






一 引言
1957年,Rosenblatt提出感知机,可以实现线性样本二分类。感知机作为机器学习第一个架构提出,在机器学习中具有里程碑地位。然而感知机学习出的模型是否属于最优模型的问题却没有解决。此外,基于当时计算机水平发展限制、Minsky的巨大影响以及人们对Perceptrons书中论点的误解等,导致人工神经网络发展长期处于停滞阶段。
在这一背景下,一种功能强大、实现简单的支持向量机的出现,推动了机器学习在分类问题上的持续发展,是机器学习中的一种非常经典和具有坚实数学理论为基础的强大算法。
二 支持向量机(Support Vetor Machine–SVM)
1 Vapnik和SVM思想
Vapnik,美国国家工程院院士统计和机器学习方法奠基人。20世纪70年代,苏联科学家Vapnik创建了支持向量机的主要理论框架。冷战期间,西方世界并了解该研究成果。1990年,Vapnik在美国将自己成果发表欧美主流学术期刊,获得大量认可。 SVM具有很好泛化性能和小样本等优点而得到广泛应用。
SVM核心思想体现在一个非常关键的洞察(间隔最大)和一个简洁的技巧(核技巧)。Vapnik通过运用凸优化理论,用严格数学推导,将寻求最优分类超平面过程变成一个最优化求解的数学问题,提出支持向量机,使得SVM它具有三个极具魅力强大而简洁的特点:(1)构造出一个极大边距分离器(有助于良好泛化)(2)生成线性分离超平面,运用核技巧,将数据从低纬映射到高维度空间,实现分割,扩展了严格线性表示方法的假说空间。(3) SVM是运用凸优化求解,而非参数化调整方法。
SVM的突破在于解决了两个关键问题:(1) 线性可分问题最优求解 (2)将线性可分问题获得结论推广到线性不可分情况。
2 间隔最大化描述
如图1所示:(a)、(b)和(c)中间的黑色直线均能将样本划分来开。但是,若我们将黑色直线分别向它两侧平移,直到碰触到第一个样本为止。而这两条平移直线之间距离称为间隔。不难发现,(a)图所得到间隔最大。

|
间隔最大化的物理意义在于:对训练数据集找到几何间隔最大的超平面意味着以最大的确信度对训练数据进行分类。也就是说,不仅将正负实例点分开,而且对于最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分来。(此段文字摘录于李航老师著的《机器学习方法》P97页)
3 SVM模型的数学表达
图6.2拷贝于周志华老师《机器学习》西瓜书第六章:p122。

|
(1)训练样本集:
D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . . ( x L , y L ) , y i ∈ { − 1 , = 1 } D={(x_1,y_1),(x_2,y_2),....(x_L,y_L)},y_i\in\left\lbrace-1,=1\right\rbrace D=(x1,y1),(x2,y2),....(xL,yL),yi∈{−1,=1}
其样本空间的分布如图6.2所示。
(2)划分超平面,记为 ( w , b ) (w,b) (w,b)
w
T
x
+
b
=
0
(
1
)
w^Tx+b=0\qquad\qquad(1)
wTx+b=0(1)
其中,
w
=
(
w
1
;
w
2
;
.
.
.
.
w
d
)
w=(w_1;w_2;....w_d)
w=(w1;w2;....wd)为法向量,决定了超平面方向。b为位移项,决定了超平面和原点之间距离。所以,样本空间中任意样本点
x
x
x到超平面距离
γ
\gamma
γ可写为:
γ
=
∣
w
T
x
+
b
∣
∣
∣
w
∣
∣
(
2
)
\gamma=\frac{|w^Tx+b|}{||w||}\qquad\qquad(2)
γ=∣∣w∣∣∣wTx+b∣(2)
(3)支持向量
距离超平面最近的几个训练样本点使得下式成立,称为“支持向量(supprt vector)”:
{
w
T
x
i
+
b
≥
+
1
,
y
i
=
+
1
;
w
T
x
i
+
b
≤
−
1
,
y
i
=
−
1.
(
3
)
\left\{ \begin{array}{c} w^Tx_i+b\ge+1, \qquad y_i=+1;\\ w^Tx_i+b\leq-1,\qquad y_i=-1. \end{array} \right.\qquad(3)
{wTxi+b≥+1,yi=+1;wTxi+b≤−1,yi=−1.(3)
(4)最大间隔
两个异类支持向量到超平面距离之和称为间隔,记为:
γ
=
2
∣
∣
w
∣
∣
(
4
)
\gamma=\frac{2}{||w||}\qquad\qquad(4)
γ=∣∣w∣∣2(4)
最大间隔可写为:
max
w
,
b
2
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
.
L
(
5
)
\max\limits_{w,b}\frac{2}{||w||}\\ \qquad\\ \qquad \qquad s.t.y_i(w^Tx_i+b)\ge1,\quad i=1,2,....L\qquad(5)
w,bmax∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,....L(5)
为了计算方面,上述表达式可转化为下述最小化表达:
min
w
,
b
1
2
∣
∣
w
∣
∣
2
s
.
t
.
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
.
L
(
6
)
\min\limits_{w,b}\frac{1}{2}{||w||^2}\\ \qquad\\ \qquad \qquad s.t.y_i(w^Tx_i+b)\ge1,\quad i=1,2,....L\qquad(6)
w,bmin21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,....L(6)
可以看出,间隔最大化问题编程了带不等式约束条件的最小极值求解问题。上式是线性SVM最优化问题的基本型数学描述,是一个凸二次规划问题。
对最优化问题求解方法,根据约束条件类型,可分为:
1 无约束优化问题(直接求导,梯度下降,牛顿法等等)
2 等式约束优化问题:拉格朗日乘子法。
3不等式约束优化问题:KKT条件(Karush-Kuhn-Tucker三人名字首字母合成)。KKT条件将拉格朗日乘子法所处理的等式约束优化问题推广至不等式。
在SVM问题中,针对不等式约束优化问题,采用了满足KKT条件的拉格朗日对偶问题求解方法。
(5)拉格朗日对偶问题
约瑟夫.拉格朗日是法国著名数学、物理学家。拉格朗日对偶性的思想核心是:可以看出,SVM优化问题属于带有不等式约束优化问题。此类问题一个典型求解思路是:在满足原问题是凸优化和Sklater条件,附加上KKT条件,就可以用拉格朗日乘子法将一个求解有约束最优化的“原始不等式问题”转化为无约束的“等式”问题,并运用对偶问题进行求解。
针对SVM问题,步骤如下:
1)对SVM基本型模型添加拉格朗日乘子
α
≥
0
\alpha\ge0
α≥0后的原问题描述:
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
L
α
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
(
7
)
L(w,b,\alpha)=\frac{1}{2}||w||^2+ \displaystyle\sum^L_{i=1}\alpha_i(1-y_i(w^Tx_i+b))\qquad(7)
L(w,b,α)=21∣∣w∣∣2+i=1∑Lαi(1−yi(wTxi+b))(7)
其中,
α
=
(
α
1
,
α
2
,
.
.
.
α
L
)
\alpha=(\alpha_1,\alpha_2,...\alpha_L)
α=(α1,α2,...αL)。
2)求
min
w
,
b
L
(
w
,
b
,
α
)
\displaystyle\min_{w,b}L(w,b,\alpha)
w,bminL(w,b,α)
对
L
(
w
,
b
,
α
)
L(w,b,\alpha)
L(w,b,α) 函数的
w
,
b
w,b
w,b求导,得:
w
=
∑
i
=
1
L
α
i
y
i
x
i
(
8
)
0
=
∑
i
=
1
L
α
i
y
i
(
9
)
w=\displaystyle\sum^L_{i=1}\alpha_iy_ix_i\qquad\qquad(8)\\ 0=\displaystyle\sum^L_{i=1}\alpha_iy_i\qquad\qquad(9)
w=i=1∑Lαiyixi(8)0=i=1∑Lαiyi(9)
归纳整理可得:
min
w
,
b
L
(
w
,
b
,
α
)
=
∑
i
=
1
L
α
i
−
1
2
∑
i
=
1
L
∑
j
=
1
L
α
i
α
j
y
i
y
j
(
x
i
.
x
j
)
(
10
)
\displaystyle\min_{w,b}L(w,b,\alpha)=\displaystyle\sum^L_{i=1}\alpha_i-\frac{1}{2}\displaystyle\sum^L_{i=1}\displaystyle\sum^L_{j=1}\alpha_i\alpha_jy_iy_j(x_i.x_j)\qquad(10)
w,bminL(w,b,α)=i=1∑Lαi−21i=1∑Lj=1∑Lαiαjyiyj(xi.xj)(10)
3)求对偶问题转化
min
w
,
b
L
(
w
,
b
,
α
)
\displaystyle\min_{w,b}L(w,b,\alpha)
w,bminL(w,b,α)对
α
\alpha
α的极大,即对偶问题:
max
w
,
b
L
(
w
,
b
,
α
)
=
∑
i
=
1
L
α
i
−
1
2
∑
i
=
1
L
∑
j
=
1
L
α
i
α
j
y
i
y
j
(
x
i
.
x
j
)
(
11
)
\displaystyle\max_{w,b}L(w,b,\alpha)=\displaystyle\sum^L_{i=1}\alpha_i-\frac{1}{2}\displaystyle\sum^L_{i=1}\displaystyle\sum^L_{j=1}\alpha_i\alpha_jy_iy_j(x_i.x_j)\qquad(11)
w,bmaxL(w,b,α)=i=1∑Lαi−21i=1∑Lj=1∑Lαiαjyiyj(xi.xj)(11)
s
.
t
.
∑
i
=
1
L
α
i
y
i
=
0
s.t.\displaystyle\sum^L_{i=1}\alpha_iy_i=0
s.t.i=1∑Lαiyi=0
α
i
≥
=
0
,
i
=
1
,
2
,
.
.
.
.
.
L
\alpha_i\ge=0, i=1,2,.....L
αi≥=0,i=1,2,.....L
4)模型生成
解出
α
\alpha
α,求出
w
,
b
w,b
w,b,即可生成模型为:
f
(
x
)
=
w
T
+
b
=
∑
i
=
1
L
α
i
y
i
x
i
T
x
+
b
(
12
)
f(x)=w^T+b=\displaystyle\sum^L_{i=1}\alpha_iy_ix_i^Tx+b\qquad\qquad(12)
f(x)=wT+b=i=1∑LαiyixiTx+b(12)
其中,
α
\alpha
α需要满足KKT条件,即:
{
α
i
≥
0
;
y
i
f
(
x
i
)
−
1
≥
0
;
α
i
(
y
i
f
(
x
i
)
−
1
=
0.
(
13
)
\left\{ \begin{array}{c} \alpha_i\ge0;\qquad\qquad\quad\\ y_if(x_i)-1\ge0;\quad\\\ \alpha_i(y_if(x_i)-1=0. \end{array} \right.\qquad\qquad(13)
⎩
⎨
⎧αi≥0;yif(xi)−1≥0; αi(yif(xi)−1=0.(13)
可以看出:对于任意训练样本 ( x i , y i ) (x_i,y_i) (xi,yi),总有 α i = 0 或 y i f ( x i ) = 1 \alpha_i=0或y_if(x_i)=1 αi=0或yif(xi)=1。若 α i = 0 \alpha_i=0 αi=0,则样本不会出现在公式(12)中;若 y i f ( x i ) = 1 y_if(x_i)=1 yif(xi)=1,表明对应样本位于最大间隔边界上,即为支持向量。因此,训练完成后,只剩下和支持向量有关的最终模型。
4 编程应用
4.1 对西瓜数据集3.0 α \alpha α用线性核和高斯核进行训练SVM。
(1)数据集分布图
import numpy as np
import pandas as pd
df_watermelon=pd.read_csv("D:/ML/3data/watermelon.csv")
df_watermelon.head()
df_watermelon.target.value_counts()
import matplotlib.pyplot as plt
plt.scatter(x=df_watermelon.density[df_watermelon.target==1],y=df_watermelon.ratio[(df_watermelon.target==1)],c="red")
plt.scatter(x=df_watermelon.density[df_watermelon.target==0],y=df_watermelon.ratio[(df_watermelon.target==0)],marker='^')
plt.legend(["Good","Average "])
plt.xlabel("density")
plt.ylabel("ratio")
plt.show()
输出结果:
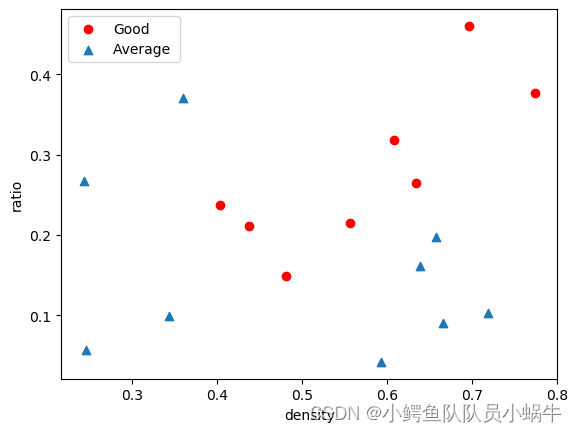
|
可以看出,分布结果是不是线性可分的。
(2)运用线性核进行训练
from sklearn import datasets
import numpy as np
from sklearn import svm #sklearn工具包
from sklearn.svm import SVC #sklearn工具包
from sklearn import model_selection #sklearn工具包
import matplotlib.pyplot as plt #作图相关包
import matplotlib as mpl #作图相关包
from matplotlib import colors #作图相关包
from matplotlib.colors import ListedColormap #作图相关包
from mlxtend.plotting import plot_decision_regions #区域划分包
from sklearn.model_selection import train_test_split #划分数据包
from sklearn.preprocessing import StandardScaler #数据标准化包
import warnings
warnings.filterwarnings('ignore')
encoding='utf-8
df_watermelon=pd.read_csv("D:/ML/3data/watermelonsimple.csv")
X=df_watermelon.drop(['target'],axis=1)
y=df_watermelon.target.values
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)
sc=StandardScaler()
sc.fit(X_train) #计算得到标准化要的u,方差
X_train_std=sc.transform(X_train)
X_test_std=sc.transform(X_test)
### 利用svm进行建模
svm_model = svm.SVC(C=2,kernel='linear',degree=4)
svm_model.fit(X_train, y_train)
### 在测试集上运用predict方法进行预测
y_pred=svm_model.predict(X_test_std)
print(y_test,y_pred)
print('Misclassified samples:%d' %(y_test!=y_pred).sum())
### 计算分类准确率
from sklearn.metrics import accuracy_score
print('Accuracy:%.2f' % accuracy_score(y_test,y_pred))
### 绘图函数
def plot_decison_regions(X,y,classifier,test_idx=None,resolution=0.02):
df_watermelon_feature = 'densitify', 'ratio'
#设置标记生成器和颜色映射
markers=('s','x','o','^','v')
colors=('red','blue','lightgreen','gray','cyan')#一维
cmap=ListedColormap(colors[:len(np.unique(y))])
#plot the decision surface
x1_min,x1_max=X[:,0].min()-0.5,X[:,0].max()+0.5
x2_min,x2_max=X[:,1].min()-0.5,X[:,1].max()+0.5
xx1,xx2=np.meshgrid(np.arange(x1_min,x1_max,resolution),np.arange(x2_min,x2_max,resolution))
Z=classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z=Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#plot all samples
X_test,y_test=X[test_idx,:],y[test_idx]
for idx,c1 in enumerate(np.unique(y)):
plt.scatter(x=X[y==c1,0],y=X[y==c1,1],alpha=0.8,c=cmap(idx),marker=markers[idx],label=c1)
#用于区分哪些是测试集的结果
if test_idx:
X_test,y_test=X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],alpha=1.0,linewidth=1,marker='o',s=55,label='test set')
### 画图
X_combined_std=np.vstack((X_train_std,X_test_std))
y_combined=np.hstack((y_train,y_test))
plot_decison_regions(X=X_combined_std,y=y_combined,classifier=svm_model,test_idx=None,resolution=0.02)
plt.xlabel('density [standardized]')
plt.ylabel('ratio[standardized]')
plt.legend(loc='upper left')
plt.show()
得到的SVM模型如图所示:

|
测试的准确率为67%
[1 1 0 0 0 1] [1 0 0 0 0 0]
Misclassified samples:2
Accuracy:0.67
(3)运用高斯核计算
1)高斯核学习函数调用
将(2)的程序中:
svm_model = svm.SVC(C=2,kernel='‘linear",degree=4)
的kernel="linear"修改为kernel=’'rbf"
模型输出如图所示:
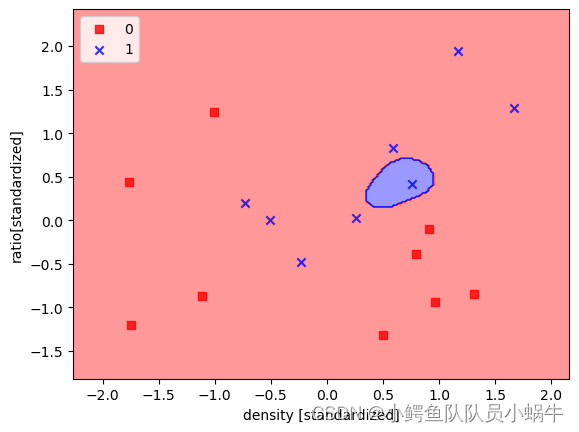
|
预测精度为50%
[1 1 0 0 0 1] [0 0 0 0 0 0]
Misclassified samples:3
Accuracy:0.50
2)缩放样本分布
X_train_std=sc.transform(X_train)/2
X_test_std=sc.transform(X_test)/2

|
[1 1 0 0 0 1] [1 0 0 0 0 0]
Misclassified samples:2
Accuracy:0.67
测试精度为67%,和(2)结果相同。
可以看出,模型的准确度与采用的算法选择与样本模型分布关联度成正比。
4.2 对西瓜数据集3.0 α \alpha α数据进行修改,使之趋向线性可划分,并用线性核和高斯核进行训练SVM。
(1)数据集展示
将4.1中的df_watermelon=pd.read_csv(“D:/ML/3data/watermelon.csv”)
修改为:
df_watermelon=pd.read_csv(“D:/ML/3data/watermelonsimple.csv”)即可。新数据集展示如下:

|
可以看出,两类之间间隔很明显。可以线性化。
(2)运用线性核训练
主程序同4.1(2),只需要将watermelon.csv更换为watermelon.csv
输出模型如图下图所示:

|
可见,两类被完全分开。测试结果如下:
[1 1 0 0 0 1] [1 1 0 0 0 1]
Misclassified samples:0
Accuracy:1.00
精度为100%。
(3)运用高斯核训练
显然,这类数据集分分布状况来看,运用高斯核训练不太合适。
运用4.1(3)的程序运行,得到模型展示如下:
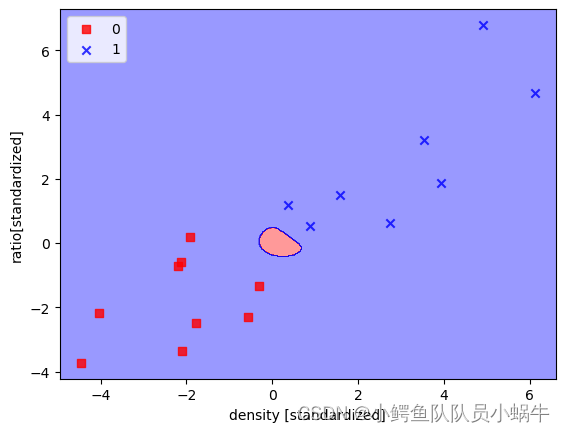
|
测试结果如下:
[1 1 0 0 0 1] [1 1 1 1 1 1]
Misclassified samples:3
Accuracy:0.50
精度为50%。
5 结论
本文描述了支持向量机的核心思想、特点、模型推导,并运用PYTHON进行了不同数据样本的测试,对比了采用线性核以及高斯核进行学习的模型预测精度。
可以看出,在进行模型选择和学习时,最好分析好数据集的分布状况选择合适的数据样本。在数据样本确定情况下,可针对支持向量机核函数模型,进行数据样本的适当变形处理,以便获得更好的学习效果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









