









 SGTR是一种基于Transformer的端到端场景图生成模型,解决了传统方法在复杂场景中的效率和噪声问题。模型通过预测实体和谓词节点,然后通过图组装形成二分图来构建场景图。在VG和OpenimageV6数据集上的实验表明,SGTR在多个指标上表现出竞争力,甚至达到SOTA水平。
SGTR是一种基于Transformer的端到端场景图生成模型,解决了传统方法在复杂场景中的效率和噪声问题。模型通过预测实体和谓词节点,然后通过图组装形成二分图来构建场景图。在VG和OpenimageV6数据集上的实验表明,SGTR在多个指标上表现出竞争力,甚至达到SOTA水平。
|
方法简称SGTR |
|
方法特点End-to-end ,with Transformer |
SGTR:使用Transformer的端到端场景图生成
CVPR 2022
动机
传统模型生成场景图时的时间复杂度较高,并且在提取关系特征时会产生大量噪声,现有的端到端方法虽对上述问题有所改进,但一般依赖于“两个关系间不会有较大的重叠区域”的假设下,这在复杂的场景图中不可取。
贡献
- 本文提出了基于Transformer的端到端场景图生成模型,该模型分别预测实体节点和谓词节点,通过连接两种节点,生成二分图进而构建场景图,命名为SGTR。
- 本文在VG数据集和Openimage V6数据集上进行实验,实验结果与传统模型相比很有竞争力,在部分任务中达到SOTA。
方法概述
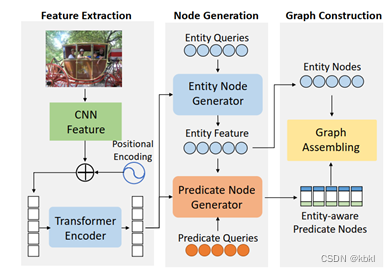
对于输入图像,论文方法使用CNN backbone提取特征,随后对特征位置编码并输入至Transformer Encoder更新,更新后的图像特征1)连同初始化的实体Queries输入至实体节点生成器,输出实体特征,特征中包含实体的空间信息和分类信息,对实体特征进行两项操作:传入谓词节点生成器中;预测实体节点。2)连同初始化的谓词表征Queries、步骤1的实体特征输入至谓词节点生成器中,获得实体感知的谓词节点。对实体节点与谓词节点Graph Assembling操作,连接实体节点与谓词节点并形成二分图,进而转化为场景图。
具体方法
- Entity Node Generator
本文采用ResNet101作为主干网络提取特征,随后使用多层Transformer编码器对特征更新,更新后的图像特征记为Z∈Rw×h×d,w、h、d 为特征图的宽高及通道数。
在实体节点生成器中,论文采用DETR的解码器结构。输入图像特征Z ,以及初始化的实体Queries Qe∈RNe×d (Ne 为预设的实体query个数),输出实体特征,内含实体的位置信息、分类信息、以及实体视觉特征,可以表示为:
Be,Pe,He=Fe(Z,Qe)
- Be :实体框坐标,Be∈RNe×4 ,每行元素包含实体框的中心坐标(x,y)以及框的宽高(w,h)
- Pe :实体分类得分,Pe∈RNe×(Ce+1) ,(Ce+1 )为包括背景在内的物体类别个数。
- He :实体视觉特征,He∈RNe×d
- Fe(·) :解码器的映射函数
- Predicate Node Generator(本文重点)
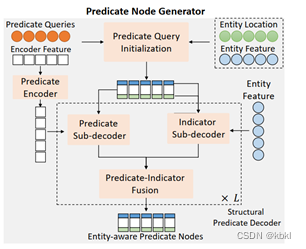
谓词节点生成器内部由三部分组成:1)Predicate Encoder,进一步处理图像特征,生成predicate-specific的特征图。2) Predicate Query Initialization根据谓词表征Queries、实体视觉特征、实体位置特征,将每个谓词Query初始化为Qpe=Qis;Qio;Qp∈RNr×3d ,由主语实体指示特征Qis (图中蓝色),谓词表征Qp (图中白色)和宾语实体指示特征Qio (图中绿色)组成。3) Structural Predicate Node Decoder,对谓词Queries更新,对于主/宾语实体指示特征Qis,Qio ,在指示特征子解码器中使用实体特征更新,更新后的指示特征能够感知与实体节点间的相关性,从而能更好的指示谓词节点寻找其对应的实体节点;对于谓词表征Qp ,通过predicate-specific的特征图在谓词子解码器中更新,更新后的谓词表征能更好的感知空间上下文。最后,对更新后的Qis,Qio,Qp (假如此时为第l 层)融合,生成下一层的输入Qpl+1Qisl+1Qiol+1 ,经过L层结构性谓词节点解码器后,根据Qpe 输出谓词节点的预测结果。
-
- Predicate Encoder
输入为图像特征Z ,论文继续采用Transformer编码器更新特征,获得predicate-specific图像特征Zp∈Rw×h×d 。
-
- Predicate Query Initialization
为了更清晰的表达谓词中的视觉关系,论文舍弃了常规Query的形式,将谓词Query初始化为Qpe=Qis;Qio;Qp∈RNr×3d ,其中Nr 为预设的关系query个数,Qis,Qio∈RNr×d 为主语和宾语的实体指示特征(entity indicator),Qp∈RNr×d 为谓词表征。Qpe 初始化过程可表示为:
![]()
- Aq,k,v: Transformer中Multi-Head Attention计算的简写
- Qinit :初始化的谓词表征queries
- Kinit,Vinit :Kinit=Vinit=(He+Ge) ,Ge=ReLU(BeWg) ,He和Be分别为实体节点的实体视觉特征和空间坐标,Wg 为用于升维的几何嵌入空间矩阵。
- We :We =[Weis,Weio,Wep ],分别为Qis,Qio,Qp 的变换矩阵
- Structural Predicate Node Decoder
每个结构性谓词节点解码器由三部分组成,a) predicate sub-decoder; b) entity indicator sub-decoders; c) predicate indicator fusion,论文共应用L层结构性谓词节点解码器层,下文对sub-decoder的讨论仅针对单层结构性谓词节点解码器而言。
2.3.1 predicate sub-decoder
利用互注意力机制,通过图像特征Zp 对谓词表征Qp 更新,得到新的谓词表征Qp ,达到利用空间上下文更新谓词表征的目的,过程表示为
![]()
2.3.2 entity indicator sub-decoders
同样的,对主/宾语实体指示特征Qis,Qio 和实体视觉特征He 应用互注意力机制计算,使实体指示特征能感知其与各实体节点的关联性,更新后的实体指示特征为Qis , Qio :
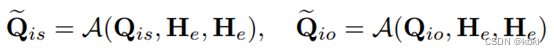
2.3.3 predicate indicator fusion
对于结构性谓词节点解码器层,在经过两子解码器更新特征后,需对更新后的Qp,Qis , Qio 融合,获取Qpl+1Qisl+1Qiol+1 作为下一层解码器的输入。
具体来说,获得第l 层的Qpl,Qisl , Qiol 后,融合谓词特征,作为l+1 层的输入Qpl+1 :
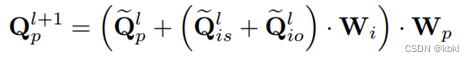
- Wi ,Wp 为用于更新的参数矩阵。
而对于第l+1 层的另外两个输入Qisl+1和Qiol+1 ,直接赋值:
2.3.4 解码器预测结果
定义经过L层结构性谓词节点解码器层精炼后的谓词Queries为Qpe =Qp;Qis;Qio
模型根据Qp 预测谓词类别及谓词对应实体的坐标:

- Wclsp , Wregp :分别为谓词节点生成器的分类矩阵、回归矩阵
- {(xcs,ycs,xco,ycs)} :主语/宾语实体框的中心坐标
根据Qis 和Qio ,与实体节点生成器相似,分别预测主语/宾语的实体坐标Bs,Bo ∈RNr×4 和实体分类得分Ps , Po ∈RNr×(Ce+1) 。
- Bipartite Graph Assembling
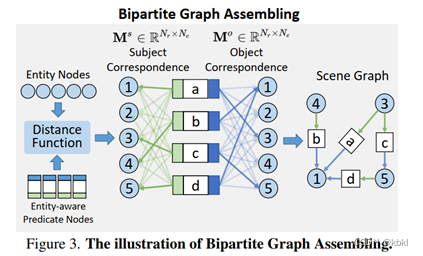
二分图-->场景图形成过程:以subject-predicate为例,对于每个谓词节点,将主语实体指示特征Qis 的预测结果Bs,Ps 与实体节点的预测结果Be,Pe 进行比较,选取TOP-K个有可能成为谓词主语的实体节点,连接谓词节点与对应的实体节点。predicate-object同理,最后根据连线结果生成场景图。
连线生成过程,同样以subject-predicate为例:
对Ne 个实体节点和Nr 个谓词节点,生成相关性矩阵Ms∈RNr×Ne :
Ms=dlocBs,Be·dclsPs,Pe
- Bs,Ps :根据谓词节点中主语实体指示特征,预测的实体坐标和分类得分
- Be,Pe :根据实体特征,预测的实体坐标和分类得分
- dloc , dcls :衡量匹配质量的距离函数,分别从坐标Bs,Be 和得分Ps,Pe 两个角度衡量匹配度
筛选出Ms 中每个谓词的前K个对应实体节点:
Rs=FtopMs,K∈RNr×K
- Ftop :索引选择操作
predicate-object同理,最后根据索引矩阵Rs 和Ro 生成三元组,构建场景图。
- Loss Function
本文的损失函数可分为实体节点生成器损失Lenc 和关系节点生成器损失Lpre ,其中Lenc 的计算过程与DETR detector相同,这里
对关系预测与关系GT值应用匈牙利匹配算法:
定义关系预测为Γ={(bes, pes,beo,peo![]() ,pp, bp
,pp, bp![]() )},bes, pes/beo,peo分别为
)},bes, pes/beo,peo分别为![]() 主语/宾语实体节点边界框的预测和分类分数,pp为谓词预测的分类分数,bp
主语/宾语实体节点边界框的预测和分类分数,pp为谓词预测的分类分数,bp![]() 为谓词的位置预测,由主语实体indicator框和宾语主语实体indicator框的中心点组成,形式为{(xcs,ycs,xco,ycs)}
为谓词的位置预测,由主语实体indicator框和宾语主语实体indicator框的中心点组成,形式为{(xcs,ycs,xco,ycs)}![]() 。
。
对应的对于关系的GT值有Γgt![]()
匹配损失: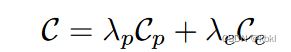
Cp![]() 为谓词损失,根据pp, bp
为谓词损失,根据pp, bp![]() 计算,第i个关系预测与第j个关系GT值的计算公式为:
计算,第i个关系预测与第j个关系GT值的计算公式为:
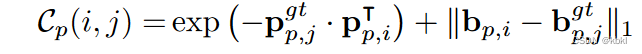
Ce为实体损失,![]() 根据bes, pes,beo,peo计算
根据bes, pes,beo,peo计算![]() ,第i个关系预测与第j个关系GT值的计算公式为:
,第i个关系预测与第j个关系GT值的计算公式为:
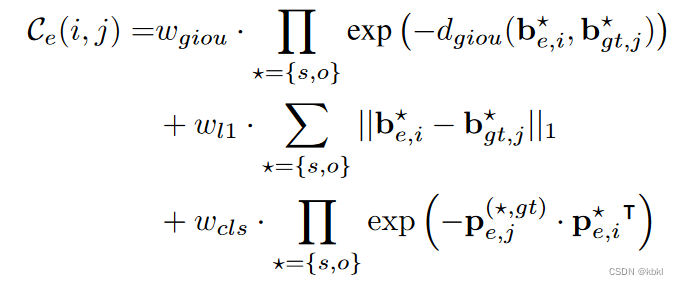
带☆的参数表示实体节点的预测结果,实际上就是bes, pes,beo,peo![]()
对于损失函数,
重点对Lpre 介绍:
![]()
其中 ![]() ,Lboxi 为实体定位损失,根据Bs 和Bo 计算,由 L1 loss和GIOU loss组成;Lclsi 为实体分类损失,根据Ps 和Po 计算交叉熵损失。
,Lboxi 为实体定位损失,根据Bs 和Bo 计算,由 L1 loss和GIOU loss组成;Lclsi 为实体分类损失,根据Ps 和Po 计算交叉熵损失。
其中 ![]() ,Lentp 为谓词定位损失,根据Bp 计算L1 loss;Lclsp 为谓词分类损失,根据Pp 计算交叉熵损失。
,Lentp 为谓词定位损失,根据Bp 计算L1 loss;Lclsp 为谓词分类损失,根据Pp 计算交叉熵损失。
实验
- 数据集:VG,Openimage V6
Openimage V6:训练集53953张图像 ,测试集3234张图像
- 评价指标:R@K,mR@K,wmAPrel ,wmAPphr ,scorewtd
wmAPrel :关系的加权平均精度,评估三元组中主语谓语宾语的AP,前提条件:subject的框和object的框与GT框的IOU值均要大于0.5
wmAPphr :短语的加权平均精度。
scorewtd = 0.2 × R@50 + 0.4 ×wmAPrel + 0.4 × wmAPphr
- 实验细节:
Backebone为ResNet-101,实体检测器为DETR
一些参数:谓词节点生成器中3层Transformer编码器,6层解码器;谓词Queries数量Nr 设置为150;训练时K=40,测试时K=3。
- 消融实验
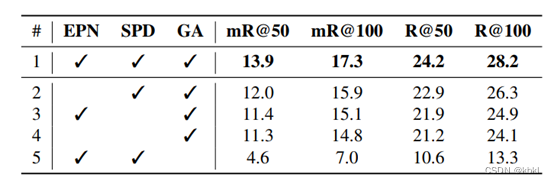
对模型组成部分的消融,EPN:实体感知谓词节点,SPD:结构性谓词解码器,GA:Graph Assembling图生成
- 第二行发现使用仅感知谓词的Queries(相对于本文谓词Queries既包括谓词表征,还包括主/宾语实体指示特征)会导致性能下降
- 第三行发现使用简单的互注意力机制更新Qpe (本文采用的两个子解码器,分别更新特征并融合的结构),也会导致性能下降。
- 第四行综合了第二行和第三行的设置发现性能下降,但与第二行第三行对比不明显,说明实体感知谓词节点与结构性谓词解码器有很强的交互性。
- 第五行将实体感知谓词节点中,主/宾语实体指示特征的预测代替实体节点,可以看到效果非常不好,也说明计算实体节点与谓词节点匹配矩阵的重要性。
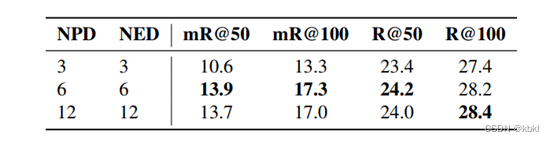
对结构性谓词解码器中的两个子解码器层数的消融实验,NPD:谓词子解码器层数,NED:实体指示特征子解码器层数。可以看到NPD和NED 取6时效果最好,过多的解码器层反而会影响性能。
- 性能实验
Openimage V6数据集上的性能实验:
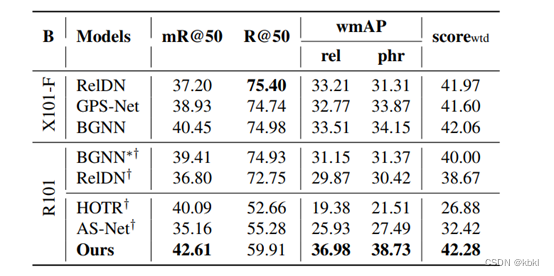
sword标志为本文复现的结果,*表示应用重采样策略的模型,可以看到论文方法在几个指标上基本达到SOTA。
在VG数据集上的性能实验
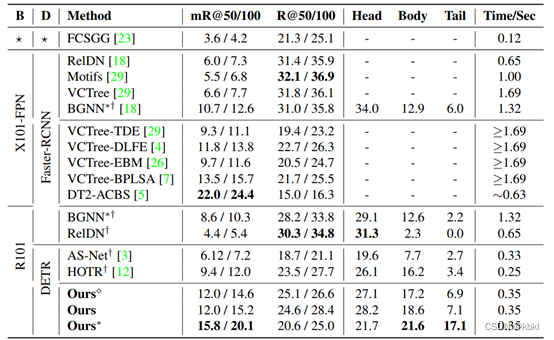
sword标志为论文复现结果, 表示FCSGG模型中独特的物体检测器和backbone,*为重采样策略的模型,在论文的方法(Ours)中 表示TOP-K取1时的性能,Time/Sec为生成一张场景图的耗时,可以看到论文方法在效率和性能上取得平衡,并且论文方法的mR@K远超过其他端到端方法(DETR类),说明论文方法能改善数据集标注中的长尾问题。
- 可视化实验
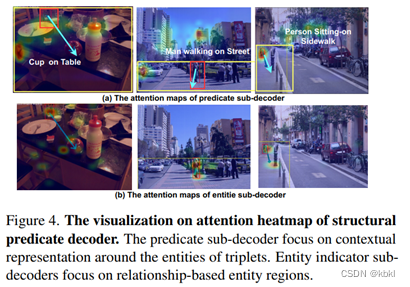
论文可视化了两子解码器在图像中注意力的热图,通过比较图4(a)和图4(b)的热图,可知对于同样的三元组,谓词子解码器更关注三元组周围的上下文,而实体子解码器则更关注实体本身。
思考
1.论文在测试时,设置TOP-K中K为3,意思是一个谓词会对应三个可能的主语/宾语,但在实际场景图中不会有这么多关系,这样生成的场景图虽然指标看起来还可以,但它可以用于服务下游任务吗?如果做一些服务于特定任务的场景图生成(比如机器人上的应用,判断某物体该不该出现在某处),能不能算一个小方向?

















 2293
2293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









