







文章信息
会议/期刊:2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE) —— CCF-A
团队:华中科技大学 Deqing Zou
分类:漏洞检测;CNN;Image
参考链接:
https://wu-yueming.github.io/
https://wu-yueming.github.io/Files/ICSE2022_VulCNN.pdf
https://github.com/CGCL-codes/VulCNN
Abstract
- 背景
- 深度学习可以自动从源代码中学习特征,因此,已经被广泛用于检测源代码的漏洞。
- 先前的一些方法直接将源代码视为text。为了实现准确性,其他方法将程序的语义信息表示成graph
- text-based的方法是scalable(可扩展)的,但由于缺乏语义而不准确
- graph-based的方法是accurate的,但not acalable,因为图分析通常time-consuming。
- 本文工作:
- 本文的目标是**在大规模源代码漏洞检测中实现both scalabitity and accuracy **
- 受现有基于深度学习的图像分类的启发,提出了一种可以有效地将函数源代码转换为图像的方法,同时保留程序的细节
- 实验结果:
- accuracy:VulCNN can achieve better accuracy than eight state-of-the-art vulnerability detectors (i.e., Checkmarx, FlawFinder, RATS, TokenCNN,VulDeePecker, SySeVR, VulDeeLocator, and Devign).
- scalability:VulCNN is about four times faster than VulDeePecker and SySeVR, about 15 times faster than VulDeeLocator, and about six times faster than Devign
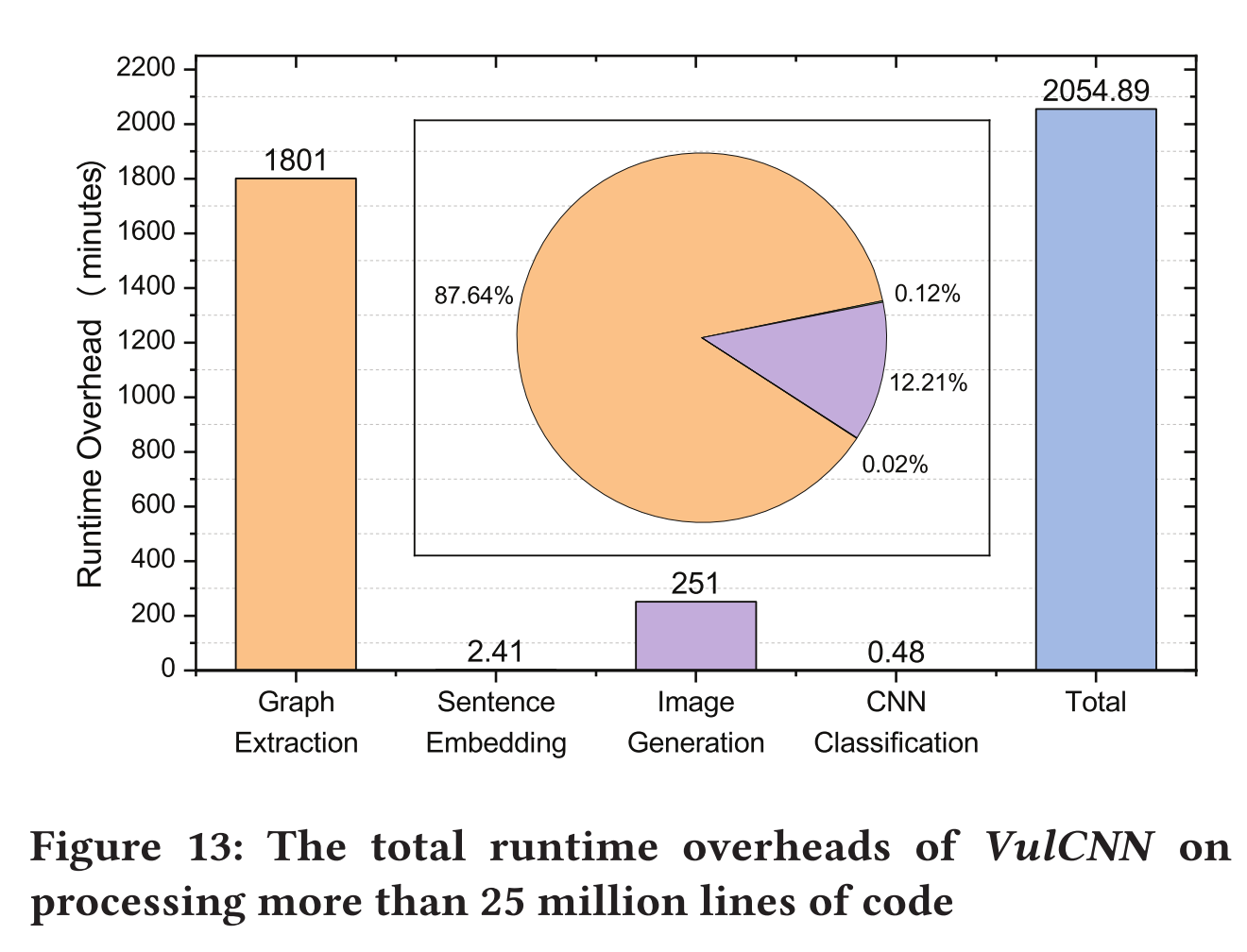
- 在25 million行的代码中进行案例分析,表明VulCNN可以检测大规模漏洞的能力
- 发现了未在NVD中报告的73个漏洞
1 Introduction
源代码漏洞检测的方法概述
-
基于代码相似性的方法 (code-similarity-based methods)
该方法主要用于检测代码克隆引起的漏洞,当检测不是由于代码克隆引起的漏洞时,会有很高的误报率
代码克隆(code clone):是指存在于代码库中两个及两个以上相同或相似的源代码片段
- 基于模式的方法 (pattern-based methods)
- 传统的基于模式的方法依赖人类专家手动定义漏洞规则或特征来描述漏洞,主观性强,费时费力,不准确
- 基于深度学习的方法,不需要人类专家手动定义规则,可以自动生成漏洞模式,目前被广泛应用在漏洞检测中
基于深度学习的方法存在的问题
- 之前的研究将源代码视为text,并使用NLP的技术来检测漏洞。但是这些text-based的方法忽略了源代码的程序语义,检测性能不理想
- 为了解决上述问题,一些研究利用程序分析,将源代码的程序语义表示为graph,然后进行graph analysis (e.g., graph neural network)。graph-based的方法在检测漏洞方法更有效。但是这些方法的可扩展性比text-based的方法差得多
- 此外,以上方法只关注于函数是否为漏洞,而不能精确指出那些代码行更易受攻击
本文贡献
- 高效地将函数的源代码转换为图像,同时保留程序细节
- 首先,进行程序分析,将函数的程序语义提取为程序依赖图(program dependency graph,PDG)
PDG是程序的一种graph representation,它包含源代码的数据流(data-flow)和控制流(control-flow)细节。PDG中的每个节点对应于函数中的一行代码
- 得到PDG后,将其视为社交网络,在网络上应用中心性分析,实现对图像的转换
- 应用的三个中心性:degree centrality;katz centrality;closeness centrality
- 使用三个中心性的原因:1. 不同的中心性可以从不同的方面保持图的属性;2. 图像有三个通道(channel),红绿蓝
- 设计并实现了一个VulCNN,一个可扩展的graph-based的漏洞检测系统
- 在数据集上的实验表明,VulCNN优于八种最先进的漏洞检测方法(Checkmarx, FlawFinder,RATS, TokenCNN, VulDeePecker, SySeVR, VulDeeLocator, and Devign)
- 对超过25 million行的代码进行案例分析,验证VulCNN在大规模漏洞扫描方面的能力。发现了73个NVD中未报告的漏洞
2 Motivation
如何找到函数中不同代码对程序语义的贡献?
以下面的代码为例进行说明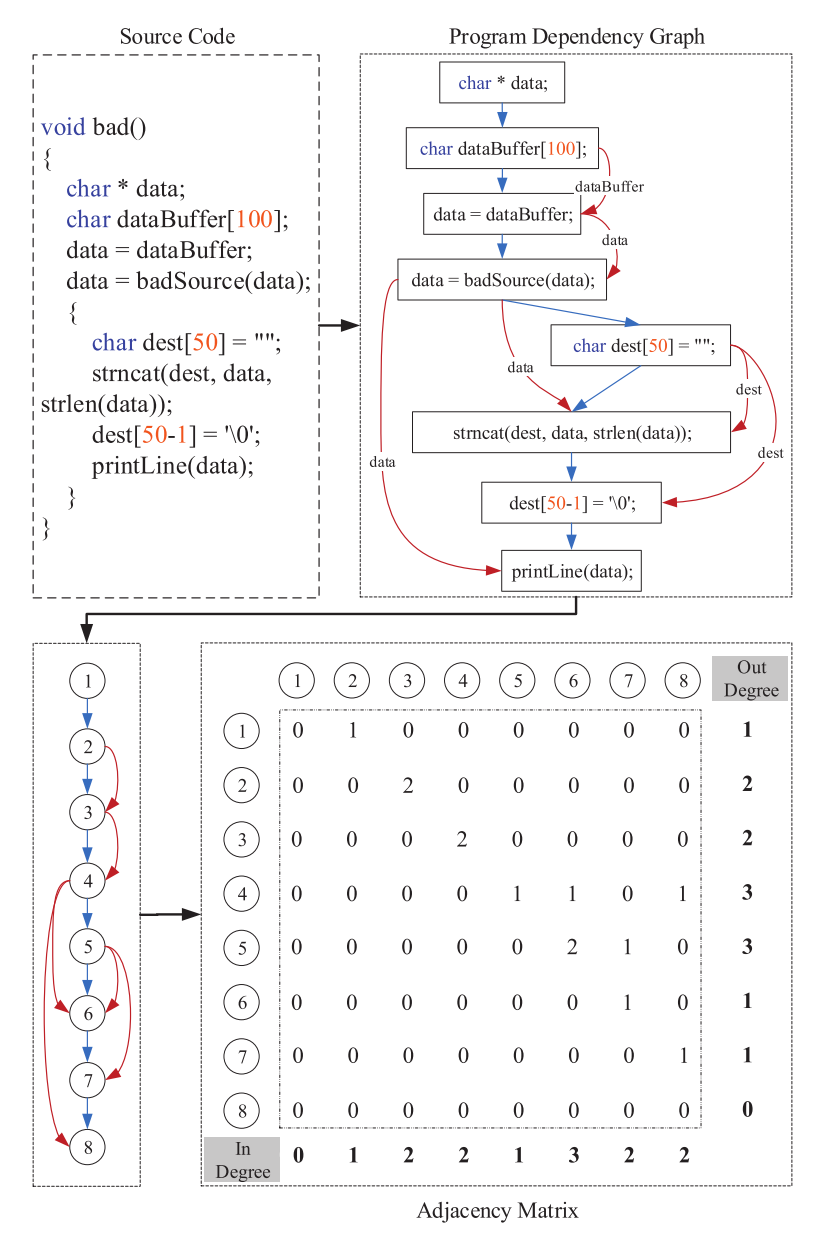
- 利用Joern来获得PDG
- PDG中的每个节点对应于漏洞程序中的一行代码
- 红线表示data-flow,蓝线表示control-flow
- 将每行代码替换为一个带编号的圆形节点,八行代码代码对应八个节点
- 计算相应的邻接矩阵(adjacency matrix)。adjacency matrix 的元素表示图中的节点对是否相邻,有向的
- adjacency matrix 中的一行求和是节点的出度(Out Degree),一列求和是节点的入度(In Degree)。
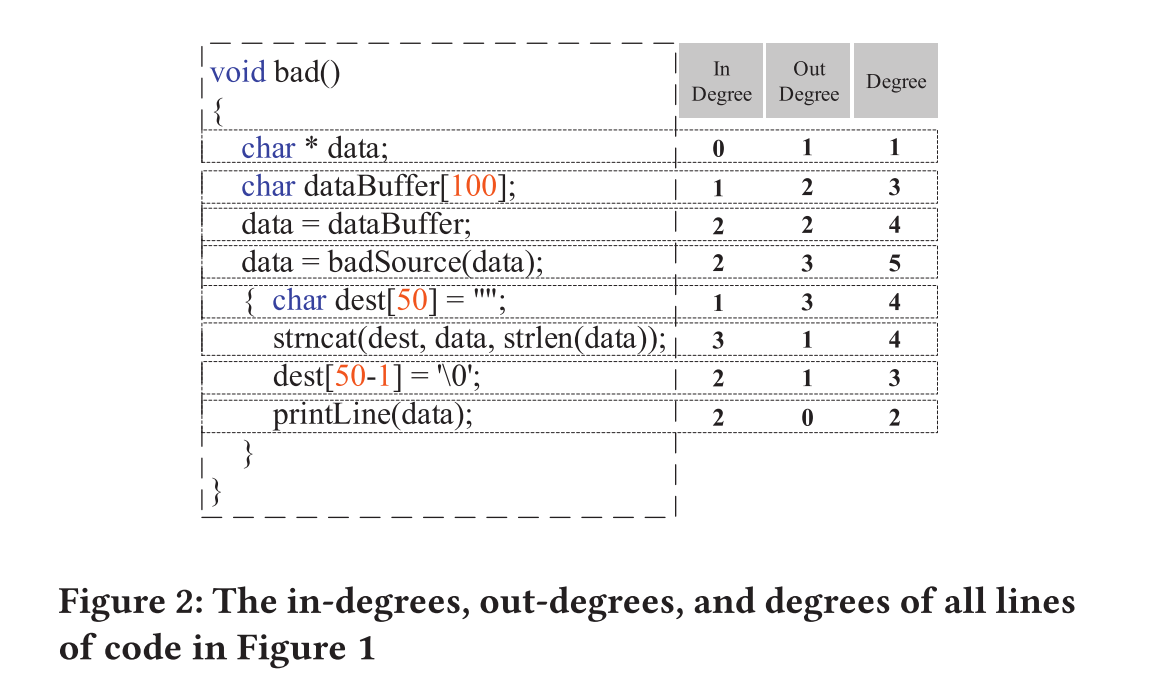
- 图2表明不同行代码的度(degree)是不同的,这是因为存在不同的关系(即控制流和数据流),漏洞是基于这些关系触发的(?)
- 如果直接将这些代码作为文本处理,则所有代码行的degree都是1,可能会降低漏洞检测的准确性
作者指出:
- 由于可以这样转换,graph ——>adjacency matrix——>degree,因此函数源代码的degree可能是保留graph细节的一个很好候选
- 在社交网络中,degree用于量化节点的重要性。The higher the degree, the more important the person
- 引入社交网络的思想,可以将每一行代码看作一个人,data-flow和control-flow看作人与人之间的通信,PDG看作一个社交网络
- 一行代码的degree越大,与它交流的人就越多,它在PDG社交网络中的重要性越大
- 将一行代码的重要性作为对程序语义的贡献。即一行代码越重要,它对实现程序语义的贡献就越大
3 System
3.1 overview

VulCNN的四个步骤:Graph Extraction;Sentence Embedding;Image Generation;Classification
3.2 Graph Extraction and Sentence Embedding
Graph Extraction
应用静态分析将源代码的程序语义提取到Graph表示
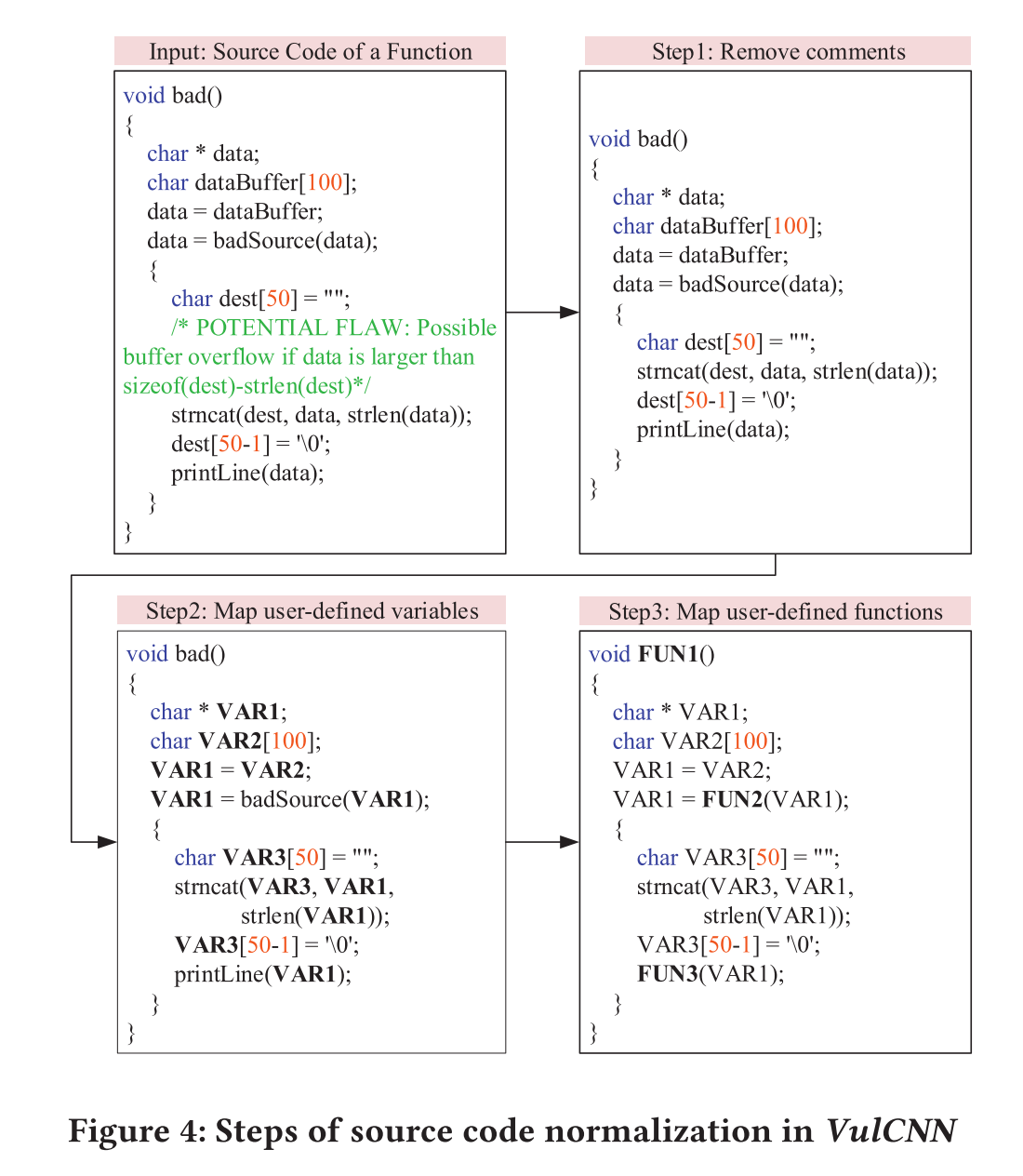
- 首先抽象和规范化源代码(图4)
- step 1:删除源代码中的注释,因为它们与程序语义无关
- step 2:以一对一的方式将用户定义的变量映射到符号名称(e.g., VAR1)
- step 3:以一对一的方式将用户定义的函数映射到符号名称(e.g., FUN1)
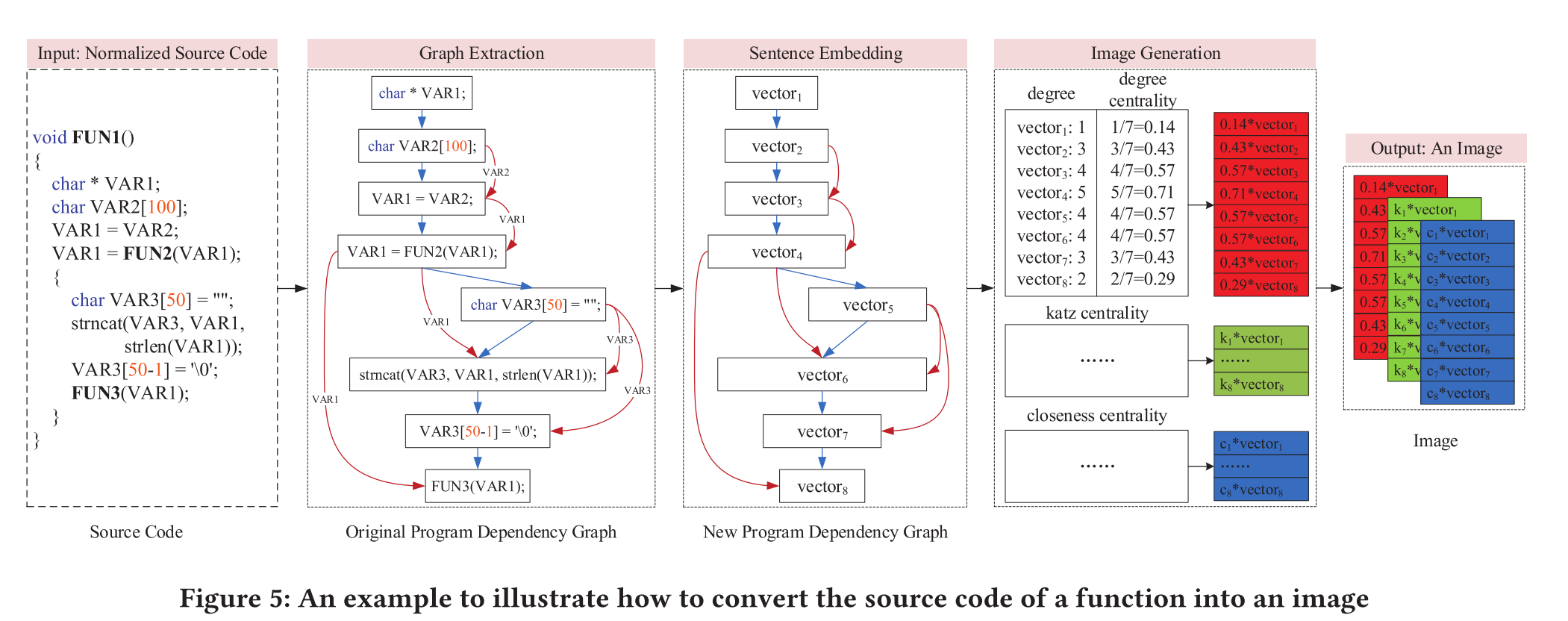
- 利用Joern来提取函数的PDG(图5 Graph Extraction)
Sentence Embedding
- 将一行代码视为一个句子
- 使用sent2vec完成句子到向量的转换(图5 Sentence Embedding)
- 向量维度为128
3.3 Image Generation
三个中心性(?)
Degree centrality:是它所连接的节点的分数。Degree centrality通过除以图中的最大可能度来归一化。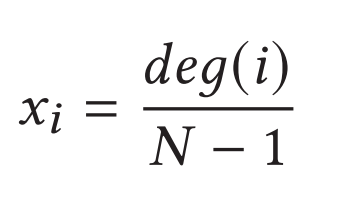
Katz centrality:基于其邻居的中心性计算节点的中心性。 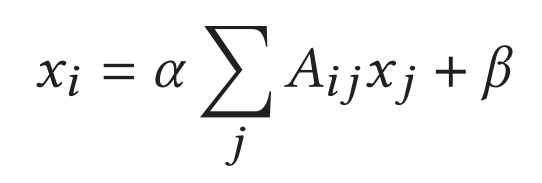
Closeness centrality:表示一个节点与网络中所有其他节点的接近程度。是节点到图中每个其他节点的最短路径长度的平均值。节点的平均最短距离越小,节点的closeness centrality越大 。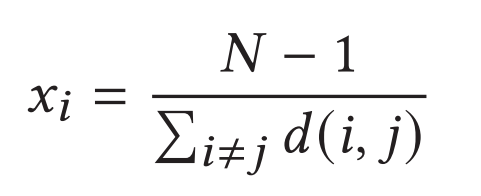
转换为图像

如算法1和图5所示:
- 首先,对PDG中的所有节点进行degree centrality分析。所有向量(sentence embedding的结果)乘以相应的degree centrality后根据代码行数逐个排列,作为图像的degree channel
- 同理,对PDG进行katz centrality和closeness centrality分析,可以得到图像的另外两个通道,katz channel和closeness channel
- 最后,这三个通道用于生成图像
3.4 Classification
background:在图像处理领域,卷积神经网络(CNN)一直是焦点,因为它不仅不需要手动预处理图像,而且还可以利用其独特的细粒度特征提取达到接近人类的水平。
不同函数中的代码行数不同,而CNN需要相同大小的图像作为输入。因此,需要确定一个阈值来将图像大小固定。图6显示了函数中代码行数的累积分布情况,可以看出超过99%的函数代码在200行以下。作者选择100行作为阈值(在4.2说明)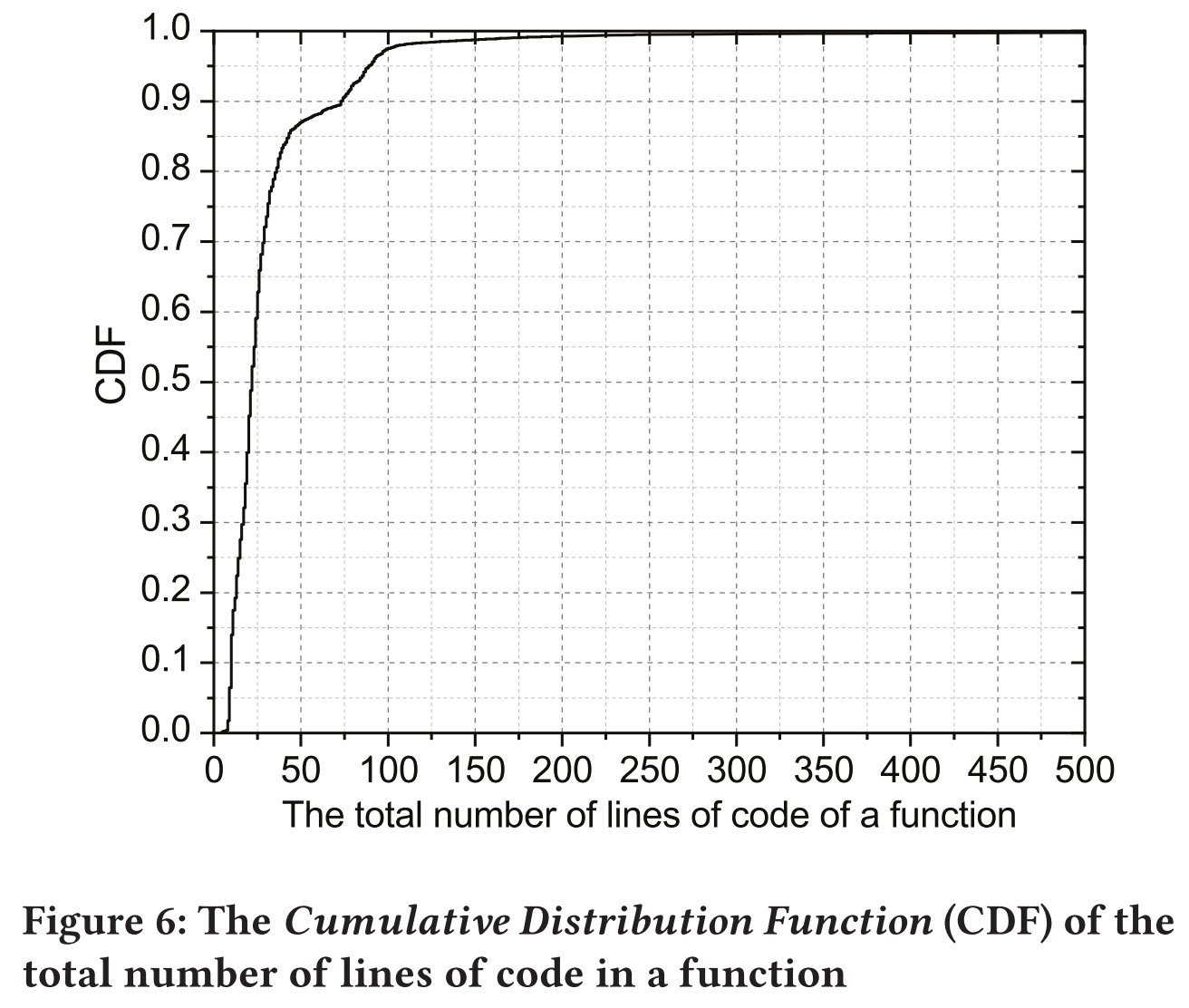
- 当函数中代码行数小于100时,将0填充到向量的末尾
- 当函数中代码行数超过100时,删除向量的末尾部分
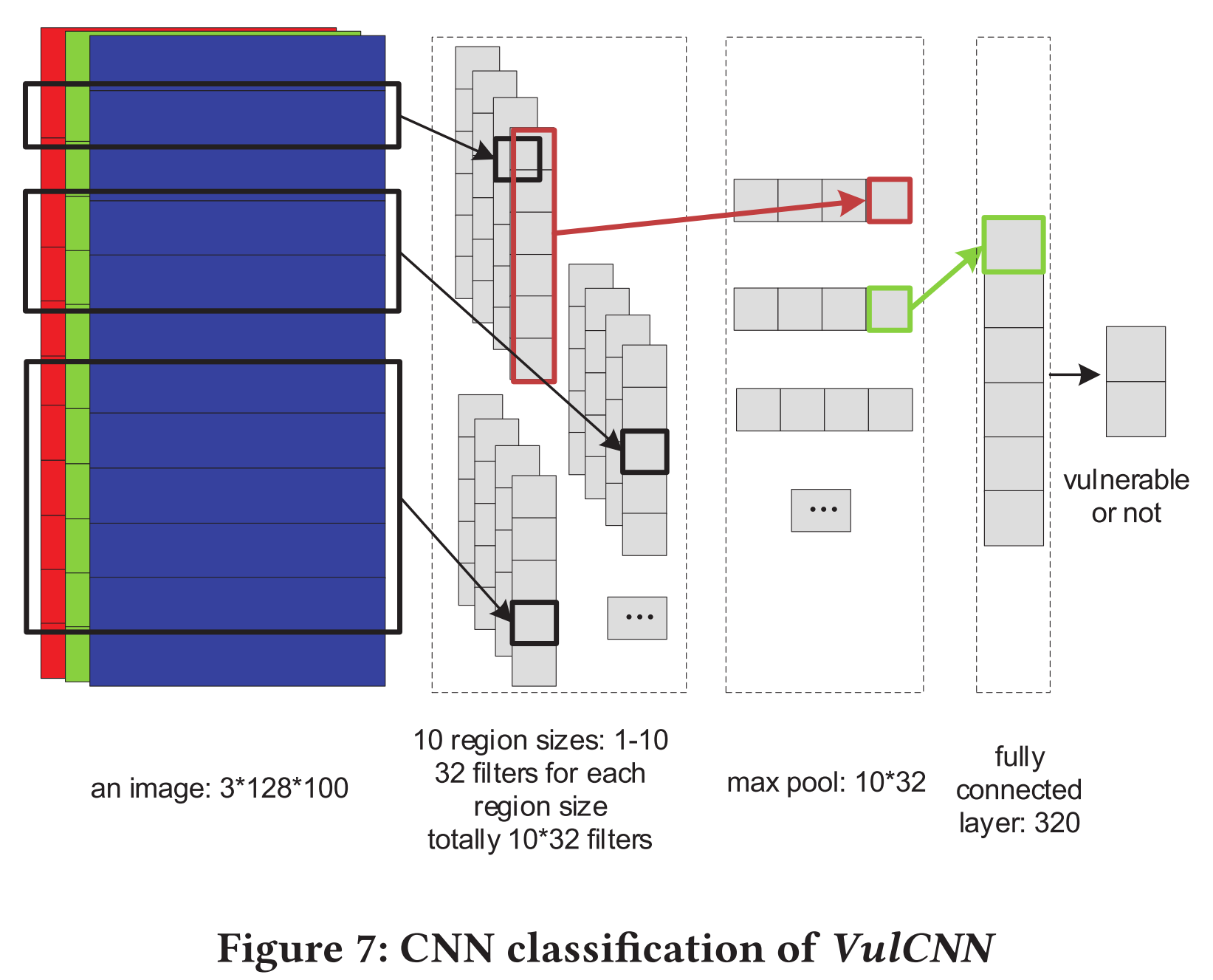
图7展示了CNN模型:
- 输入的图像为3128100(3通道,128表示句子的维度,100表示代码行的阈值)
- 卷积核的大小为m*128,其中m表示连续句子一起考虑的数量
- 在VulCNN中,m取1-10
- 每个尺寸都有32个feature maps来提取图像不同的特征
- 最大池化层
- 全连接层
VulCNN中使用的参数描述如表1所示: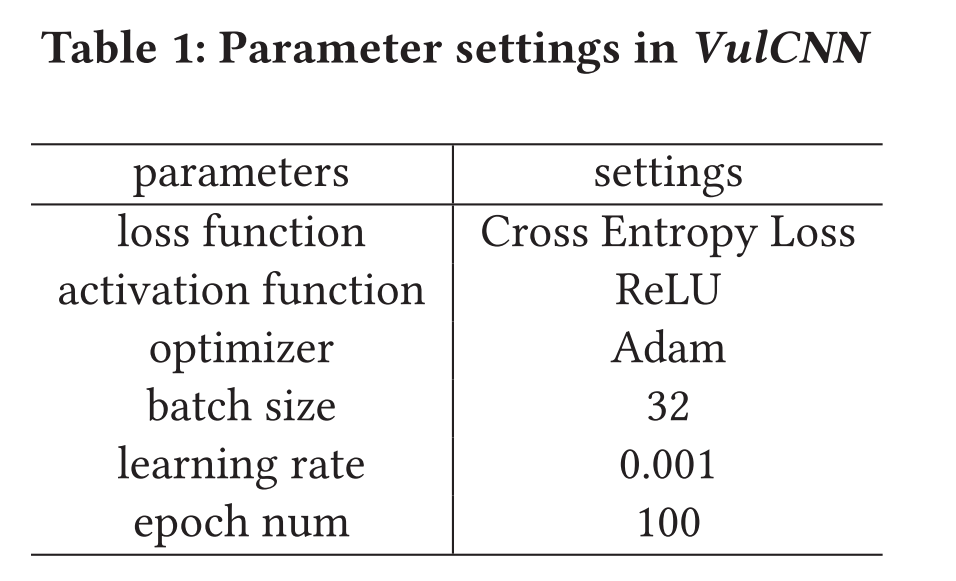
图10展示使用Grad-CAM++来可视化易受攻击的代码行。Grad-CAM++是一种分类判别定位技术,可以为任何基于CNN的网络生成可视化解释,而无需更改架构或重新训练。根据热图中颜色的强度,我们可以知道哪些代码行可能更容易受到攻击。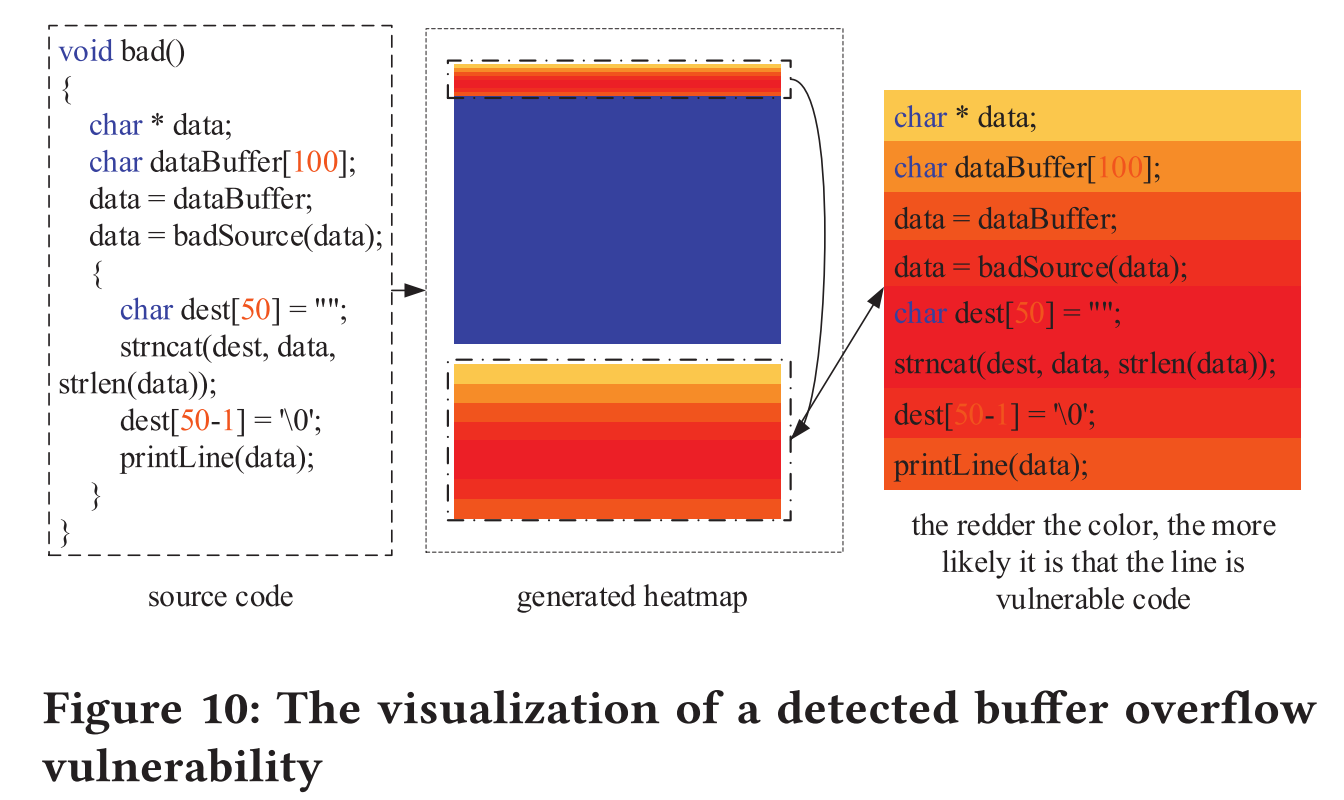
4 Experiments
在本节,旨在回答以下问题:
- VulCNN在检测源代码漏洞时的检测性能如何?
- VulCNN在检测源代码漏洞时的运行时开销是多少?
- VulCNN能否实现大规模漏洞扫描?
4.1 Experiment Settings
数据集
- SARD(合成程序)中的C/C++函数。
- NVD(真实世界的程序)中的C/C++函数。
- 最终数据集包括13,687vulnerable functions和26,970 non-vulnerable functions
- 训练:验证:测试 7:2:1
使用的包
- graph extraction:Joern
- sentence embedding:sent2vec
- image generation:networkx
- classification:pytorch
显卡:1080Ti
4.2 Detection Performance
图8实验了代码行数的不同阈值来检测漏洞
- 阈值越大,精度越高
- 当阈值达到100行时,精度的增长变小
- 阈值越大,图像越大,所需的内存越多
- 综合考虑检测精度和运行时间,最终选择100行
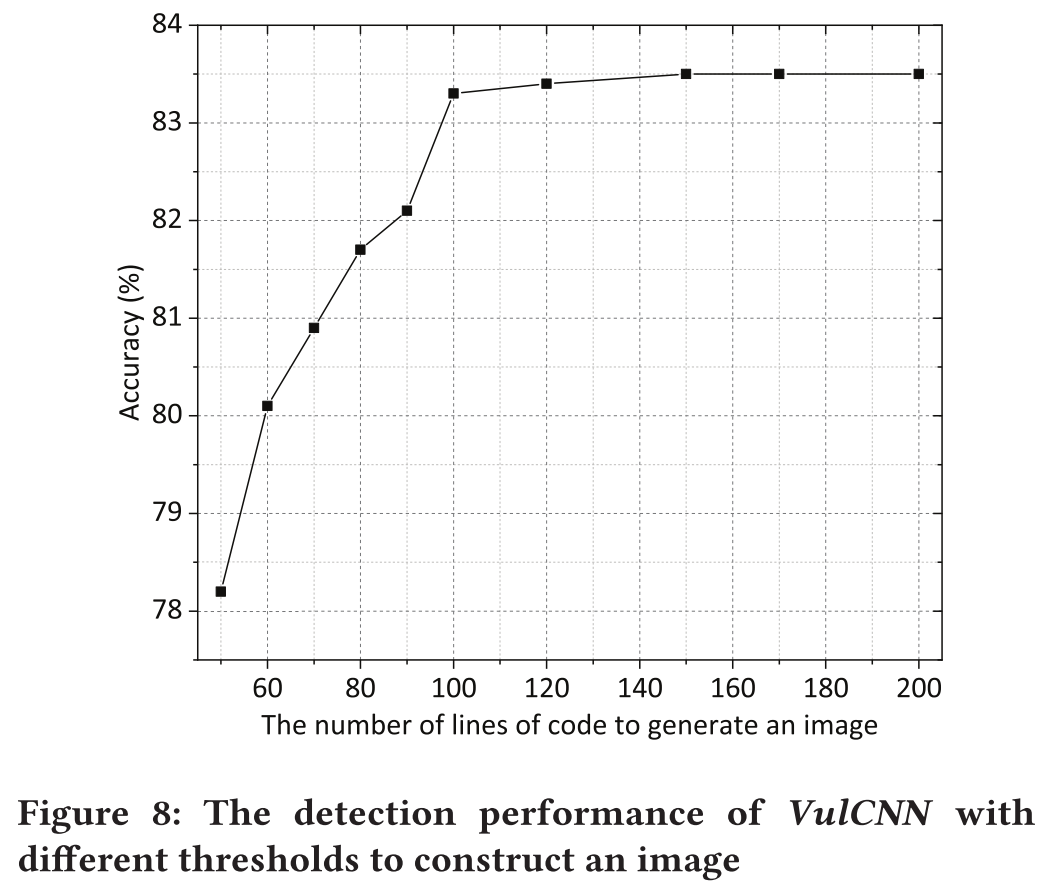
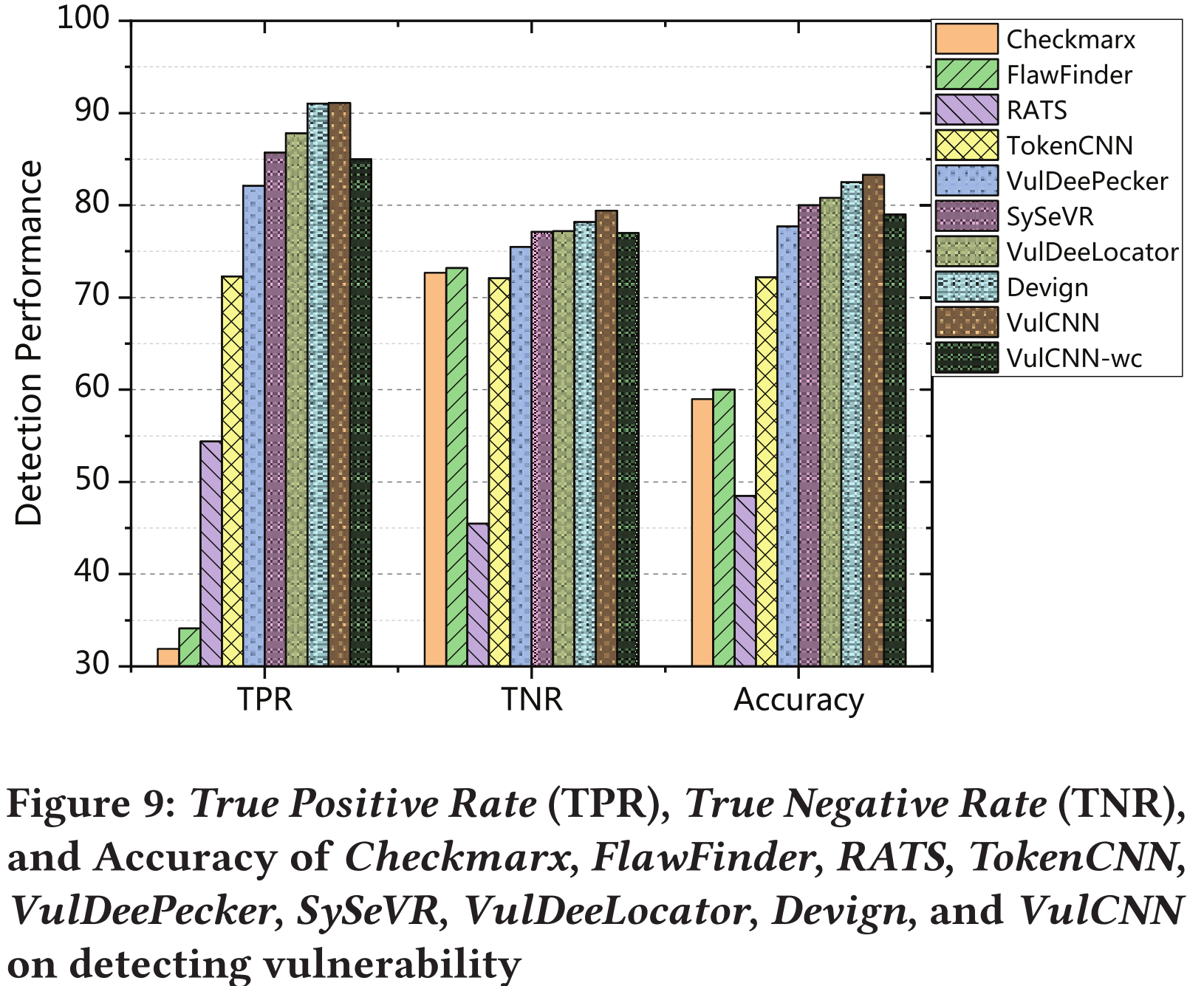
图9对比试验:
包括一种商业静态漏洞检测工具(即,Checkmarx [5]),两个开源静态分析工具(即,Flawfall [6]和RATS [12]),以及五种基于深度学习的漏洞检测方法(即,TokenCNN3 [47],VulDeePecker [41],SySeVR [40],VulDeePecker [38]和Devign [56])
- TokenCNN:首先进行词法分析,将源代码转换为token序列,然后将它们嵌入到固定长度的向量表示中。最后,将这些向量输入到CNN模型中,来训练漏洞检测器
- VulDeePecker&SySeVR:通过对程序进行切片来收集 code gadget,然后将其转换为相应的向量表示。最后,用这些向量训练一个双向递归神经网络(BRNN)来检测漏洞。
- 其中VulDeepecker只对程序切片进行data-flow分析,而SySeVR同时考虑control-flow和data-flow。
- 由于SySeVR包含了更多的语义信息,所以比VulDeePecker性能好
- 但他们没有考虑不同代码行对程序语义的不同贡献,而是将切片中的代码视为文本,直接用BRNN来训练漏洞
- VulDeeLocator:将程序编译为LLVM位代码文件,然后提取中间表示(Intermediate Representation,IR)切片以保留程序语义。最后,用这些IR切片训练BRNN模型来检测漏洞。
- Devign:首先应用复杂程序分析来提取包含全面程序语义的图表示,然后输入图神经网络来检测漏洞。
- Devign的检测性能与VulCNN几乎相同,但是,由于生成的图的复杂性,它不能扩展到大规模的漏洞扫描。但VulCNN可以,因为它使用中心性分析将time-consuming的graphic analysics转化为image scanning
- VulCNN-wc:VulCNN不带中心性。在sentence embedding之后,直接将句子向量输入到CNN模型来训练分类器,不乘以中心度
- 从图9可以看出,考虑函数中不同代码行的中心性,可以提高检测精度
- 从图9可以看出,考虑函数中不同代码行的中心性,可以提高检测精度
4.3 Runtime Overhead
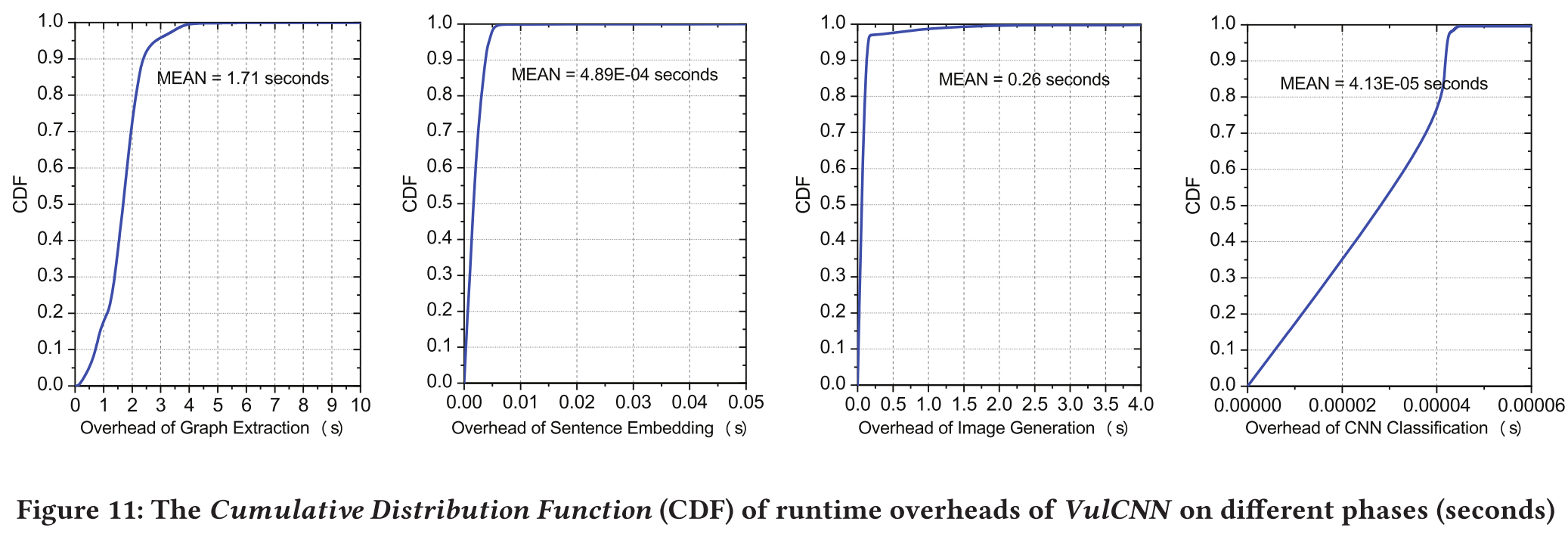
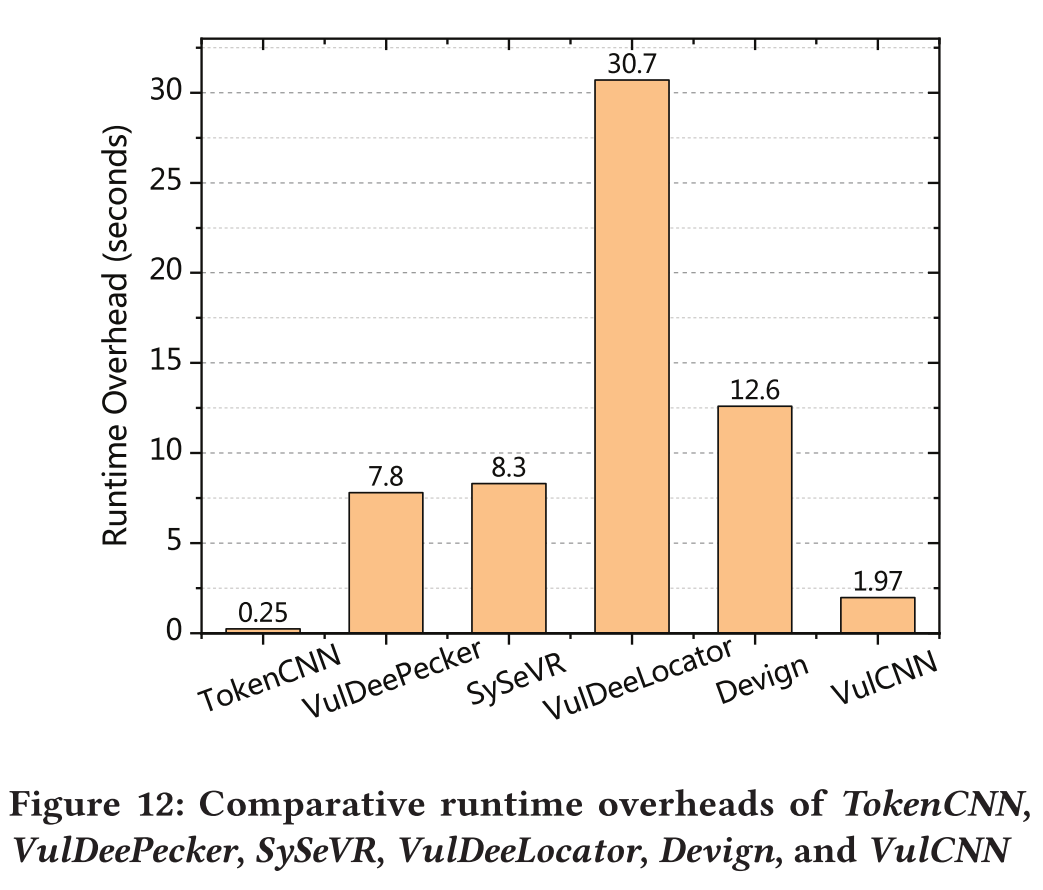
4.4 Case Study
5 Discussion
5.1 Threats to Valiidity
5.2 Discussion
对比方法的选择
- TokenCNN:one token-based
- VulDeepecker:one slice-based tool
- VulDeeLocator:one bitcode-based
- Devign:one graph-based
中心性与图像颜色通道的关系
构造图像的目的是便于使用基于图像的模型(即,CNN)进行漏洞检测,同时保留程序细节。因此,我们的函数图像有三层(与常规图像相同的格式),但在常规图像中的三种颜色和函数图像中的三种中心性度量之间没有严格的对应关系。
未来工作
- 设计一个新的静态分析工具,或尝试其他静态分析工具,以实现更有效的PDG生成、
- 采用不同的中心性来保留graph的细节。使用不同中心性的组合来找到合适的组合
- VulCNN的TNR不理想,检测到的一些漏洞可能是误报
6 Related work
基于代码相似性
对于基于相似性的方法,可以从不同的方面来测量相似性,例如基于字符串[27,32],基于树[29,46],基于标记[30,48],基于图[37]以及它们的混合[39]。但是,它们只能检测克隆的漏洞,并且不能检测新的漏洞[41]。为了应对这一挑战,设计了基于模式的技术。
基于模式
根据自动化程度,基于模式的工作可以分为三个子类别。
- 手动方法:人类专家手动生成漏洞模式,并使用它们来检测新的漏洞。在实践中,这些工具的检测有效性(例如,Checkmarx [5]、Flawmarty [6]和RATS [12])的性能很差,因为专家无法生成不同漏洞的所有模式。图9中的结果也证明了这种情况。
- 半自动方法[18,50,51,55]:人类专家首先提取某些特征(例如,子树和API符号[54],导入和函数调用[44]),然后将它们馈送到传统的机器学习模型(例如,支持向量机和k-最近邻)来检测漏洞。
- 更自动化的方法(即,基于深度学习的方法):由于深度学习可以自动从源代码中提取特征,因此它已被用于检测源代码漏洞[22,24,40,41,43,47,56,57]。
例如,VulDeePecker [41]首先通过切片程序收集代码小工具,然后将它们转换为相应的向量表示。最后,它使用这些向量来训练双向长短期记忆(BLSTM)模型来检测漏洞。muVulDeePecker [57]使用VulDeePecker [41]中的程序处理方法,并添加了代码注意以检测多类漏洞。Devign [56]应用一般的图神经网络来检测漏洞。它包含一个新的卷积模块,可以有效地从学习的富节点表示中提取有用的特征,用于图级分类。DeepWukong [22]将程序语义提炼为程序依赖图,并根据程序兴趣点将其拆分为多个子图。然后将这些子图输入到图神经网络中训练漏洞检测器。
7 Conclusion
在本文中,我们提出了一个新的想法,可以有效地将一个函数的源代码转换成图像,同时保持程序的语义。由此,我们设计了一个可扩展的基于图的漏洞检测系统(即,VulCNN)。对13,687个脆弱函数和26,970个非脆弱函数的数据集的评估结果表明,VulCNN上级8个最先进的脆弱性检测器(即,[5],[6],[12],[14],[15],[16],[17],[18],[19],[1为了验证VulCNN在大规模漏洞扫描方面的能力,我们对超过2500万行代码进行了案例研究。通过扫描结果,我们发现了73个未在NVD中报告的漏洞。我们已经向他们的供应商报告了这些问题,希望他们能尽快修复。














 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









