






目录
一、Maximum Likelihood Estimation(最大似然估计)
摘要
在上周的学习中,明白了GAN的大概原理,不过没有具体写GAN背后的数学理论,这一篇尝试详细地推到一下GAN是怎么来的。生成器的目标是通过学习数据分布的潜在结构,生成逼真的样本。它接收一个随机噪声向量作为输入,并通过一系列的转换将其映射到数据空间。生成器的目标是最小化生成样本与真实样本之间的差异,通常使用生成样本与真实样本之间的损失函数来衡量。
ABSTRACT
In last week's study, I understood the general principles of GANs, but I didn't specifically write about the mathematical theory behind GANs. This article will attempt to provide a detailed derivation of how GANs work. The objective of the generator is to generate realistic samples by learning the underlying structure of the data distribution. It takes a random noise vector as input and maps it to the data space through a series of transformations. The generator aims to minimize the difference between the generated samples and the real samples, typically measured using a loss function that compares the generated samples to the real samples.
考虑一下,GAN到底生成的是什么呢?比如说,假如我们想要生成一些人脸图,实际上,我们是想找到一个分布,从这个分部内sample出来的图片,像是人脸,而不属于这个distribution的分布,生成的就不是人脸。而GAN要做的就是找到这个distribution。

在GAN出生之前,我们怎么做这个事情呢?
之前用的是Maximum Likelihood Estimation,最大似然估计来做生成的,我们先看一下最大似然估计做的事情。
一、Maximum Likelihood Estimation(最大似然估计)
最大似然估计的理念是,假如说我们的数据集的分布是 我们定义一个分布
,我们想要找到一组参数 θ ,使得 越
接近
越好。比如说,加入
如果是一个高斯混合模型,那么 θ 就是均值和方差。

具体怎么操作呢
1、首先我们不知道真实的数据分布是什么样的,但是我们可以从抽样出一些样本(真实图片)。
2、对每一个sample出来的x,我们都可以计算它的lkelihood,也就是给定一组参数,我们就能够知道长什么样,然后我们就可以计算出在这个分布里面sample出某一个x的几率。
3、我们把在某个分布可以产生的likelihod乘起来,可以得到总的likelihood:
,我们要找到一组
,可以最大化 L
二、MLE=Minimize KL Divergence
其实最大似然估计的另一种解释是Minimize KL Divergence

但是我们常常要先假定一个具体的分布去逼近实际分布,我们的分布不一定是高斯分布,如果
是一个NN,就没有办法算likelihood。因此我们需要一个通用的分布,去逼近这个复杂的图像真实分布。因此要用GAN的Generator来解决这个问题。
三、Generator
过去如果使用最大似然估计,采用高斯混合模型定义 ,生成的图片会非常模糊。而现在我们用的Generator的方法,是从一个简单的分布(比如正态分布)中sample出样本,然后扔进一个network(即generator),然后得到输出,把这些输出统统集合起来,我们会得到一个distribution, 这个distribution就是我们要找的
,而我们的目标是使得
与
越接近越好。

优化目标是最小化与
之间的差异:
那么怎么计算两个分布的差异呢? 与
的公式我们都是不知道的,怎么算呢?这里就要引出Discriminator了:
四、Discriminator
虽然我们不知道与
的公式,但是我们可以从这两个分布中sample出一些样本出来。对于
来说,我们从给定的数据集中sample出一些样本就可以了。对于
来说,我们随机sample一些向量,扔到Generator里面,然后generator会输出一些图片,这就是从
里面sample了。

问题就变成我们怎么从sample的数据求与
,其实我们可以使用Discriminator来衡量
与
的Divergence
蓝色星星: data sampled from
橙色星星: data sampled from

我们可以用Discriminator来区分两个Distribution,公式:
前面一项是表示数据sampled from,值越大越好,后面一项是表示数据sampled from
,值越小越好
上面公式的形式和训练一个二分类Classifier的目标函数长得一样,就是说可以把与
看成两个分类。
训练Discriminator就好比训练一个二分类:
而训练出来的就相当于与JS divergence,来看下为什么是JS divergence。
如果两个分布的数据很接近(small divergence),那么Discriminator很难把数据分开,也就是上面的公式很难找到一个D,使取得很大的值。那么就找到最大的divergence,使得两个分布的数据相隔ed远一些,我们的Discriminator就能容易的将数据分开。

也就是 和divergence程度有关系,下面用数学来证明。
五、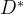 和divergence的关系证明
和divergence的关系证明


六、KL散度、JS散度和交叉熵
KL散度、JS散度和交叉熵:三者都是用来衡量两个概率分布之间的差异性的指标。不同之处在于它们的数学表达。
对于概率分布P(x)和Q(x)
KL散度(Kullback–Leibler divergence)又称KL距离,相对熵。
当P(x)和Q(x)的相似度越高,KL散度越小。
KL散度主要有两个性质:
不对称性
尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即D(P||Q)!=D(Q||P)。
非负性
相对熵的值是非负值,即D(P||Q)>0。
JS散度(Jensen-Shannon divergence)JS散度也称JS距离,是KL散度的一种变形。
但是不同于KL主要又两方面:
值域范围
JS散度的值域范围是[0,1],相同则是0,相反为1。相较于KL,对相似度的判别更确切了。
对称性
即 JS(P||Q)=JS(Q||P),从数学表达式中就可以看出。
交叉熵(Cross Entropy)
在神经网络中,交叉熵可以作为损失函数,因为它可以衡量P和Q的相似性。
交叉熵和相对熵的关系:
以上都是基于离散分布的概率,如果是连续的数据,则需要对数据进行Probability Density Estimate来确定数据的概率分布,就不是求和而是通过求积分的形式进行计算了。
七、G*
生成器训练的目标是找到一个,去最小化
与
,也就是:
而这个divergence我们没有办法直接去算,我们不知道与
的公式具体是什么。于是我们通过一个discriminator来计算两个分布间的差异:
那么我们的优化目标就变为:
这个看起来很复杂,其实直观理解一下,如下图,我们假设已经把Generator固定住了,图片的曲线表示,红点表示固定住G后的 , 也就是
与
的差异。而我们的目标是最小化这个差异,所以下图的三个网络中,
是最优秀的。

八、GD Algorithm for GAN
具体的算法:

Step1:首先固定生成器,找到一个能够使V最大的D;
Step:然后固定D,找到能够使这个最大D情况下V最小的G。不停的迭代…
从数学看为什么这个算法是在解上面的最小最大过程:
用函数L(G)替代中的
:
那么找最好的G的话就用梯度下降(和一般的train是一样的);θ是表示G的参数
但是L(G)有个max操作,但是它依然也是可以做微分的: 假设有个函数f(x)是max三个子函数,f(x)其实 就是每个阶段取最大值 最终求微分的过程就是在每一个点x,先看哪个子函数在这个点最大,微分值就是最大的那个子函数的微分值。也就是梯度下降依然适用,就是每次更新参数的时候先看自己在那个范围,再用这个范围的函数求梯度,然后更新;重复…
总结
判别器的目标是区分生成样本和真实样本。它接收一个样本作为输入,并输出一个概率值,表示该样本是真实样本的概率。判别器的目标是最大化正确判断真实样本和生成样本的能力,通常使用交叉熵损失函数来衡量。
GAN的训练过程是一个博弈过程,生成器和判别器相互竞争。生成器试图生成逼真的样本以欺骗判别器,而判别器试图准确地区分真实样本和生成样本。通过交替训练生成器和判别器,GAN的目标是找到一个纳什均衡点,即生成器生成的样本无法被判别器准确区分。















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









