存在重大挑战,特别是在涉及多表连接和嵌套查询的复杂场景中的推理性能方面。 当前的方法主要利用监督微调(SFT)来训练NL2SQL模型,这可能会限制新环境(如金融和医疗保健)的适应性和可解释性。 为了在上述复杂情况下提高NL2SQL模型的推理性能,我们引入了SQL-R1,这是一种通过强化学习(RL)算法训练的新型NL2SQL推理模型。 我们设计了一个专门针对NL2SQL任务的基于RL的奖励函数,并讨论了冷启动对强化训练有效性的影响。 此外,我们仅使用少量的合成NL2SQL数据进行增强训练,并进一步探索RL的数据工程,从而实现了具有竞争力的准确率。在现有的实验中,SQL-R1仅使用7B基础模型,在基准Spider和BIRD上分别实现了88.6%和66.6%的执行准确率。
研究背景和目的
研究背景
随着大数据和人工智能技术的快速发展,数据库管理系统在现代信息系统中扮演着至关重要的角色。然而,对于非专业用户来说,直接使用SQL语言与数据库进行交互往往存在一定的门槛。自然语言到SQL(NL2SQL)技术应运而生,它旨在将自然语言查询转换为结构化的SQL语句,从而简化与数据库的交互过程,无需用户具备专业的数据库知识。近年来,NL2SQL技术取得了显著进展,特别是在大型语言模型(LLMs)的推动下,其在单表查询和简单场景下的表现已经相当出色。然而,在涉及多表连接、嵌套查询等复杂数据库场景时,现有NL2SQL模型的推理性能和泛化能力仍面临巨大挑战。
传统上,NL2SQL模型的训练方法主要依赖于监督微调(SFT),这种方法虽然在一定程度上提高了模型的准确率,但在面对新环境和新数据时,模型的适应性和可解释性受到限制。特别是在金融、医疗保健等高风险领域,模型的准确性和可解释性尤为重要。因此,如何提升NL2SQL模型在复杂场景下的推理性能,同时增强其适应性和可解释性,成为当前研究的热点和难点。
研究目的
本研究旨在通过强化学习(RL)算法训练自然语言到SQL推理模型,以提高其在复杂数据库场景下的推理性能和泛化能力。具体而言,本研究旨在解决以下几个关键问题:
- 设计有效的RL算法:针对NL2SQL任务,设计一种专门的RL算法,以优化模型的推理过程,生成更符合用户意图的SQL语句。
- 冷启动策略:探索冷启动训练对RL模型性能的影响,制定有效的冷启动策略,以提升模型的指令遵循能力和NL2SQL生成质量。
- 数据工程:研究如何利用现有的数据工程技术,生成高质量的合成数据,以支持RL模型的训练,提高模型的鲁棒性和泛化能力。
通过上述研究,本研究期望能够提出一种新型的NL2SQL推理模型(SQL-R1),该模型在复杂数据库场景下具有更高的推理性能和更好的适应性,同时能够生成可解释的推理过程,为NL2SQL技术的实际应用提供有力支持。
研究方法
数据准备
本研究利用SynSQL-2.5M数据集作为主要数据源,该数据集是一个百万级别的合成NL2SQL数据集,包含超过250万个多样化和高质量的数据样本。每个样本由一个数据库、一个自然语言问题、一个SQL查询以及一个链式思考(CoT)解决方案组成。该数据集涵盖了超过16,000个合成数据库,涉及多个领域,确保了现实场景的广泛覆盖。此外,SynSQL-2.5M数据集包含了从简单单表查询到复杂多表连接、函数和公共表表达式等多种SQL复杂度级别。
为了研究冷启动条件对RL训练的影响,本研究从SynSQL-2.5M数据集中抽取了200,000个样本作为SFT训练集(SynSQL-200K),该训练集在不同难度级别上的样本数量是均匀的,每个级别包含50,000个样本。对于RL训练,本研究随机抽取了5,000个复杂NL-SQL对作为RL训练集(SynSQL-Complex-5K)。
训练策略
-
监督微调(SFT):本研究在Qwen2.5-Coder-7B-Instruct模型上进行SFT,以增强模型对指令的遵循能力和在NL2SQL领域的生成能力。SFT训练采用了两种策略:一种是仅使用原始指令进行SQL生成;另一种是使用完整微调和推理生成指令,以促进符合要求的思考过程和最终答案的发展。
-
强化训练:在强化学习阶段,本研究采用了组相对策略优化(GRPO)算法来增强训练协议。GRPO算法无需价值模型,内存需求较低,且奖励目标定义清晰,非常适合于有效优化NL2SQL策略模型。对于每个自然语言问题和相应的数据库模式,策略模型从旧策略π_{old}中生成一组G个SQL候选{o_1, o_2, ..., o_G},并使用复合奖励函数对这些候选进行评估。奖励函数包括格式奖励、执行奖励、结果奖励和长度奖励,以在不同阶段为模型提供详细的反馈。
-
奖励函数设计:本研究设计了一个专门针对NL2SQL任务的基于RL的奖励函数,包括格式奖励、执行奖励、结果奖励和长度奖励。格式奖励鼓励模型将NL2SQL推理过程包含在标签内,并将最终答案包含在标签内。执行奖励评估SQL候选的语法正确性,防止模型生成杂乱无章、无法执行的响应。结果奖励将查询结果的准确性作为评估SQL候选的重要标准,以激励模型生成与用户真实意图相符的SQL候选。长度奖励激励模型产生更全面的推理过程,同时避免产生冗长的解释。
SQL候选选择
在推理过程中,模型为一个问题生成多个SQL候选及其思考过程。本研究执行所有SQL候选,并选择得分最高的SQL作为最终答案,基于自洽性投票。SQL-R1的推理响应包括一个可观察的思考和解释过程,使用户更容易理解结果。
研究结果
基准测试性能
本研究在Spider和BIRD基准测试集上评估了SQL-R1和相关NL2SQL模型的性能。实验结果显示,SQL-R1在Spider开发集上达到了87.6%的执行准确率,在测试集上达到了88.7%的执行准确率,在BIRD开发集上达到了66.6%的执行准确率。与采用Qwen2.5-Coder-7B模型的NL2SQL解决方案相比,SQL-R1表现出相当的性能水平。特别是,SQL-R1的性能优于许多依赖封闭源模型(如GPT-4和GPT-4o)的NL2SQL解决方案。
性能与模型规模权衡
本研究还探讨了性能与模型规模之间的关系。实验结果显示,在使用7B模型作为基础模型的情况下,SQL-R1的准确率超过了更大规模的模型。这表明SQL-R1在优化NL2SQL性能的同时,也保持了成本效益。
案例分析
本研究通过案例分析探讨了RL训练对实际NL2SQL推理的影响。实验结果显示,经过RL训练后,模型在处理更具挑战性的样本时表现出更强的推理能力,呈现出一种自上而下的认知策略来生成SQL查询。这证实了强化学习在提升NL2SQL任务中模型推理能力方面的有效性。
冷启动分析
本研究还分析了冷启动训练对RL基NL2SQL推理模型性能的影响。实验结果显示,冷启动训练显著提高了RL基NL2SQL推理模型的性能,增强了模型的指令遵循能力和SQL生成质量。
奖励组件消融研究
本研究在BIRD开发数据集上进行了消融实验,以验证所提出的强化学习奖励机制的有效性。实验结果显示,从原始奖励函数中移除任何奖励组件都会对推理性能产生不利影响。这强调了执行反馈和结果奖励在模型训练过程中的重要性。
研究局限
尽管SQL-R1在复杂数据库场景下的推理性能和泛化能力方面取得了显著进展,但本研究仍存在一些局限性:
- 支持的数据库方言:当前研究仅支持在SQLite方言上进行训练和评估,尚未在其他数据库方言(如Snowflake、DuckDB)上进行评估。
- 模型可解释性:虽然SQL-R1能够生成可解释的推理过程,但模型的决策过程仍然是一个黑箱,缺乏完全的可解释性。
- 多表联合能力:当前研究在涉及多表连接的复杂查询上的表现仍有待提升,特别是在处理高度复杂的数据库模式时。
未来研究方向
针对上述局限性,未来研究可以从以下几个方面展开:
- 扩展数据库方言支持:将SQL-R1扩展到更多数据库方言上,以提高其在实际应用中的通用性和实用性。
- 增强模型可解释性:研究如何使SQL-R1的决策过程更加透明和可解释,以提高用户对模型结果的信任度。
- 提升多表联合能力:通过改进模型架构和训练方法,提升SQL-R1在处理涉及多表连接的复杂查询时的表现。
- 探索合成数据生成:进一步研究如何利用合成数据生成技术来支持NL2SQL模型的扩展训练,提高模型的鲁棒性和泛化能力。
综上所述,本研究通过引入强化学习算法训练NL2SQL推理模型,在复杂数据库场景下取得了显著的性能提升。未来研究将继续优化模型性能、扩展应用场景,并探索新的训练方法和技术,以推动NL2SQL技术的进一步发展。

















 5276
5276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









