







目录
前言
Agent,是为了激发LLM自身的推理能力而生的技术,通过分解问题、制定计划、角色设定等方式最大限度利用LLM的推理能力,减少幻觉提高回答正确率。
其实Agent本质上还是写prompt,还是需要prompt工程来具体实现每个步骤。如果比较两者,Agent就是细化的prompt工程,如果说使用标准prompt回答问题是一锤子买卖,那么Agent就是在回答问题时加入思考、分解、规划、反馈等细分步骤逐步解决问题,这些步骤是称之为智能体的根本,在行动后感知环境、根据环境反馈调整行动,不断纠错,不断抵近答案。
ReAct是一种简单的Agent,本文从论文和源码层面解读初代Agent模型ReAct的思想和实现细节,如果不是很熟悉常用的prompt工程,可以阅读这篇blog【一篇就足够】全面总结Prompt工程的理论、实践与挑战
一、ReAct的论文和源码
论文:REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
二、ReAct的思想和理论
作者提出了之前研究的两个现存问题:
1. 只单独研究LLM的的推理能力(如COT)或行动能力(如行动计划生成),没有将两者结合起来。
2. 动态决策能力不足:LLM在面对动态环境时,缺乏有效的决策能力,导致处理复杂问题时的效率和准确性下降。
针对以上问题,ReAct做出如下改进:
1. 将LLM的推理能力和行动能力以交替的方式结合起来,探究两者结合的效果。
2. 允许LLM调用外部工具来收集更准确的信息。
ReAct的主要行为有:Action、Thought和Observation(行动、思考、观察)
为了更直观理解,从下面这张图中看以往工作和ReAct的区别:
其中,以往工作包括:Standard prompt、CoT和Act-only,和ReAct的区别在于:
1. Standard prompt:只输入问题。
2. CoT:回答中只保留Thought。
3. Act-only:回答中只保留Action和Observation。
4. ReAct:回答中保留Thought、Action和Observation。

ReAct有效的根本原因:
从上图可以看出,ReAct在LLM中加入了对当前observation的思考推理,然后来引导接下来的Action。那么为什么加入思考会比只action+observation的Act-only效果好呢?

翻译过来就是如果只进行action+observation,在进行 t 轮之后,LLM根据之前 t 轮的(a, o)上下文决定接下来的action是很困难的,因为这涉及大量的隐式计算,很容易出错。
ReAct是怎么解决这个问题的呢?

它通过在每轮的(a, o)中选择性的插入thought,让LLM对此次action后的observation进行总结和思考,然后制定接下来的action,也就是从observation中提取关键信息,从而调整行动计划,显式地注入与任务解决相关的常识性知识。简单来说就是在上下文中加入thought后,LLM在进行下一步行动时可以显式地知道之前每一步的行为依据,从而获得更多支撑决策的信息,提高行动准确率。
在Act-only中action和observation是交替进行的,那thought该插入到什么位置呢?ReAct的方式是让LLM自行决定,让thought稀疏地出现在最相关的位置,这个很考验LLM对问题的理解能力。
聊到这,总结一下ReAct的特点:
1. 易于设计prompt:设计ReAct的提示非常简单,注释者只需在下一步的行动前插入采取这步行动的思考即可。
2. 通用性和灵活性:ReAct适用于不同推理需求的任务,包括QA、事实验证、文本游戏、网页导航等。
3. 高性能和鲁棒性:ReAct从仅一到六个上下文示例的prompt中学习时,对新任务显示出强大的泛化;并且在fine-tuning后在所有任务上达到Sota。
4. 与人类一致和可控:ReAct提供了一个透明的的决策和推理过程,可以很容易地检查推理和事实的正确性。因此,还可以通过手动纠错来纠正Agent的行为。
三、从源码看ReAct的具体实现
不知道有没有跟我一样的小伙伴,每次看懂了论文但对代码实现却没有概念,所以想要真正掌握一门技术还是要去看代码实现。(为了能运行起来改了部分设置,所以和源码有一些不同,但主要功能代码相同)
接下来从数据集、prompt工程和代码三个方面来分析ReAct的实施细节。
因为主要围绕HotPotQA任务介绍源码,所以后续只介绍HotPotQA任务设计的prompt,其他任务的设计类似。
1. 数据集
ReAct挑选了四个数据集,分别对应了两类任务的四个场景:
知识密集型推理任务:
1. HotPotQA:一个多跳问答数据集,需要多个维基百科文章进行推理。
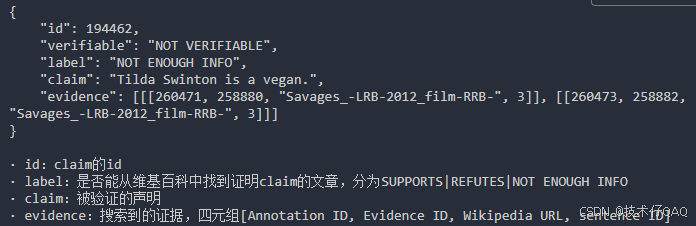
2. FEVER:一个事实验证数据集,其中每个claim都标有"SUPPORTS", "REFUTES"或者 "NOT ENOUGH INFO"的注释,基于是否存在维基百科文章来验证该claim。
决策任务:
1. ALFWorld:一个基于文本和具体环境的互动式数据集。
2. WebShop:一个在线购物的数据集,要求Agent根据用户指令正确购买产品。其中包含118万个真实产品和12k个人类指令,与ALFWorld不同,Webshop包含网页中的各种结构化和非结构化文本(例如产品标题、描述和从亚马逊抓取的选项)
为了更容易理解,在每一个数据集中挑选一个例子:
1. HotPotQA:A dataset for diverse, explainable multi-hop question answering
给出一个问题,然后通过search、lookup和finish工作来一步步推理答案。
ReAct推理过程:
2. FEVER:https://arxiv.org/abs/1803.05355
ReAct推理过程:
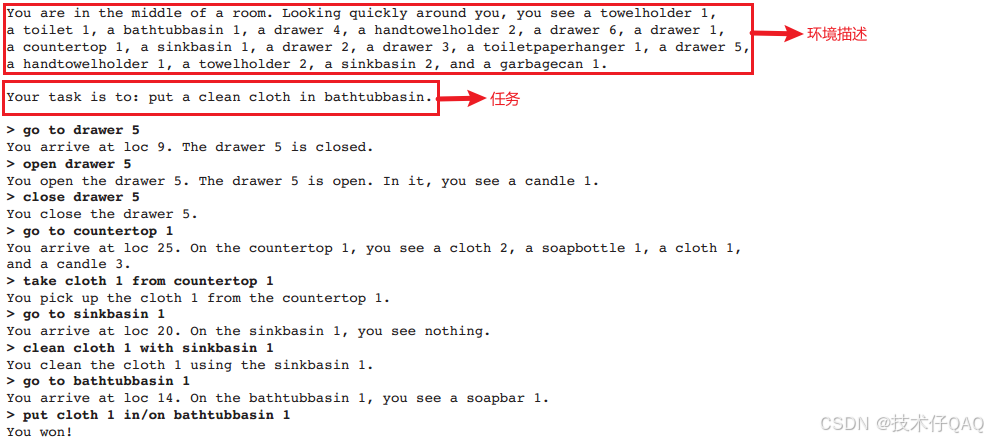
3. ALFWorld:Alfworld: Aligning text and embodied environments for interactive learning
数据集中包括当前的环境描述和任务。
LLM首先需要感知周围环境,然后通过一系列可选择的Action一步步完成推理。
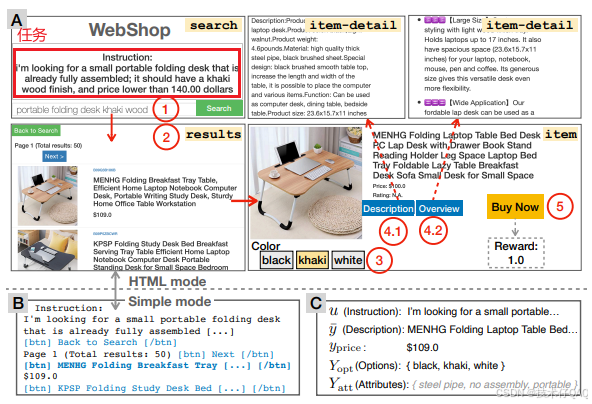
4. WebShop:WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
这个数据集的数据有些复杂,所以直接放一张示例图,便于理解:
首先给LLM一个用户的购买任务,然后LLM通过search、click等动作分析当前页面,决定下一步动作直至买到正确物品。



2. 源码结构
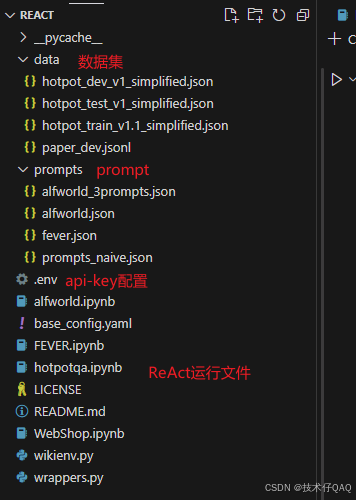
执行HotPotQA任务的总体流程:配置api文件—设置prompt—设置Wikipedia环境—输入问题进入ReAct流程。
3. LLM api配置
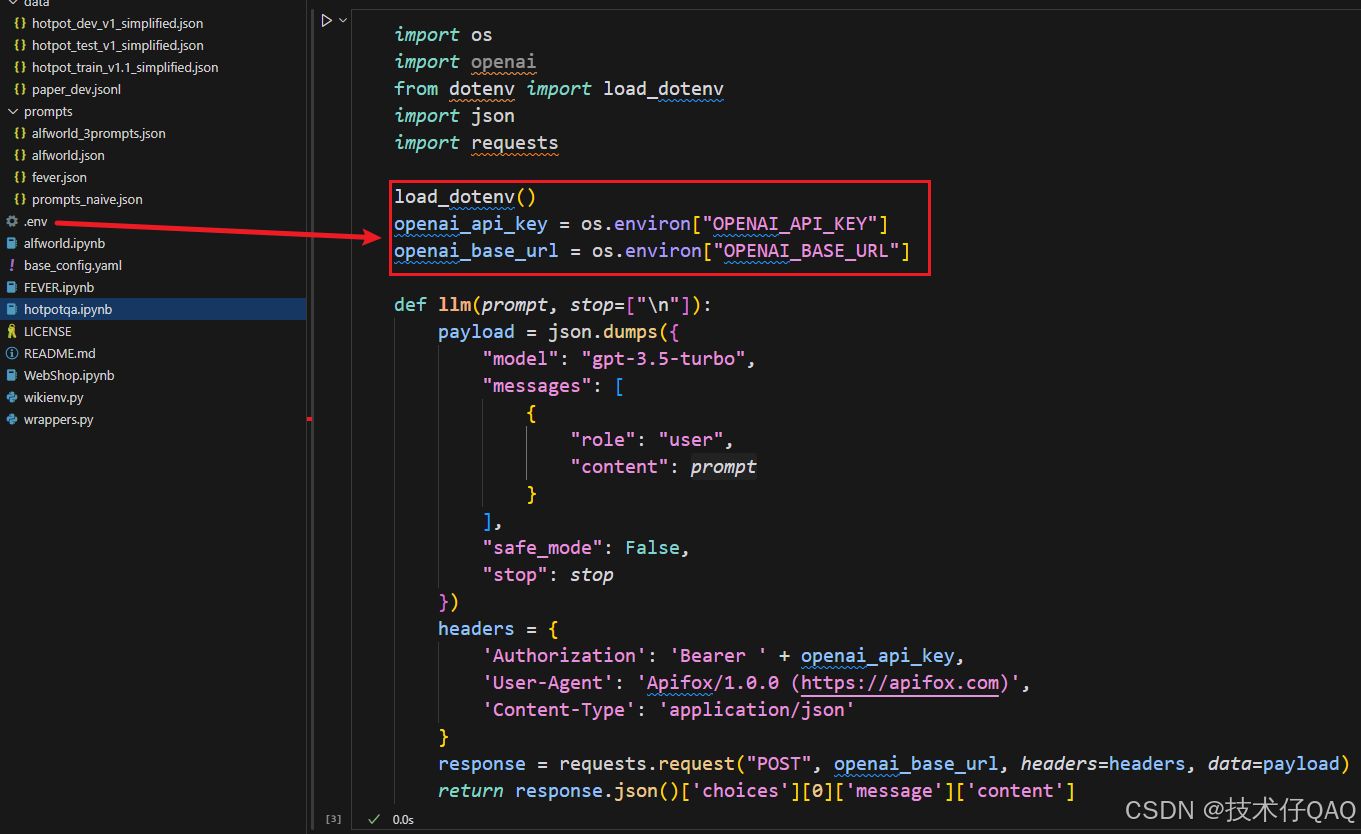
自行创建一个.env文件,文件内容如下:

配置好后,llm函数用于回答prompt:
(可以自定义llm函数,这里用的第三方api所以输入url)
4. prompt设计
论文中关于prompt设计提到,参考few-shot范式,人工注释6个case作为shot放入prompt中,case的格式和上述数据集的推理过程一致。
prompt源码:
instruction = """Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation, and Action can be three types:
(1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it will return some similar entities to search.
(2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
(3) Finish[answer], which returns the answer and finishes the task.
Here are some examples.
"""
webthink_prompt = instruction + webthink_examples
其中webthink_examples是人工注释的6-shot,太长就不放在这里了,只给出一个shot作为例子:
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?\n
Thought 1: I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same.\n
Action 1: Search[Pavel Urysohn]\n
Observation 1: Pavel Samuilovich Urysohn (February 3, 1898 and August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory.\n
Thought 2: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and find its type of work.\n
Action 2: Search[Leonid Levin]\n
Observation 2: Leonid Anatolievich Levin is a Soviet-American mathematician and computer scientist. \n
Thought 3: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work. \n
Action 3: Finish[yes]\n
可以看出ReAct的prompt有点类似于few-shot+Agent的形式,给几个工具供LLM自行调用。
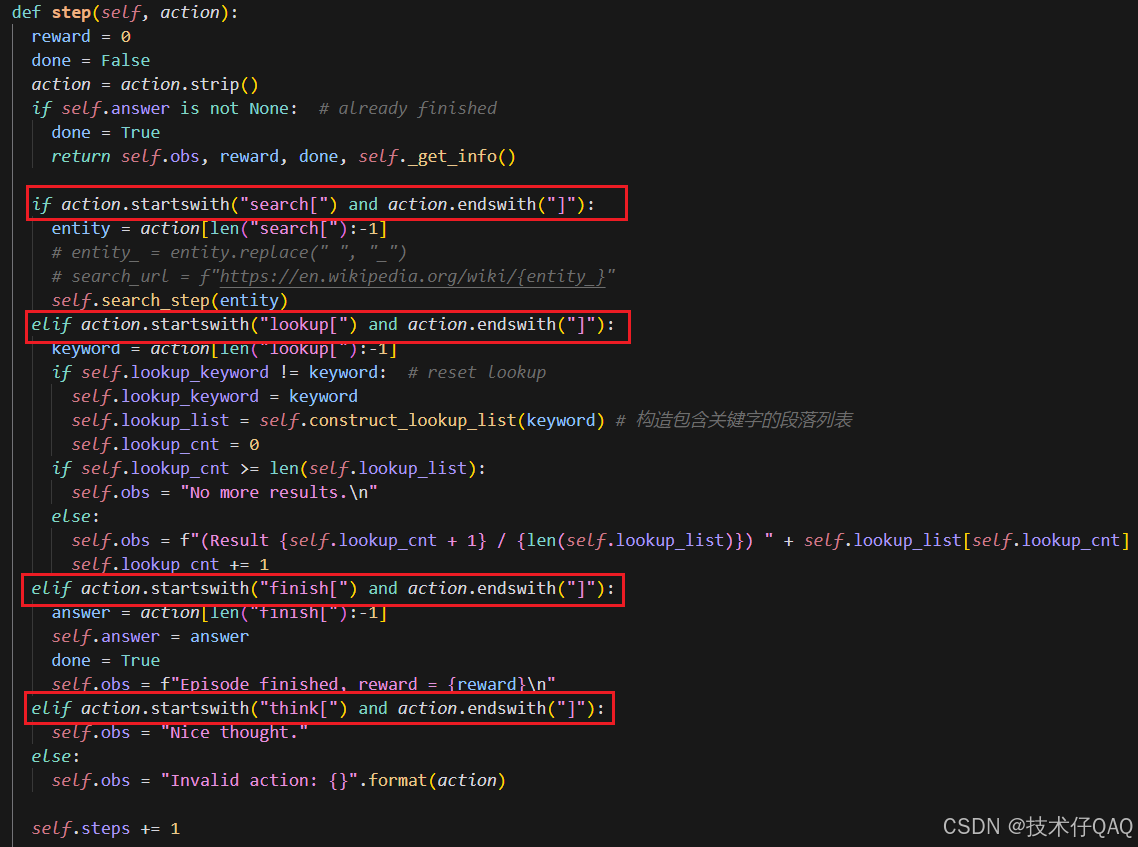
5. Action类型
HotPotQA的action有三个:
1. search[entity]:如果存在对应的实体wiki页面,则返回前5个句子作为observation输入给LLM,如果没有找到wiki页面就从网页中提取前5个最相似的实体。
2. lookup[string]:返回页面中包含string的下一个句子,模拟浏览器上的Ctrl+F功能。
3. finish[answer]:用answer完成当前任务。
6. ReAct核心代码
ReAct的核心函数如下:
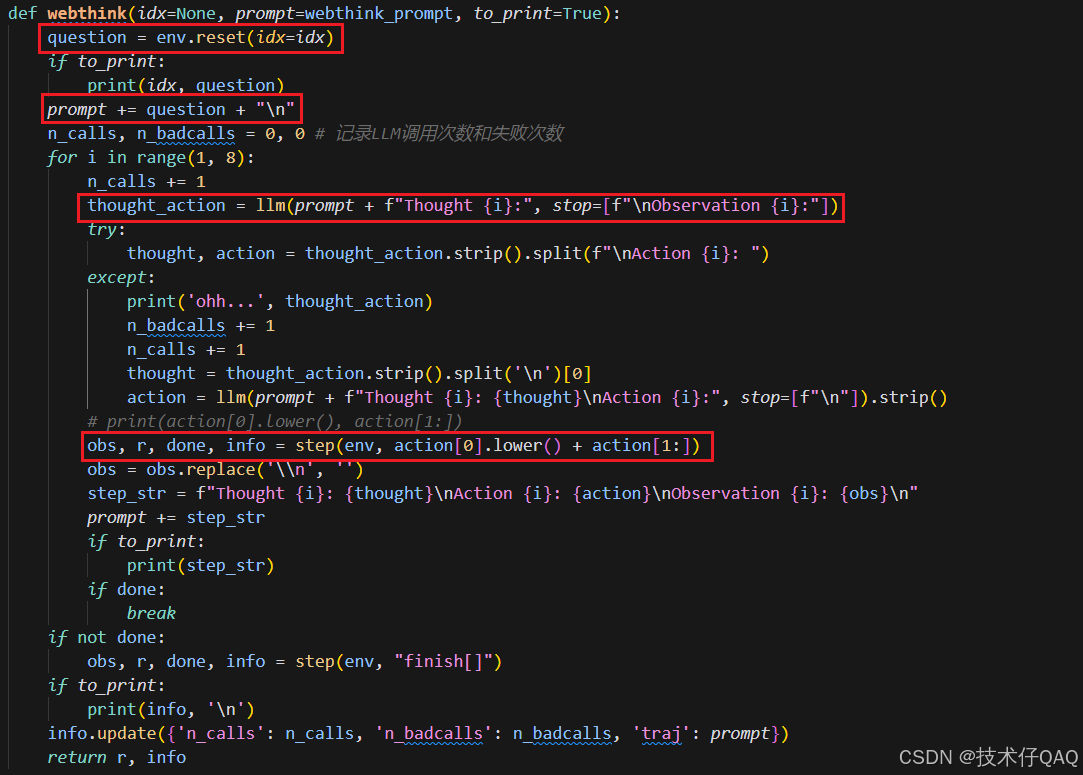
输入question+prompt后,LLM遵循提示中回答规律对问题进行思考、行动和观察,最大执行8轮,如果8轮后仍没有获得正确答案,则最后输出finish[ ]。
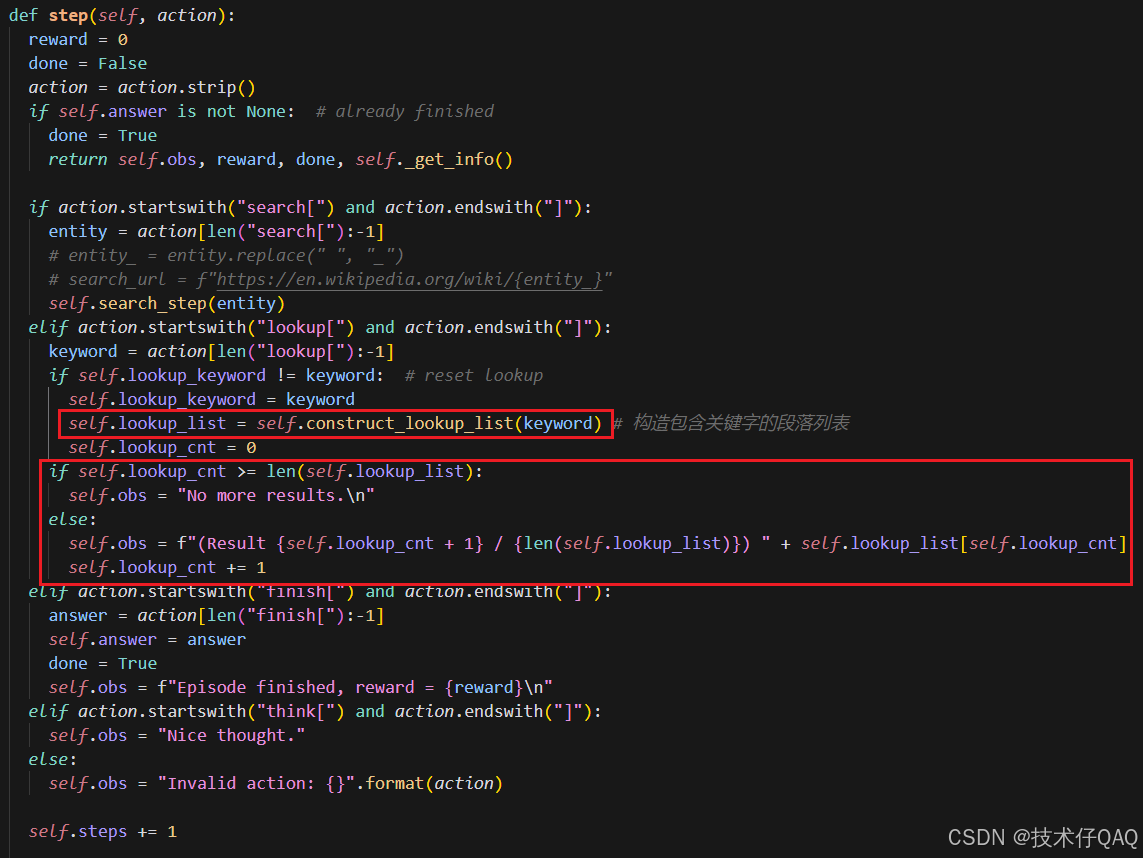
其中step函数根据action类型选择不同的操作:
其中search的实现逻辑如下:
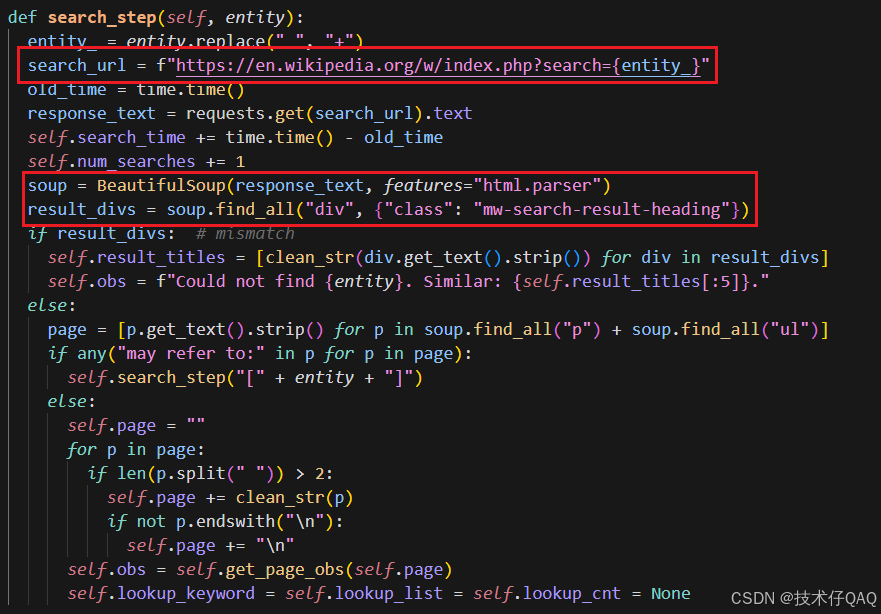
首先发送http请求得到页面的html代内容,如果result_divs=[]也就是没有搜索到entity对应的网页,则挑选与该entity最相关的前五个页面加入observation,然后思考下一步行动。没有接触过Wikipedia页面的同学可能不太熟悉这是一种什么情况,下面这张图展示了在Wikipedia中没有搜索到"Corliss+Archer+Kiss+and+Tell"的情况:
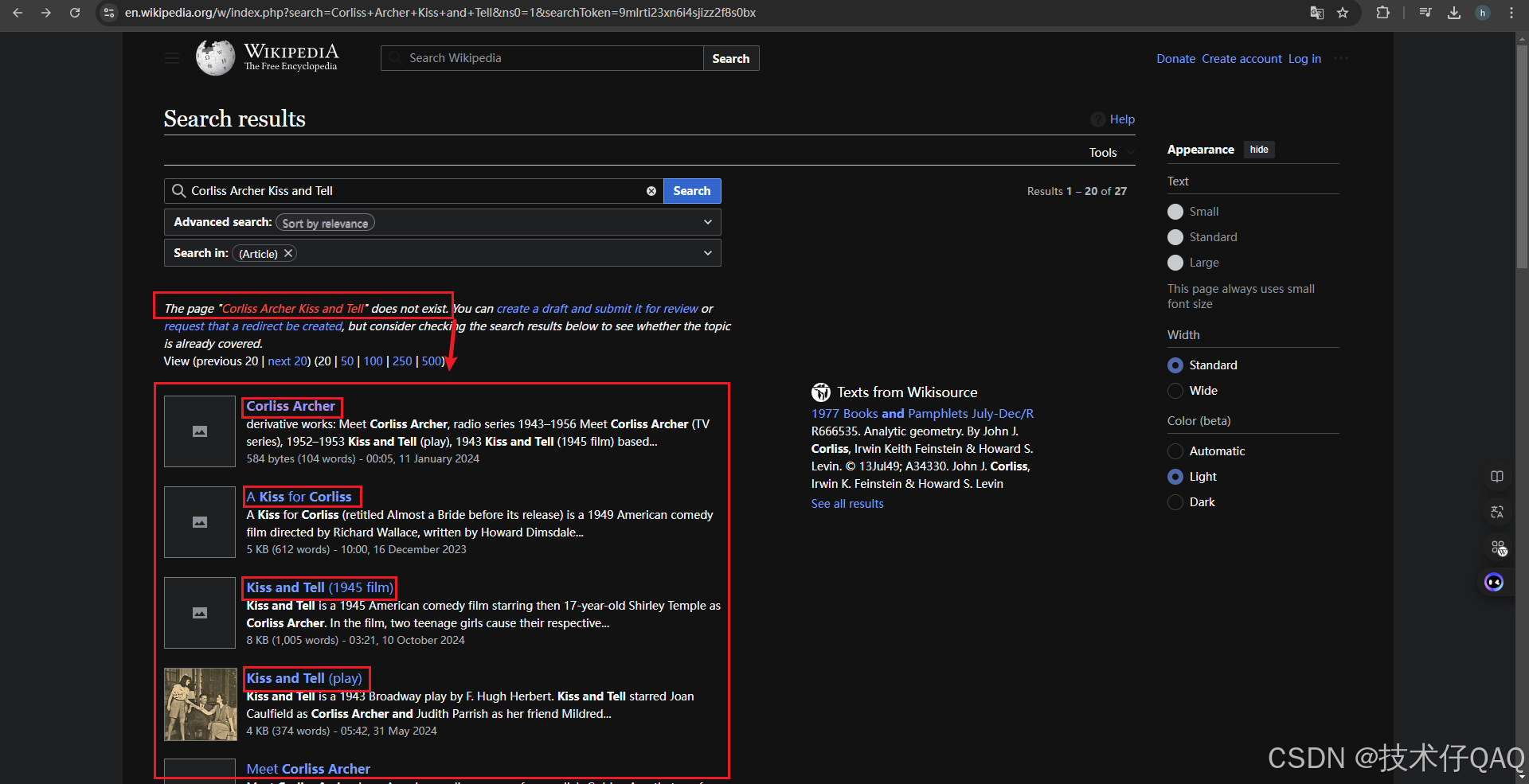
没有搜索到的话会给出相关页面,将前五个页面的标题加入到observation中,然后下一步思考以哪一个标题作为entity进行下一次search动作。
当然,如果找到了相关内容,就把<p>和<ul>标签中的文字全部提取并存储起来。
那么lookup的实现逻辑是什么?lookup需要基于成功search到Wikipedia页面之后执行,search成功后,LLM思考接下来需要进一步search还是在当前页面根据关键字寻找信息,根据关键字就需要lookup了,相当于在页面模拟Ctrl+F的功能。例如,question:“奥巴马的老婆是谁?”,首先LLMsearch到奥巴马的Wikipedia页面,然后调用lookup[“老婆”]就能定位到页面中包含“老婆”的这句话,将这句话lookup到LLM中,LLM就可以根据查询到的这句话找到老婆是谁了。
来看眼lookup的代码实现逻辑:
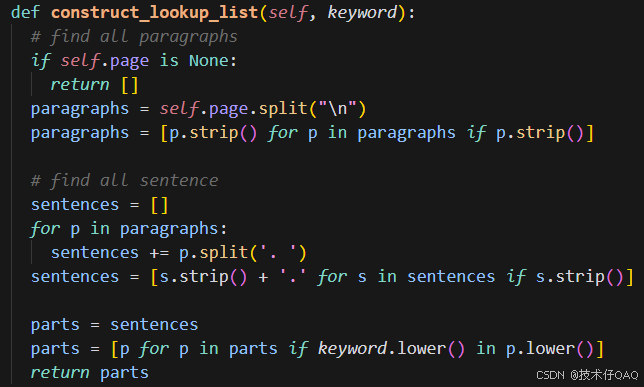
将“老婆”作为keyword输入到函数中,然后将当前页面的所有内容划分成句子,然后找到包含关键字的句子集合,返回这个集合到调用lookup的函数,然后选取集合的第一个句子(相当于Ctrl+F定位的第一个句子)作为observation返回给LLM:
finish操作就由LLM自己来决定了,最终找到或者没找到答案都由LLM自己决定何时输出finish。(按前面提到的,最多循环8轮必须要结束)
7. ReAct的回答实例演示
为了让大家更清晰看到执行过程,我挑选了一个问题进行测试,最终LLM自己判断无法找到正确答案,过程如下:
Question: What government position was held by the woman who portrayed Corliss Archer in the film Kiss and Tell?
Thought 1: I need to search for the woman who portrayed Corliss Archer in the film Kiss and Tell and find out what government position she held.
Action 1: Search[Corliss Archer Kiss and Tell actress]
Observation 1: Could not find Corliss Archer Kiss and Tell actress. Similar: ['Janet Waldo (category 20th-century American actresses)', 'Shirley Temple filmography (redirect from Shirley Temple filmography, features and short subjects)', 'Kathryn Card (category American radio actresses)', 'F. Hugh Herbert (category 20th-century Austrian dramatists and playwrights)', 'Joan Caulfield (category American film actresses)'].
Thought 2: I should search for the actress who portrayed Corliss Archer in the film Kiss and Tell, maybe searching Janet Waldo will give me the information I need.
Action 2: Search[Janet Waldo]
Observation 2: Janet Waldo (born Jeanette Marie Waldo; February 4, 1919[1] – June 12, 2016)[2] was an American radio and voice actress.[3] In animation, she voiced Judy Jetson in various Hanna-Barbera media, Nancy in Shazzan, Penelope Pitstop, Princess from Battle of the Planets, and Josie in Josie and the Pussycats. On radio, she was the title character in Meet Corliss Archer.. Jeanette Marie Waldo was born in Yakima, Washington.[4] Her mother, Jane Althea Blodgett, was a singer trained at the Boston Conservatory of Music, and her father, Benjamin Franklin Waldo, was, according to Waldo family lore, a distant cousin of Ralph Waldo Emerson. She had three older siblings, one of whom, Elisabeth, is an authority on pre-Columbian music and an award-winning composer-violinist who appeared in the film Song of Mexico (1945).[5] She attended the University of Washington, where her performance in a student theatrical garnered her an award and brought her to the attention of Bing Crosby. A Paramount Pictures talent scout, who was with Crosby at the time, signed Waldo for a screen test, which led to a contract with the studio.[3].
Thought 3: Janet Waldo portrayed Corliss Archer in the film Kiss and Tell, so I need to find out what government position she held.
Action 3: Lookup[government position]
Observation 3: No more results.
Thought 4: There is no information about the government position held by Janet Waldo. Maybe searching for another source or keyword related to her will provide the answer.
Action 4: Search[Janet Waldo government position]
Observation 4: Could not find Janet Waldo government position. Similar: ['Black Mirror', "Emerson's letter to Martin Van Buren (category Works by Ralph Waldo Emerson)", 'List of Encyclopædia Britannica Films titles', 'Quill and Dagger', 'John F. Kennedy assassination conspiracy theories (section Shadow government conspiracy)']. ohh... Unfortunately, I could not find information about the government position held by Janet Waldo. This task may require further research outside of the provided information.
Thought 5: Unfortunately, I could not find information about the government position held by Janet Waldo. This task may require further research outside of the provided information.
Action 5: Finish[Not found]
Observation 5: Episode finished, reward = 0 {'steps': 5, 'answer': 'Not found', 'gt_answer': 'Chief of Protocol', 'question_idx': 1, 'reward': False, 'em': False, 'f1': 0}
设想总是很好但在实施中总是会伴随意外,上述例子LLM没有回答正确,主要问题就是没有search到相关信息。这也暴露出对于ReAct来说,最大的问题就是推理后搜索的准确率,首先需要正确推理下一步的动作,然后动作需要搜索到正确信息,因此优化推理能力和搜索能力是提升ReAct能力的根本。
四、ReAct的fine-tuning
fine-tuning,也就是SFT(监督学习),论文中对所有方法构建微调数据并对LLM进行微调,其中微调数据的构建方法描述如下:

论文链接在这STaR,供想了解自引导方法的友友查阅。
微调细节:

prompt和fine-tuning的效果对比(HotpotQA数据集):
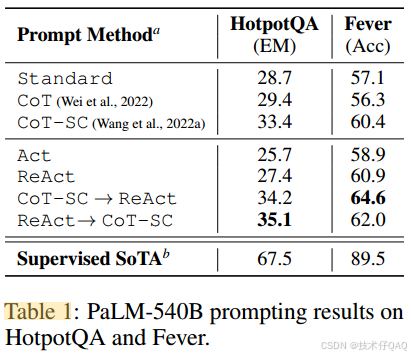
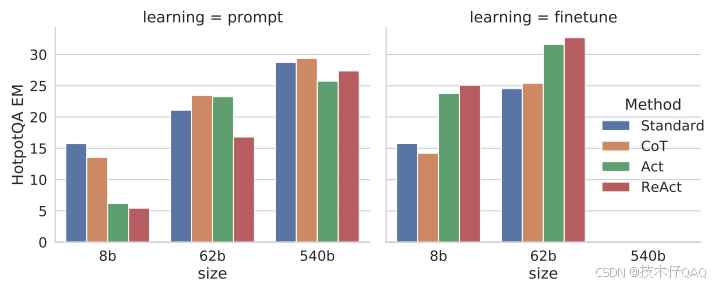
从上图看到,ReAct+CoT-SC在prompt的效果最好,ReAct在fine-tuning的效果最好。
对于PaLM-8/62B,提示ReAct在四种方法中表现最差,因为LLM很难凭借几个上下文示例就学习到复杂的推理过程。然而,当仅使用3,000个示例进行微调时,ReAct成为四种方法中最好的方法,其中经过PaLM-8B微调的ReAct优于所有PaLM-62B提示方法,而经过PaLM-62B微调的ReAct优于所有540B提示方法。相比之下,对于PaLM8/62B来说,微调Standard或CoT比微调ReAct或Act要差得多,因为前者本质上是向模型注入知识(可能是幻觉),而后者则是教模型如何学习这种推理范式,学习到的是一种更通用的推理能力。
这也说明Act-only和ReAct本身就是一种更为强大的prompt范式,只是限于LLM本身的能力没有办法很好的执行,但微调后LLM强化了这种推理能力后,这种范式的强大就显现出来了。
五、ReAct存在的问题
结合论文和实践来总结下ReAct存在的问题。论文首先选取了200个例子进行结果分析,对ReAct和CoT从Success和Failure两方面进行比较,两者都是推理模型但两者又有不同,前者借助外部知识库获取知识进行推理,后者借助LLM的内部知识进行推理:

(给入门的同学简单介绍下,True positive指将实际为正类的样本预测为正类,False positive指将实际为负类的样本预测为正类)
相较下,ReAct对CoT的优势是可以借助外部知识库获得事实驱动的知识,不易产生幻觉,而两者又都具有推理能力,所以两者的比较关键就在于推理能力和获取知识的途径。
首先从Success的情况来看,ReAct的TP值比CoT高,这是因为ReAct可以访问外部知识库,获得的只是更值得信赖,同时ReAct的FP也比CoT低,并且FP的定义是幻觉导致的错误,更说明ReAct获取知识的途径更加可靠,不易产生幻觉。
从Failure来看分为四类:推理错误、搜索错误、幻觉问题、标签歧义。
ReAct的推理错误更多,因为LLM难以凭借几个上下文示例就学习到复杂的推理过程,反而限制了更加泛化的推理路径,由ReAct重复执行出现过的Action就能明显看出其推理能力被约束的太死了,在只prompt的情况下,推理能力要比CoT弱。
搜索错误是ReAct特有的,ReAct的能力建立在Search的基础上,搜索不到有用的信息就很难往下进行。
幻觉问题是CoT特有的,因为ReAct完全借助外部工具获取知识,只将LLM作为推理工具。
标签歧义两者差不多,这是LLM本身的问题,不属于两种范式的问题。
总结
从论文到源码,可以看出ReAct相比之前的方法最大的改进是将推理和行动结合在了一起,它只使用LLM作为推理工具,而使用外部知识库来获取知识减少了幻觉问题。
但ReAct也存在明显问题,ReAct的核心是推理+行动,其中推理决定了行动,所以如果推理不准确的话就很难search到准确信息。从在仅prompt的情况下ReAct并没有比其他几种prompt方法出色可以看出ReAct的推理能力偏弱,从和CoT的对比也能看出这一点,究其原因是因为LLM很难从ReAct的上下文示例中学习到这种推理过程,而经过少量数据fine-tuning之后LLM学习到了更强的通用推理能力,ReAct达到最好的效果,说明了这种范式具备更强的潜力。
因为作者只是想展示ReAct范式的能力,所以源码中的search、lookup方法都比较简单,但实际上在工程层面我们可以进行更多优化,例如加入更多的外部知识库进行search、考虑在search中加入Rag工程、改进thought方式以及加入更多的action类型等等。
ReAct作为初代Agent起到了探索作用,尤其在fine-tuning后的效果提升让我们看到了这种范式的潜力,其明显的缺陷也留给我们更多的想象空间,后续我将更新更强大的Agent模型,进一步探究研究人员是如何弥补这些缺陷的。
另外在阅读源码的时候我借助了cursor,效率真的很快,推荐友友入手:全网最全面详细的Cursor使用教程,让开发变成聊天一样容易-CSDN博客
希望有帮助你多一点了解ReAct,如果内容存在错误欢迎随时批评指正,一起变得更强。

















 5400
5400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









