











为了确保机场的安全,必须保护空侧免受未经授权的 访问。为此,通常使⽤安全围栏,但需要定期检查以发现 损坏情况。然⽽,由于⼈类专家⽇益短缺以及⼤量的⼈⼯ ⼯作,因此需要⾃动化⽅法。⽬的是在⾃主机器⼈的帮助 下⾃动检查围栏是否损坏。在这项⼯作中,我们探索对象 检测⽅法来解决围栏检查任务并定位各种类型的损坏。除 了评估四种最先进(SOTA)⽬标检测模型外,我们还分 析了⼏种设计标准的影响,旨在适应特定任务的挑战。这 包括对⽐度调整、超参数优化以及现代主⼲⽹的利⽤。实 验结果表明,我们优化的 You Only Look Once v5 (YOLOv5) 模型达到了四种⽅法中最⾼的准确率,与基线 相⽐,平均精度 (AP) 提⾼了 6.9%。
1.简介

在当今时代,⻜机在全球交通中发挥着⾄关重要的作 ⽤。确保乘客、货物和机械的安全⾮常重要。这需要⻜机 上和机场基础设施内适当的安全机制。保护空侧等敏感区 域是机场运营商⾯临的⼀项重⼤挑战。例如,在德国,有 超过 540 个机场,其中 15 个根据 Luftverkehrsgesetz § 27d 第 1 段被归类为国际机场。为了获得此分类,机场必须遵守 § 8 Luftsicherheitsgesetz (LuftSiG),确保其敏感区域(包 括空侧)免受未经授权的访问1。适当的安全围栏是保护 这些区域的常⻅做法[10]。必须根据 LuftSiG § 8 和 § 9 定期检查这些围栏是否有损坏1。即使围栏受到轻微损 坏,动物也可能进⼊机场,对⾃⼰、⼈员和机器构成危 险。10]。然⽽,执⾏围栏检查的熟练⼈员的可⽤性变得 越来越有限[3]。因此,探索⾃动化⽅法来监控这种现实 世界的监控应⽤,例如利⽤带有摄像头的移动机器⼈来检 测损坏,是⾮常有价值的。
⼀般来说,对象检测⽅法旨在识别和定位输⼊图像内 的特定对象或图案。在这项⼯作中,我们的⽬标是使⽤⾃ 记录的数据集检测在机场捕获的围栏图像中两种常⻅的损 坏类型。图 1 给出了机场围栏的两个⽰例。1。下部设有 铁丝⽹结构作为通道屏障,上部设有多排铁丝⽹⽤于攀爬 防护。两个部分都可能发⽣损坏。然⽽,损坏检测需要清 楚地区分背景中的栅栏和结构。许多区域的适度对⽐度 (例如背景中的树⽊)会使任务变得更加困难。此外,背 景杂乱(例如树叶)使检测过程进⼀步复杂化,尤其是对 于复杂的⾦属丝⽹。为了克服这些挑战,在整个⼯作中检 查了各种技术,包括对⽐度调整。为此,提出了SOTA深 度学习⽅法,即YOLOv5[17 号],任务对⻬的⼀阶段⽬标 检测(TOOD)[11]、VarifocalNet (VFNet) [46],以及可 变形检测变换器 (DETR) [51],对其在解决与安全围栏检 查任务相关的检测挑战⽅⾯的潜⼒进⾏了评估和⽐较。理 想情况下,最终的检测系统应该在移动机器⼈上⾃主⼯ 作。然⽽,这需要在经济实惠的硬件上进⾏可靠的损坏检 测,从⽽实现最经济的操作。因此,我们还研究了速度和 准确性之间的权衡。
2.相关工作
机场围栏的⾃动损坏检测需要计算机视觉(CV)算法[ 12]。在此⽤例中,简单的图像分类⽅法是不够的,导致 ⼈类操作员陷⼊耗时的搜索游戏。另⼀⽅⾯,此任务不需 要精确的分割,因为它不需要每个对象实例线的尾部分割。此外,由⼈类注释者为复杂 的对象(例如线⽹结构)创建分割标签既耗时⼜昂贵[21 ]。因此,对象检测被⽤作分类和分割之间的折衷⽅案。 出于⽬标检测的⽬的,深度学习(DL)⽅法由于层次特 征提取、更⾼的准确度和改进的泛化能⼒⽽⽐经典的 CV ⽅法更加突出。16,27,29,37]。对于⽬标检测⽅法,可以 区分基于锚点的⽅法和⽆锚点的⽅法。基于锚的⽅法通常 收敛得更快,⽽⽆锚的⽅法需要更少的超参数,并且可能 具有更强的泛化能⼒。在本⽂中,使⽤基于锚点的⽅法 YOLOv5 和⽆锚点⽅法 TOOD、VFNet 和 Deformable DETR 来评估这是否属实。
每个对象实例线的尾部分割。此外,由⼈类注释者为复杂 的对象(例如线⽹结构)创建分割标签既耗时⼜昂贵[21 ]。因此,对象检测被⽤作分类和分割之间的折衷⽅案。 出于⽬标检测的⽬的,深度学习(DL)⽅法由于层次特 征提取、更⾼的准确度和改进的泛化能⼒⽽⽐经典的 CV ⽅法更加突出。16,27,29,37]。对于⽬标检测⽅法,可以 区分基于锚点的⽅法和⽆锚点的⽅法。基于锚的⽅法通常 收敛得更快,⽽⽆锚的⽅法需要更少的超参数,并且可能 具有更强的泛化能⼒。在本⽂中,使⽤基于锚点的⽅法 YOLOv5 和⽆锚点⽅法 TOOD、VFNet 和 Deformable DETR 来评估这是否属实。
3.方法论
本⽂深⼊研究了具有不同特征的 SOTA DL ⽅法对损伤 检测任务的适⽤性,并得出了有关设计标准的最佳实践。 详细来说,YOLOv5 [17 号]、TOOD[11], VFNet [46] 和可 变形 DETR [51] 被考虑。在第⼆节激发这些选择之后。 3.1,引⼊了⼀些适应措施来提⾼现实条件下任务的检测 性能。总体⽬标是从定量⻆度确定深度学习⽅法的最佳设 计特征,并进⼀步研究该⽅法对输⼊图像分辨率的影响, 以实现检测结果和计算复杂度之间的有益权衡。
3.1.深度学习⽅法
最近,引⼊了许多新的深度学习⽅法[4,6,11,17 号,46, 51]。在实时物体检测⽅⾯,YOLO⽅法的⼏种衍⽣[20,28 ,34,42] 已被证明适合各种实际应⽤[43,48]。例如, YOLOv5以较低的运营成本实现了良好的检测结果。然 ⽽,YOLOv5 及其前⾝ [1,30,31] 是基于锚点的,这可能会导致泛化能⼒的限制[23]。因此,分析中包含了 两种anchor-free DL⽅法,即TOOD[11] 和 VFNet [46]。 所有这三种⽅法都是作为基于 CNN 的⽅法开发的[11, 17 号,46]。由于基于变压器的模型有望提⾼泛化能⼒[7 ],基于变压器的 Deformable DETR [51],流⾏的基于 Vision Transformer (ViT) 的 DETR 的后继者 [4],正在调 查中。然⽽,ViT 等 Transformer 通常需要⽐卷积神经⽹ 络 (CNN) 更多的训练数据 [44]。由于围栏检查任务的可 ⽤数据有限,需要进⾏进⼀步的调查。
3.2.优化
在这项⼯作中,我们深⼊研究了各种设计参数,以改 进现实环境下安全围栏的损坏检测。下⾯对所考虑的⽅⾯ 进⾏动机和介绍。 数值稳定性:实施深度学习⽅法时,可能会出现数值不稳 定的情况,例如梯度爆炸或零除法。这些数值不稳定性可 能会导致训练结果下降,这就是为什么我们消除它们以提 ⾼实验的意义。我们将代码更改贡献到原始代码存储库。
正则化:深度学习模型的正则化对于防⽌每张图像的感兴 趣区域 (RoI) 很少的⼩型数据集的过度拟合⾄关重要。为 此,主要研究了三种适应性。⾸先,YOLOv5 的图像加权 技术⽤于过度表⽰困难的训练⽰例。由于训练数据集较 ⼩,很少发⽣的边缘情况可能会被良好图像的背景噪声所 覆盖。其次,具有正则化能⼒的优化器,例如 Adam [19 号] 或 AdamW [25] 进⾏调查。为了防⽌梯度振荡,但同 时允许陡峭的梯度下降,我们探讨了学习率调整的影响。
数据增强:数据增强⽅法旨在增加⼩规模数据集的多样 性,以防⽌过度拟合并提⾼鲁棒性。由于数据量⼩且损坏 很少,因此研究了⻢赛克和仿射变换等数据增强⽅法的影 响。
对⽐度增强:对⽐度差(例如由⻩昏或黎明期间的弱光引 起)对检测机场围栏损坏提出了重⼤挑战。在这种情况 下,栅栏的精细结构在背景下并不明显。在损伤检测之前 使⽤对⽐度增强⽅法对图像进⾏预处理可以缓解这个问 题。对⽐度调整⼀般可以对整个图像进⾏,也可以对多个 图像区域分别进⾏。我们⽐较全局和局部对⽐度增强以直⽅图均衡(HistEqu)为代表的⽅法[35,36] 和对⽐度 受限⾃适应直⽅图均衡 (CLAHE) [52], 分别。 ⻣⼲:虽 然 YOLOv5 使⽤现代 CSPDarknet [38,39] 作为⻣⼲[17 号]、TOOD 和 VFNet 依赖于残差⽹络 (ResNet) 的变体 [ 15] 和 ResNeXt [41] 架构。然⽽,最近的⻣⼲⽹如 Res2Net [13] 或 ConvNeXt [24] 在各种任务中表现出更 好的表现[47,49]。因此,这些主⼲⽹与 TOOD 和 VFNet 结合应⽤。与原始主⼲类似,我们⾸先在 COCO 数据集 上预训练这些主⼲。
超参数调整:选择适当的超参数对于确保良好的性能⾄关 重要,特别是在可⽤训练数据很少的情况下。此外,围栏 检查任务需要较强的泛化能⼒。由于条件和需求的不同, 原始作品提出的超参数在损伤检测中可能不是最优的。因 此,对超参数的选择进⾏了详细的研究。 图像分辨率: 当物体检测器部署在现实世界的应⽤中时,快速计算⾄关 重要。例如,如果处理是在机器⼈等⾃主平台上执⾏的。 物体检测器的推理速度很⼤程度上受输⼊图像分辨率的影 响。更⾼分辨率的图像提供了更详细的背景,可以改进损 坏检测,同时计算复杂性也会增加。因此,在检测精度和 计算要求之间实现适当的权衡⾄关重要。
4. 实验
为了获得最⼤的可重复性,硬件和软件堆栈在所有实 验期间保持不变。 YOLOv5 (v6.2) 的官⽅实现 [17 号] 和 MMDetection (MMDet) (v2.25.1) [5] 被⽤作我们的调整 和实验的基础。然后使⽤ Nvidia 的 A6000 GPU 和英特尔 的 Xeon Silver 4210R CPU 执⾏这些⽅法。
4.1.数据集和评估指标
由于该任务没有公开可⽤的数据集,因此创建了机场 围栏损坏的数据集。因此,不同部分的视频序列是使⽤两 种不同的相机型号记录的,即FLIR2相机型号和松下GH53 。总共记录了 5 个数据集,其中 3 个使⽤ FLIR,2 个使⽤ GH5 相机。然后对所有有损坏的图像进⾏标记,没有损 坏的图像被整理出来,不再进⼀步考虑。这会产⽣ 5 个视 频序列,总共 475 个视频 框架和 725 个带注释的损坏,分为 104 个翻越缺陷和 621 个孔。 FLIR 相机记录的图像分辨率为1920年×1200 以及那些拥有 GH5 相机的1920年×1080、分别。
这项⼯作考虑了三种不同的情况,每种情况都反映了 另⼀种现实世界的场景。这些案例在训练、验证和测试数 据⽅⾯有所不同,如表 1 所⽰。1。案例 1 是来⾃应⽤程 序中使⽤的确切相机的训练数据可⽤时的专业化案例。案 例 2 评估泛化性能,因为训练和测试数据源⾃具有不同特 征的不同相机模型。在最后⼀个案例 3 中,来⾃两个相机 模型的数据⽤于所有分割,以评估当不同数据可⽤于训练 时的情况。
为了确保有意义的评估结果,在三个研究案例中的每 ⼀个中都执⾏留⼀交叉验证(LOOCV),以补偿数据集 的⼩规模。在每个分割中,利⽤另⼀个视频序列进⾏训 练,从⽽产⽣ 12 个分割。
可可美联社[22] 作为评估和验证的主要指标。给出的 结果代表所有三种情况的平均值,并将缩写为 Avg。美联 社在下⾯的。
4.2.基线
每种⽅法的基线均在 12 次留⼀交叉验证 (LOOCV) 分 割上进⾏评估。为此,对⽅法的原始实现进⾏了轻微修 改。对于 YOLOv5,只有 Pytorch 推荐的重现性措施4添 加。这确保了实验更好的可⽐性。不幸的是,这对于 MMDet 2.25.1 中的其他三种⽅法来说是不可能的。尽管 如此,为了减少训练运⾏之间的标准偏差并能够进⾏更有 意义的⽐较,对每个数据分割进⾏了三次运⾏。为了训 练,对原始配置进⾏了四处更改。⾸先,批量⼤⼩从 32 减少到 8,以允许更快的梯度下降训练。其次,为了减少 训练期间指标验证曲线的振荡,学习率降低到 5e-2。第 三,为了训练收敛,纪元数量必须加倍。第四个也是最后 ⼀个,使⽤ FP16 内置训练来实现更快的训练和更低的内 存消耗。
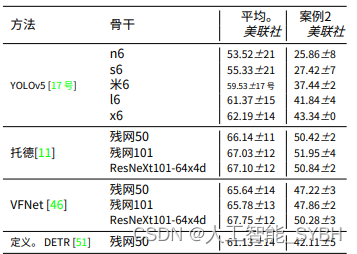
对于所有模型,都使⽤预先训练的 COCO 模型。然后 使⽤栅栏检查数据集对模型进⾏微调,将最⻓图像边的分 辨率调整为 768 像素。标签。2提供四种⽅法的基线结 果。
结果表明 TOOD 和 VFNet 提供了最好的结果,达到 67.10%美联社67.75%美联社。YOLOv5 的结果更差,为 62.19%美联社,但仍然超过 Deformable DETR 2.06%。 Deformable DETR 精度差的原因之⼀可能是训练数据有 限,这是 Transformer 的⼀个普遍问题。由于 Deformable DETR 的效率由于其基于 Transformer 的结 构⽽明显⽐ YOLOv5 差,因此在本⽂的其余部分中不再进 ⼀步考虑 Deformable DETR ⽅法。 YOLOv5 效果较差的 原因之⼀是泛化能⼒⽋佳。⽐较表 2 中案例 2 的结果。2 ,很明显,⽆锚 TOOD 和 VFNet ⽅法对未⻅过的数据的 泛化能⼒⾮常强。尽管在后续章节中进⾏了优化, YOLOv5 的这⼀弱点是否仍然存在,将在第 2 节中进⾏研 究。
4.3.正则化
训练基线后,对其余三种⽅法进⾏优化。我们调整了 YOLOv5 的实现,以实现矩形图像训练与随机洗牌和⻢赛 克数据增强相结合的训练。17 号]。此外,事实证明,不 同的超参数设置有利于 YOLOv5 的 m6、l6 和 x6 变体更 好地收敛到全局最优值并防⽌过度拟合。⼀⽅⾯, OneCycle学习率[33] 从 1e-4 增加到 1e-3,以实现更快 的收敛
更深的模型 m6、l6 和 x6,可以更好地利⽤梯度优化中的 爬⼭特性。其次,采⽤更多的数据增强来增强正则化。为 此,图像缩放的百分⽐从 [-50%,+50%]到 [-90%,+ 90%]。此外,MixUp [45] 以 10% 的概率应⽤。对于 TOOD 和 VFNet,没有观察到显着的增强。


优化后的 YOLOv5 结果如表 1 所⽰。3。结果显着超过 基线结果。这是由于通过⻢赛克数据增强训练期间数据的 多样性增加,以及针对洗牌引⼊的过度拟合的进⼀步正则 化。总的来说,这些调整使性能提⾼了 3.86 个百分点。 美联社在⽐较最佳配置时。不过,最好的模型不是最⼤的 x6,⽽是l6。 x6 模型容易过度拟合,并且表现明显较 差,为 64.85%美联社。即使增加数据增强和额外的正则 化也⽆法弥补这⼀点。因此,下⽂采⽤YOLOv5l6作为最 佳模型。
4.4.对⽐度调整
表 2 ⽐较了 CLAHE 和 HistEqu 两种对⽐度调整⽅法。 4。结果表明,⽆论检测⽅法如何,全局⽅法 HistEqu 都 具有卓越的性能。造成这种情况的原因之⼀可能是某些地 区的 CLAHE 过度调整。特别是关于泛化案例 2 的更糟糕 的结果⽀持了这⼀假设。由于 GH5 图像已经显⽰

对⽐度良好,额外的对⽐度调整会导致过度调整。如图。 2可视化 GH5 相机捕获的图像的两种⽅法之间的差异。 CLAHE⽅法,如图1所⽰。2b,与 HistEqu 相⽐,明显过 度调整,如图 2 所⽰。2c。这些过度拟合发⽣在明暗像素 差异较⼤的区域,例如树⽊和天空。这会导致图像外观⾮ 常不⾃然。结果,栅栏结构的某些部分⼏乎难以辨认。
4.5.超参数优化
使⽤ HistEqu 预处理来优化超参数。与正则化类似, MMDet 实现⽅法 TOOD 和 VFNet 没有提供显着改进的结 果。因此,超参数优化主要集中在YOLOv5上。我们发现 选择 5e-3 的学习率并应⽤图像加权结果是有益的。这种 ⼿动超参数优化增加了美联社从 67.16% 到 68.45%。此 外,冻结⻣⼲不同阶段的众多设置,以及 Adam 的使⽤ [ 19 号] 和 AdamW [25] 作为优化器的评估,以实现更强的 正则化,从⽽实现更稳定的训练。我们还评估了有关仿射 变换的⼏种设置,以实现更⾼的泛化。然⽽,上述调整均 未带来显着改善的结果。
此后,进⾏⾃动超参数调整。⾸先,使⽤了所有 12 个 LOOCV 分割的所有先前内部评估,以及平均值之间的⽪ 尔逊相关系数美联社跨越分裂和 美联社确定了每个单独 的分割。随后,确定与平均值最相关的分割 美联社超过 所有分裂。这种分割可⽤于⾃动超参数调整。
在 YOLOv5 中,除了⼀些更改之外,在预定义配置中进⾏ ⾃动超参数优化。根据我们之前的发现,我们减少了定义 的搜索空间并排除了仿射变换旋转、剪切、透视和翻转, 因为它们的使⽤会导致显着的退化。最后,使⽤剩余的 21 个超参数执⾏ 500 次迭代的⾃动超参数调整。在每次 迭代中,根据 GA 策略对⼀个或多个超参数调整进⾏采 样,然后在完整的训练运⾏中进⾏评估,⽽⽆需提前停 ⽌。最显着的效果是将⻢赛克数据增强的概率从 100% 降 低到 91.5%,因为⽹络需要原始数据来捕获固有结构。此 外,增加 ColorJitter 增强中饱和度的变化[-70%,+70%] 到 [-89%,+89%]导致显着改善。优化后的模型总共达到 了 69.09%美联社所有数据分割的平均值。
4.6.⻣⼲
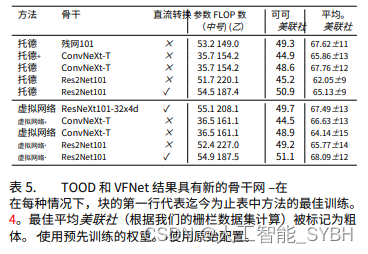
超参数调整后,现代 SOTA 主⼲⽹将与 TOOD 和 VFNet 结合进⾏评估。此外,还检查了在 Res2Net 架构 中使⽤ DConv 的影响。迄今为⽌最好的模型和新的预训 练模型的结果在表中给出。5。对于每次训练课程,美联 社除了以下内容之外,还介绍了 COCO 数据集上的预训 练⽹络美联社对于我们的数据集。例如,就 TOOD ⽽ ⾔,COCO 上最好的预训练⽹络不⼀定是我们数据集上最 好的⽹络。这是因为 COCO 数据集中的类和类语义与本 ⼯作中的类和类语义有很⼤偏差。然⽽,当进⼀步考虑⻣ ⼲⽹前景不佳时,它提供了⼀个粗略的指⽰。研究结果表 明,TOOD 与 ConvNeXt 结合使⽤可以达到最⾼的准确 率。对于VFNet,作为⻣⼲的Res2Net表现最好。尽管新 主⼲⽹的准确率有了显着提⾼,但 TOOD 和 VFNet 在以 下⽅⾯并未超越 YOLOv5:美联社。

由于 YOLOv5 由于其设计为实时⽬标检测器⽽具有更⾼的 资源效率,因此 YOLOv5 被选为最佳模型并在本⽂的其余 部分中使⽤。
4.7.深⼊分析
到⽬前为⽌,所有分析均已通过美联社 跨越所有类型 的失败。这⽐基线取得了显着进步,进步了 6.9%。本节 深⼊研究了所建议的优化的效果,以确定系统的优点和缺 点。 围栏缺陷类型及⾯积⼤⼩:标签。6研究了 YOLOv5 每种缺陷类型和不同损坏⼤⼩的结果。为此,根据像素覆 盖⾯积将损坏分为三类。⼤⼩不超过 24,000 像素的损坏 被视为很⼩。相应地,损伤范围为24,000像素⾄100,000 像素,超过100,000像素为中损伤和⼤损伤。因此,8% 的损害为⼩型损害,77% 为中等损害,15% 为⼩型损 害。⼀般来说,美联社 优化减少了损坏类型之间的差 异。不过,差距仍然达到了相当⼤的24.87%。对越轨保 护缺陷的更强检测可以通过其特征外观和视⻆来解释。通 常,损坏发⽣在明亮的天空前⾯,因此即使在照明条件不 佳的情况下,也能很好地与背景区分开来(⻅图 1)。1 )。相⽐之下,⾦属丝⽹的对⽐度较差。基线中的下⼀个 显着特征是⼤孔的标准偏差⾮常⾼,为 41。这⼀发现表 明泛化能⼒不稳定,并且对训练和验证数据有很⼤的依赖 性。造成这种情况的原因之⼀是,在美联社⼤的,孔在 500,000 像素以内⼏乎呈正态分布。因此,使⽤很少的⼤ 框进⾏训练分割可能会超出基线对使⽤⼤框进⾏评估分割 的泛化能⼒。


最后⼀步,我们评估我们的模型在进⼀步围栏、相机 模型和天⽓条件中的可移植性,以确定未来研究的优势和 ⽅向。为此,它被应⽤于机场围栏的外部、免费图像。结 果如图 1 所⽰。4。如图所⽰,并⾮所有围栏都有损坏。 例如,在图中。4a,栅栏上添加了新的模块,以⽅便穿 过栅栏进⾏拍摄,并避免⻜机观察员在栅栏上挖洞。我们 的⽅法不会将这些孔检测为损坏,即它可以正常⼯作。⽐ 数据集中包含的⼤洞也能被正确检测到,如图 1 所⽰。4c 和图。4b。识别出的是两个孔,⽽不是图 1 中的⼀个。 4c。然⽽,这在现实应⽤中不是问题,因为只有特定位置 发⽣的损坏才相关。与上述⽰例相反,图 1 中所⽰的孔。 4e具有不同的形状,因此我们的⽅法⽆法检测到。未来 的⼯作可能会考虑有关训练数据集中包含的孔形状的更多 变化。

5. 结论
在⼯作范围内,对四种深度学习⽅法 YOLOv5、 TOOD、VFNet 和 Deformable DETR 进⾏了⽐较,以研 究⼩型数据集上机场围栏检查的新设计规则,这是有史以 来的第⼀份出版物。总之,Deformable DETR 作为基于 Transformer 的模型,由于数据量太少且精度明显较低, 因此没有任何价值。 TOOD 和 VFNet 可以通过 ConvNeXt 和 Res2Net 等现代 SOTA 主⼲⽹实现更⾼的 精度,但⽆法达到 YOLOv5 的精度和效率。此外,我们还 可以证明 YOLOv5 对外部数据也提供了良好的泛化能⼒。
为了提⾼围栏分析的准确性,将围栏与周围环境分开 将是有益的。尽管标记如此精细的结构⾮常耗时,但使⽤ ⽴体或 RGB-D 相机进⾏记录可以提供附加信息,将栅栏 结构与背景分开。此外,夜视摄像机可⽤于夜间检查,例 如⽐被动摄像机具有更⾼对⽐度的红外摄像机。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











