







5.2.1 Backbone(特征提取)
在上一节图像分类的课程中,我们已经学习过了通过卷积神经网络提取图像特征。通过连续使用多层卷积和池化等操作,能得到语义含义更加丰富的特征图。在检测问题中,也使用卷积神经网络逐层提取图像特征,通过最终的输出特征图来表征物体位置和类别等信息。
YOLOv3算法使用的骨干网络是Darknet53。Darknet53网络的具体结构如图3所示,在ImageNet图像分类任务上取得了很好的成绩。在检测任务中,将图中C0后面的平均池化、全连接层和Softmax去掉,保留从输入到C0部分的网络结构,作为检测模型的基础网络结构,也称为骨干网络。YOLOv3模型会在骨干网络的基础上,再添加检测相关的网络模块。
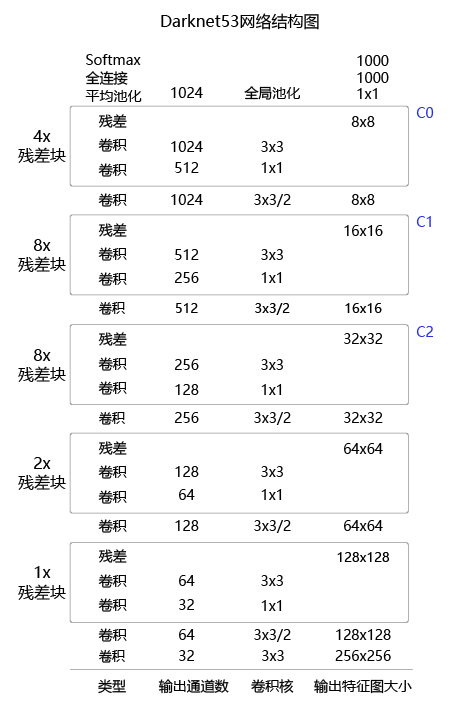
图3:Darknet53网络结构
下面的程序是Darknet53骨干网络的实现代码,这里将上图中C0、C1、C2所表示的输出数据取出,并查看它们的形状分别是,C0[1,1024,20,20],C1[1,512,40,40],C2[1,256,80,80]。
- 名词解释:特征图的步幅(stride)
在提取特征的过程中通常会使用步幅大于1的卷积或者池化,导致后面的特征图尺寸越来越小,特征图的步幅等于输入图片尺寸除以特征图尺寸。例如:C0的尺寸是20×20,原图尺寸是640×640,则C0的步幅是640/20=32。同理,C1的步幅是16,C2的步幅是8。
In [1]
import paddle
import paddle.nn.functional as F
import numpy as np
class ConvBNLayer(paddle.nn.Layer):
def __init__(self, ch_in, ch_out,
kernel_size=3, stride=1, groups=1,
padding=0, act="leaky"):
super(ConvBNLayer, self).__init__()
self.conv = paddle.nn.Conv2D(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(0., 0.02)),
bias_attr=False)
self.batch_norm = paddle.nn.BatchNorm2D(
num_features=ch_out,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(0., 0.02),
regularizer=paddle.regularizer.L2Decay(0.)),
bias_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Constant(0.0),
regularizer=paddle.regularizer.L2Decay(0.)))
self.act = act
def forward(self, inputs):
out = self.conv(inputs)
out = self.batch_norm(out)
if self.act == 'leaky':
out = F.leaky_relu(x=out, negative_slope=0.1)
return out
class DownSample(paddle.nn.Layer):
# 下采样,图片尺寸减半,具体实现方式是使用stirde=2的卷积
def __init__(self,
ch_in,
ch_out,
kernel_size=3,
stride=2,
padding=1):
super(DownSample, self).__init__()
self.conv_bn_layer = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=kernel_size,
stride=stride,
padding=padding)
self.ch_out = ch_out
def forward(self, inputs):
out = self.conv_bn_layer(inputs)
return out
class BasicBlock(paddle.nn.Layer):
"""
基本残差块的定义,输入x经过两层卷积,然后接第二层卷积的输出和输入x相加
"""
def __init__(self, ch_in, ch_out):
super(BasicBlock, self).__init__()
self.conv1 = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0
)
self.conv2 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1
)
def forward(self, inputs):
conv1 = self.conv1(inputs)
conv2 = self.conv2(conv1)
out = paddle.add(x=inputs, y=conv2)
return out
class LayerWarp(paddle.nn.Layer):
"""
添加多层残差块,组成Darknet53网络的一个层级
"""
def __init__(self, ch_in, ch_out, count, is_test=True):
super(LayerWarp,self).__init__()
self.basicblock0 = BasicBlock(ch_in,
ch_out)
self.res_out_list = []
for i in range(1, count):
# 使用add_sublayer添加子层
res_out = self.add_sublayer("basic_block_%d" % (i),
BasicBlock(ch_out*2,
ch_out))
self.res_out_list.append(res_out)
def forward(self,inputs):
y = self.basicblock0(inputs)
for basic_block_i in self.res_out_list:
y = basic_block_i(y)
return y
# DarkNet 每组残差块的个数,来自DarkNet的网络结构图
DarkNet_cfg = {53: ([1, 2, 8, 8, 4])}
class DarkNet53_conv_body(paddle.nn.Layer):
def __init__(self):
super(DarkNet53_conv_body, self).__init__()
self.stages = DarkNet_cfg[53]
self.stages = self.stages[0:5]
# 第一层卷积
self.conv0 = ConvBNLayer(
ch_in=3,
ch_out=32,
kernel_size=3,
stride=1,
padding=1)
# 下采样,使用stride=2的卷积来实现
self.downsample0 = DownSample(
ch_in=32,
ch_out=32 * 2)
# 添加各个层级的实现
self.darknet53_conv_block_list = []
self.downsample_list = []
for i, stage in enumerate(self.stages):
conv_block = self.add_sublayer(
"stage_%d" % (i),
LayerWarp(32*(2**(i+1)),
32*(2**i),
stage))
self.darknet53_conv_block_list.append(conv_block)
# 两个层级之间使用DownSample将尺寸减半
for i in range(len(self.stages) - 1):
downsample = self.add_sublayer(
"stage_%d_downsample" % i,
DownSample(ch_in=32*(2**(i+1)),
ch_out=32*(2**(i+2))))
self.downsample_list.append(downsample)
def forward(self,inputs):
out = self.conv0(inputs)
#print("conv1:",out.numpy())
out = self.downsample0(out)
#print("dy:",out.numpy())
blocks = []
#依次将各个层级作用在输入上面
for i, conv_block_i in enumerate(self.darknet53_conv_block_list):
out = conv_block_i(out)
blocks.append(out)
if i < len(self.stages) - 1:
out = self.downsample_list[i](out)
return blocks[-1:-4:-1] # 将C0, C1, C2作为返回值# 查看Darknet53网络输出特征图
import numpy as np
backbone = DarkNet53_conv_body()
x = np.random.randn(1, 3, 640, 640).astype('float32')
x = paddle.to_tensor(x)
C0, C1, C2 = backbone(x)
print(C0.shape, C1.shape, C2.shape)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
[1, 1024, 20, 20] [1, 512, 40, 40] [1, 256, 80, 80]
上面这段示例代码,指定输入数据的形状是(1,3,640,640)(1, 3, 640, 640),则3个层级的输出特征图的形状分别是C0(1,1024,20,20)C0 (1, 1024, 20, 20),C1(1,512,40,40)C1 (1, 512, 40, 40)和C2(1,256,80,80)C2 (1, 256, 80, 80)。
5.2.2 Neck(多尺度检测)
如果只在在特征图P0的基础上进行的,它的步幅stride=32。特征图的尺寸比较小,像素点数目比较少,每个像素点的感受野很大,具有非常丰富的高层级语义信息,可能比较容易检测到较大的目标。为了能够检测到尺寸较小的那些目标,需要在尺寸较大的特征图上面建立预测输出。
如果我们在C2或者C1这种层级的特征图上直接产生预测输出,可能面临新的问题,它们没有经过充分的特征提取,像素点包含的语义信息不够丰富,有可能难以提取到有效的特征模式。
在目标检测中,解决这一问题的方式是,将高层级的特征图尺寸放大之后跟低层级的特征图进行融合,得到的新特征图既能包含丰富的语义信息,又具有较多的像素点,能够描述更加精细的结构。
具体的网络实现方式如图4所示:
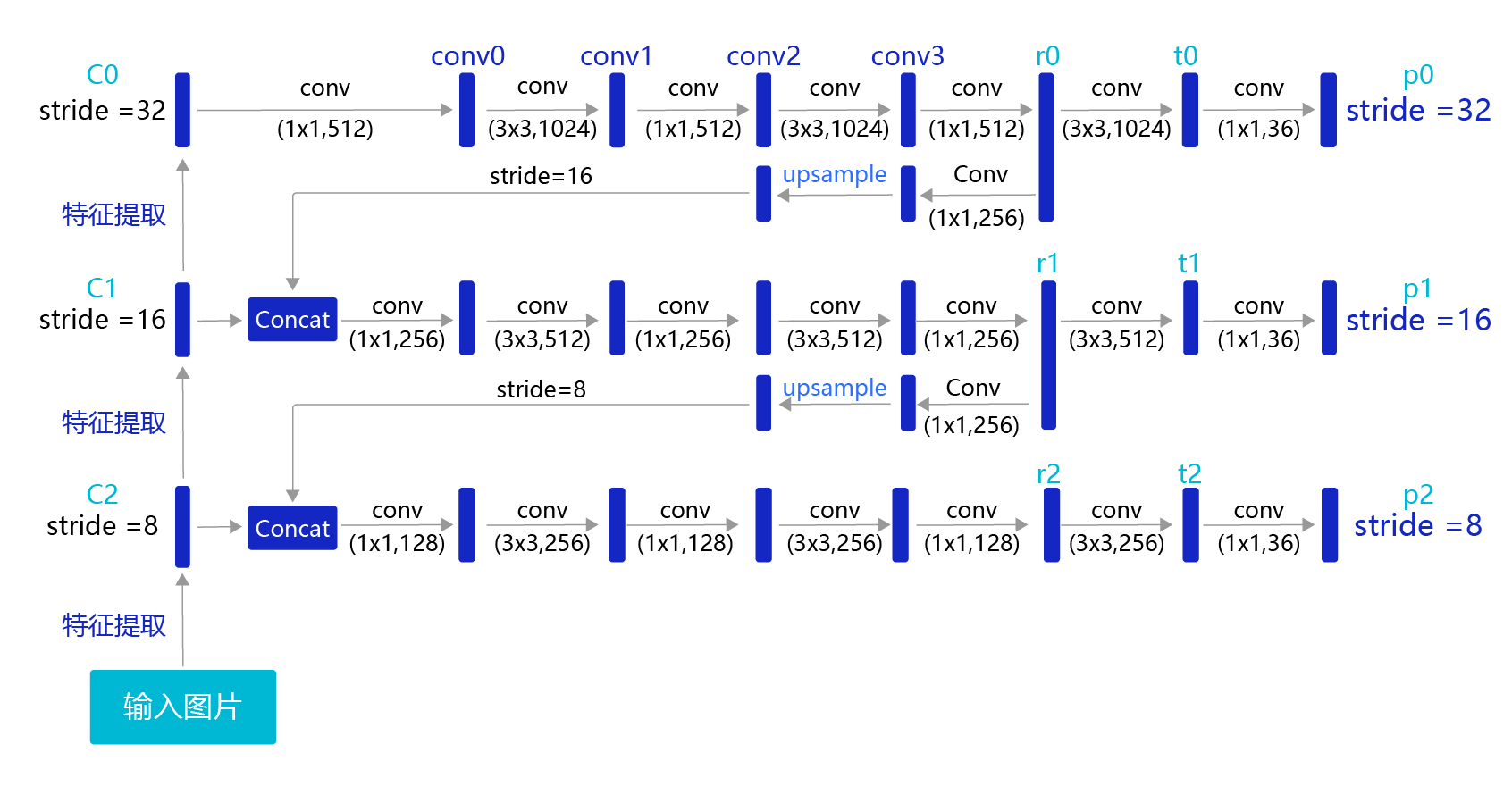
图4:生成多层级的输出特征图P0、P1、P2
YOLOv3在每个区域的中心位置产生3个锚框,在3个层级的特征图上产生锚框的大小分别为P2 [(10×13),(16×30),(33×23)],P1 [(30×61),(62×45),(59× 119)],P0[(116 × 90), (156 × 198), (373 × 326]。
越往后的特征图上用到的锚框尺寸也越大,能捕捉到大尺寸目标的信息;越往前的特征图上锚框尺寸越小,能捕捉到小尺寸目标的信息。

















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











