






1.关键内容
以计算flops为指导,通过计算浮点运算量来描述轻量级网络的快慢,但是从不考虑直接运行的速度,在移动设备中不仅仅需要考虑flops,还需考虑内存访问成本和平台特点,即shufflenetv2直接通过控制不同环境来直接测试网络在设备上运行速度的快慢,而不是用flops判断。在实际应用中CNN应用受限于硬件与存储。必须有一种能在算法层面有效的压缩存储和计算量的方法。而MobileNet/ShuffleNet正为我们打开这扇窗。
按照网络提出的顺序依次介绍:
MobileNet v1 -> ShuffleNet v1 -> MobileNet v2 -> ShuffleNet v2
2对应介绍
2.1 Group convolution
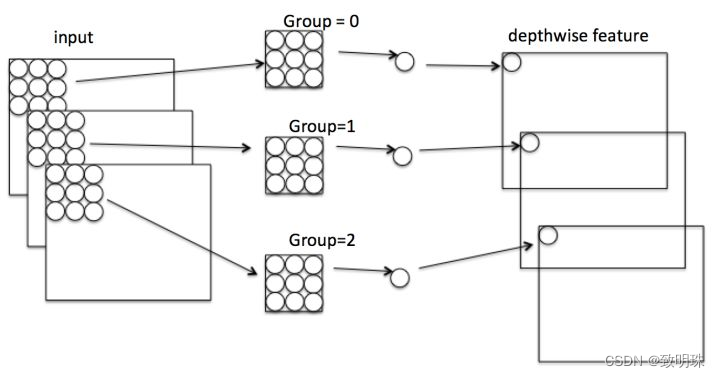
假设有输入feature map,尺寸为 W*H*C ,同时有 k 个 h*w 卷积核。对于一般卷积,见图一,输出feature map尺寸为 H'* W'*k (这里不关心 H' 和 W’ )。Group convolution(group=2),实质就是将convolution分为 g 个独立的组,分别计算。即

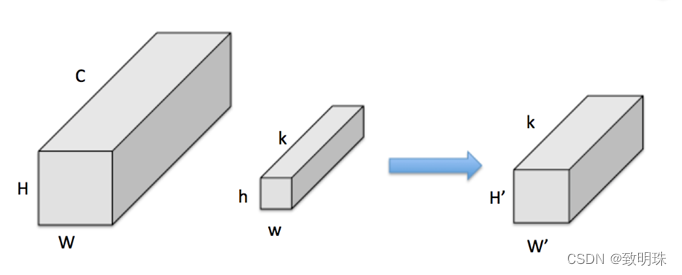
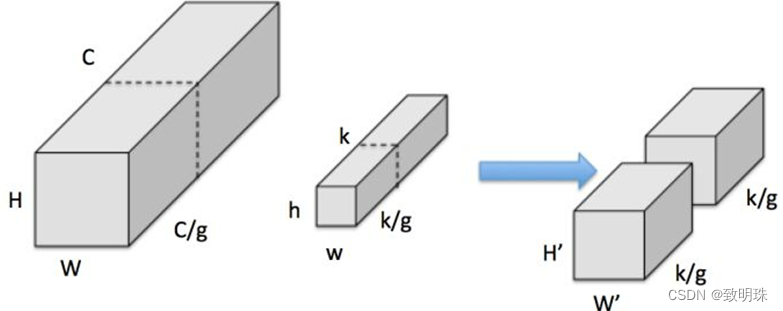
2.2 Mobilenet
(二十八)通俗易懂理解——MobileNetV1 & MobileNetV2 - 古月居 (guyuehome.com)
(1)核心介绍
Mobilenet v1是Google于2017年发布的网络架构,旨在充分利用移动设备和嵌入式应用的有限的资源,有效地最大化模型的准确性,以满足有限资源下的各种应用案例。Mobilenet v1也可以像其他流行模型(如VGG,ResNet)一样用于分类、检测、嵌入和分割等任务提取图像卷积特征。
网络亮点是:设计了Depthwise convolution(大大减少运算量和参数量);增加了超参数α和β
Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。
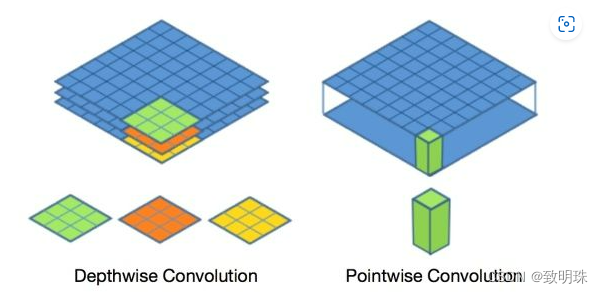
传统卷积:卷积核channel=输入特征矩阵channel,输出特征矩阵channel=卷积核个数
DW卷积:卷积核channel=1,输入特征矩阵channel=卷积核个数=输出特征矩阵channel
DW+PW卷积(深度可分离卷积):每个特征和1*1卷积进行操作。
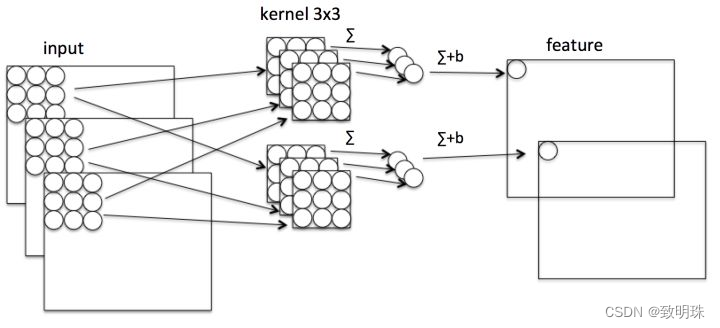
计算普通卷积,假设有 N*H*W*C 的输入,同时有 k 个 3*3 的卷积。如果设置 pad=1 且 stride=1 ,那么普通卷积输出为 N* H* W*k:
![]()
Depthwise是指将 N*H*W*C 的输入分为 group=C 组,然后每一组做 3*3 卷积,如图*。这样相当于收集了每个Channel的空间特征,即Depthwise特征。
![]()
Pointwise是指对 N*H*W*C 的输入做 k 个普通的 1*1 卷积,如下图。这样相当于收集了每个点的特征,即Pointwise特征。Depthwise+Pointwise最终输出也是 N*H*W* k
![]()
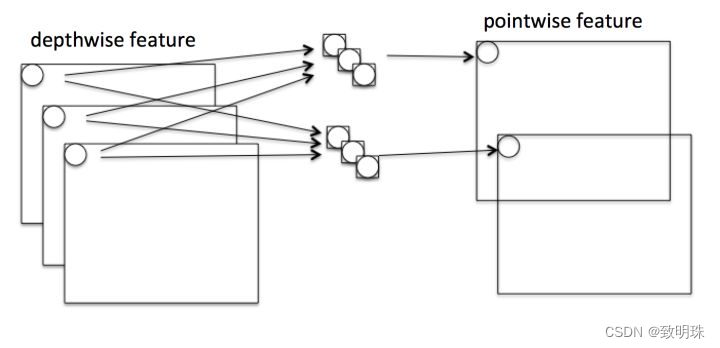
这样就把一个普通卷积拆分成了Depthwise+Pointwise两部分

计算优势:
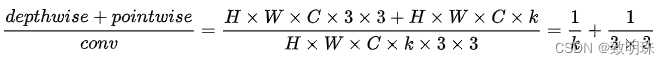
(2)网络架构
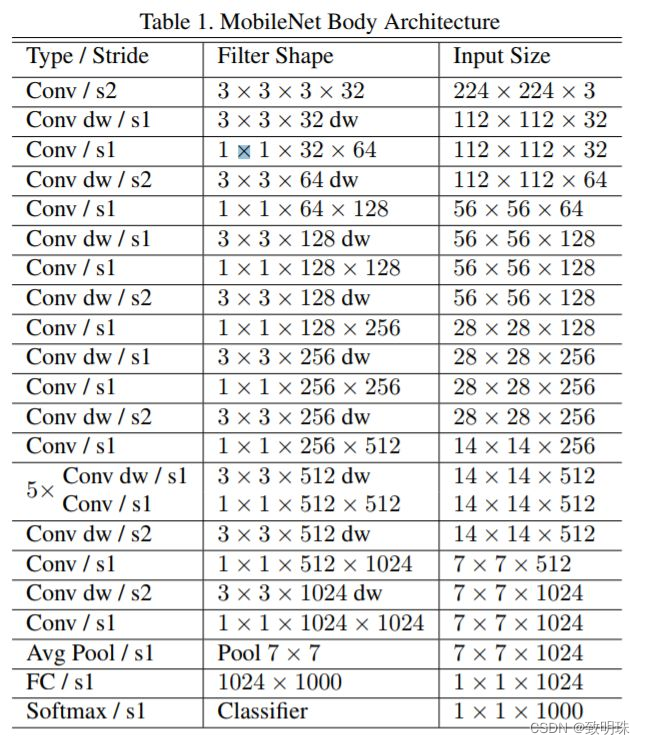
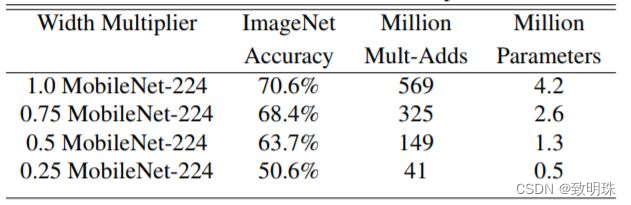
对图Architecture中的所有卷积层 kernel 数量统一乘以缩小因子α,典型值为1,0.75,0.5和0.25用于压缩网络,压缩网络计算量肯定是有代价的。下图展示了α不同时Mobilenet v1在ImageNet上的性能。可以看到即使α时Mobilenet v1在ImageNet上依然有63.7%的准确度。
2.3 ShuffleNet v1
ShuffleNet 系列(1): ShuffleNet v1 理论讲解_gconv是什么网络_@BangBang的博客-CSDN博客
(1)核心
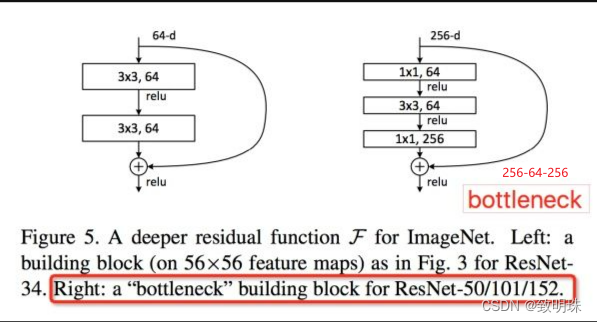
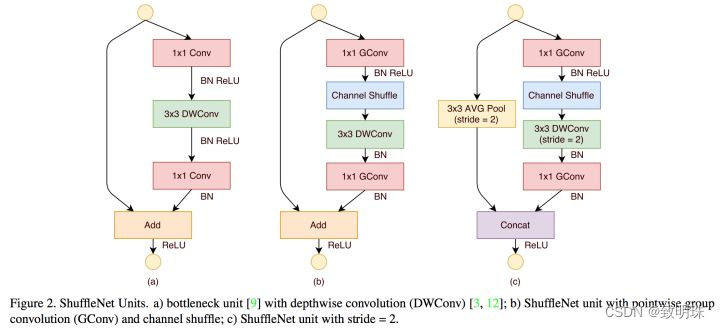
ShuffleNet是Face++提出的一种轻量化网络结构,主要思路是使用Group convolution和Channel shuffle改进ResNet,可以看作是ResNet的压缩版本。
那么ShuffleNet为何要这样做?既然是轻量化网络,我们还是来算算计算量。
假设输入feature为 H*W*C ,所有的1*1 卷积数为 C , 3*3 Depthwise卷积数为 k ,Group convolution都分为 g 组。图 (a)和(b)的网络乘法计算量:
图(a) ResNet bottleneck: HW(2Ck + 9k)
图(b) ShuffleNet stride=1结构: HW(2Ck/g + 9k)+ (shuffle cost)
相比原始加入Depthwise的ResNet缩小了很多的计算量。所以ShuffleNet相当于保留ResNet结构,同时又压低计算量的改进版。
(2)架构
为何要进行shuffle操作:
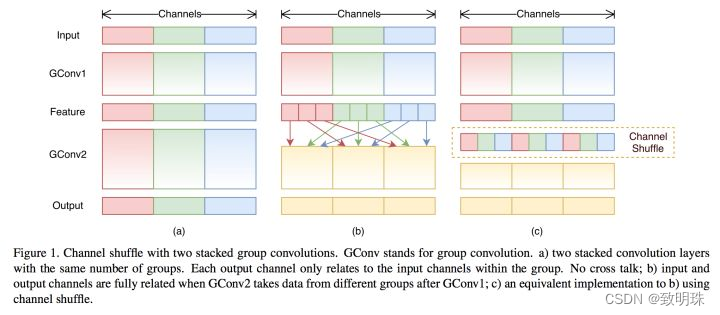
ShuffleNet的本质是将卷积运算限制在每个Group内,这样模型的计算量取得了显著的下降。然而导致模型的信息流限制在各个Group内,组与组之间没有信息交换,如图下,这会影响模型的表示能力。因此,需要引入组间信息交换的机制,即Channel Shuffle操作。同时Channel Shuffle是可导的,可以实现end-to-end一次性训练网络。
当然,ShuffleNet有2个重要缺点:
Shuffle channel在实现的时候需要大量的指针跳转和Memory set,这本身就是极其耗时的;同时又特别依赖实现细节,导致实际运行速度不会那么理想。
Shuffle channel规则是人工设计出来的,不是网络自己学出来的。这不符合网络通过负反馈自动学习特征的基本原则,又陷入人工设计特征的老路(如sift/HOG等)。
2.4mobilenetv2MobileNetV2: Inverted Residuals and Linear Bottlenecks - seniusen - 博客园 (cnblogs.com)
MobileNet V2 论文初读 - 知乎 (zhihu.com)
(1)网络亮点

MobileNet V2是Google继V1之后提出的下一代轻量化网络,准确率更高,模型更小,主要解决了V1在训练过程中非常容易特征退化的问题,V2相比V1效果有一定提升。
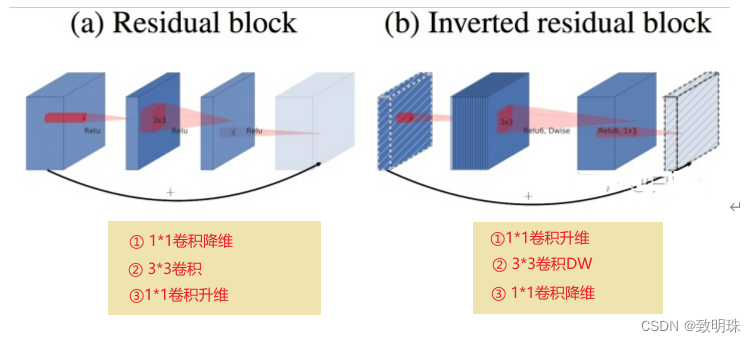
v2为何做倒残差结构:右边中间两层通道数比较多,所以采用激活函数,信息损失也没有那么大;而两端通道数比较少,如果激活的话信息损失会非常大,所以不采用激活函数。既然 举个例子1维线性空间中点的关系和100维线性空间中点的关系那个更复杂,哪个更能逼近非线性函数,答案显而易见。这一点可以类比其他net,都是增加channel,减少图片高度和宽度,都是在抽离高维度特征。至于linearbottleneck,只是不再截断,有人可能会问这里为何没进行非非线性激活也能有较好的结果?请不要忘了其他层可是都做了非线性激活的,可以想象单层不做激活,影响也不会太大。
在其中采用relu6做激活函数,ReLU激活函数对低维特征信息造成大量损失,而对高维特征信息造成的损失较小。

(2)网络架构
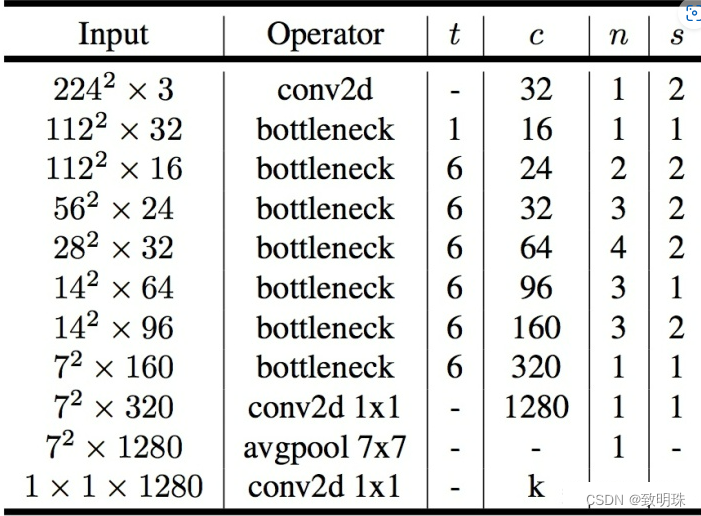
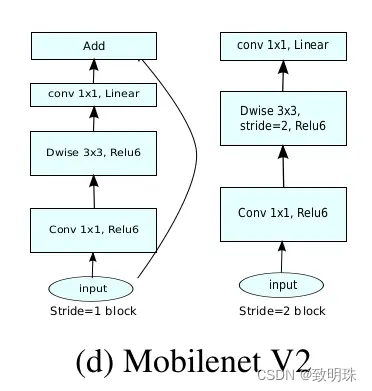
如上表所示,第一层是标准卷积,然后后面是前述的瓶颈结构。其中 t 是扩展因子,c 是输出通道数, n 是重复次数,s 代表步长。如果步长为 2 ,代表当前重复结构的第一个块步长为 2,其余的步长为 1,步长为 2 时则没有跳跃连接,如下图所示。

2.5 shufflenetv2
(1)核心分布
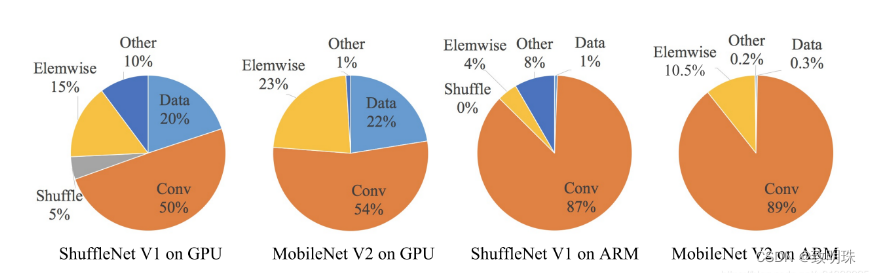
分析了ShuffleNet v1和MobileNets V2在GPU和ARM上的耗时分布,从图中可看出Conv操作占了其时间的绝大多数,但Elemwise/Data IO等内存读写密集型操作也占了相当比例的时间,因此,我们在设计网络的时候,不仅要考虑Conv的个数也要考虑其他操作。
总结了四个准则来指导优化网络:
1)卷积层的输入和输出特征通道数相等时MAC(内存访问消耗时间)最小,此时模型速度最快。
2)过多的group操作会增大MAC,从而使模型速度变慢。
3)模型中的网络分支数量越少,模型速度越快。
4 )element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作。
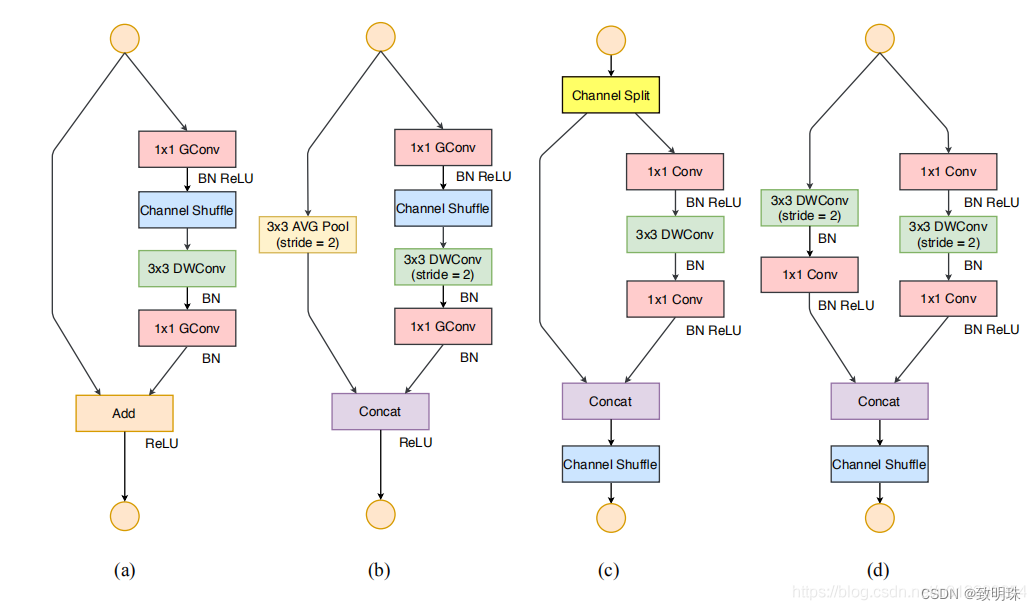
具体来看下图中网络结构的改变,是怎样对应着这四个准则,其中(a)和(b)是ShuffleNet v1文章中两种结构,(c)和(d)则是根据(a)和(b)改进而来。(c)结构相对于(a)结构,增加了channel split操作,就是为了保证concat操作之后满足前面第1)点。(c)中取消了GCconv是为了满足前面第2)点,同时把channel shuffle的操作移到了concat后面,和前面第3)点对应。将将element-wise add操作替换成concat,和和前面第4)点对应。
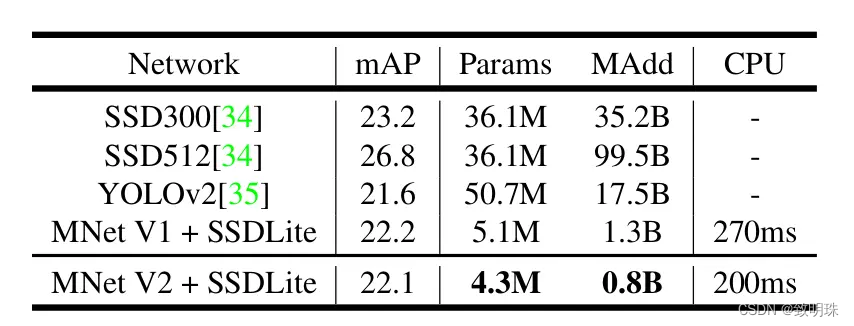
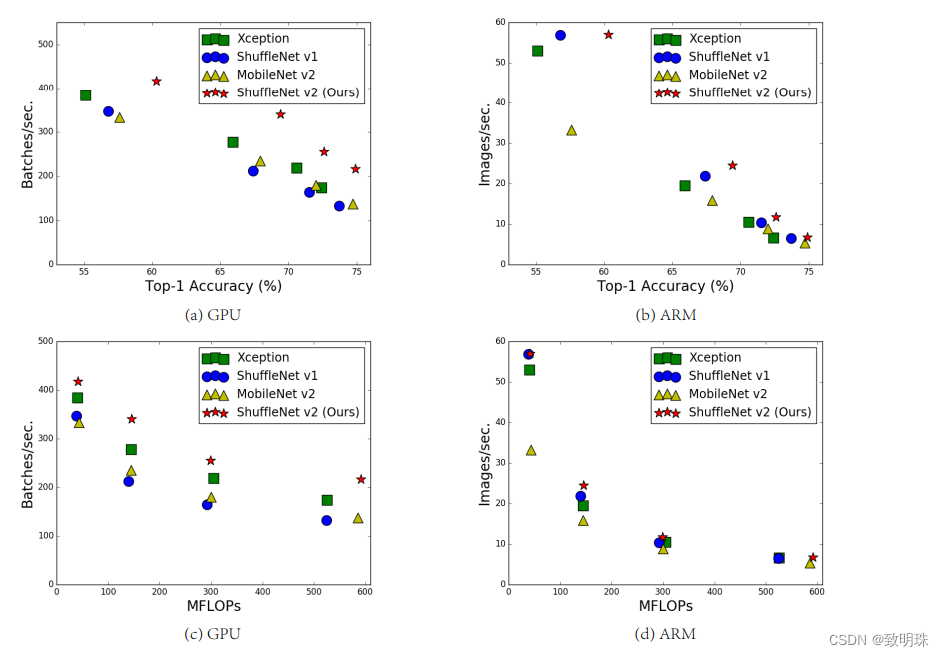
在同等复杂度下,ShuffleNetv2比ShuffleNet和MobileNetv2更准确
3.总结
MobileNet将普通2D卷积分解为depthwise conv和pointwise conv
其中有个细节是Xception和ShuffleNet都提到depthwise conv之后不接ReLU激活函数比用ReLU激活函数好,MobileNet-v2的depthwise conv还是用了ReLU的,只不过后面接的1X1降维没用,因为它梭子型中间有冗余嘛,可以承担ReLU带来的风险
MobileNet-v2的Inverted residuals就是把两头宽,中间窄的沙漏型结构变成了两头窄,中间宽的梭子型结构,因为depthwise conv嘛,resonable
这几个网络在大幅降低计算量的同时基本保持了精度,然而此时主要矛盾就发生了转化,占据计算量的主体由3x3的卷积核变成了1x1的卷积核(90%以上),所以ShuffleNet对它也分组了,然而这带来了新的问题也就是group conv 本来就存在的一个问题,只不过现在激化了,就是group之间信息交流不足的问题,ShuffleNet的解决方法就很巧妙了,这篇文章总结一下就是:发现问题(pointwise conv计算量占主体),解决问题(pointwise conv计算也分组),引入了新问题(group之间信息交流不足),解决新问题(channel shuffle)
小模型参数量比较小,正则化加入要谨慎,比如weight decay需要适当小一点,shufflenet采用了weight decay随训练逐渐减少至0的训练策略,mobilenet对于depthwise卷积则没有使用正则化















 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









